 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMod-Guide: An LLM-based Content Moderation Feedback System to Address Insensitive Speech toward Indigenous Ethnic and Religious Minority Communities
Jun 11, 2026Language operates as a mechanism of both marginalization and resistance, especially for minority communities navigating insensitive and harmful speech online. As content moderation increasingly depends on large language models (LLMs), concerns arise about whether these systems can recognize culturally insensitive speech-language that disregards or marginalizes the cultural and religious perspectives of historically underrepresented communities, often through implicit erasure, misrepresentation, or normative framing, rather than overt hostility. Focusing on Bangladesh's Hindu and Chakma communities -- the country's largest religious and Indigenous ethnic minorities, respectively -- this paper investigates the epistemic limits of LLM-based moderation systems and explores methods for incorporating minority perspectives. We co-created a culturally grounded corpus of insensitive speech with community members and integrated their narratives into moderation pipelines using retrieval augmented generation (RAG). Our tool, Mod-Guide, improves LLM sensitivity to minority viewpoints by leveraging contextual cues derived from lived experience. Through mixed-method evaluations involving both minority and majority participants, we demonstrate that RAG-enhanced moderation responses are more contextually accurate and perceived differently across ethnic lines. This work advances research in human-computer interaction, AI ethics, and social computing by foregrounding restorative justice and hermeneutical inclusion in the design of content moderation systems.
Benchmarking LLMs for Pairwise Causal Discovery in Biomedical and Multi-Domain Contexts
Jan 21, 2026The safe deployment of large language models (LLMs) in high-stakes fields like biomedicine, requires them to be able to reason about cause and effect. We investigate this ability by testing 13 open-source LLMs on a fundamental task: pairwise causal discovery (PCD) from text. Our benchmark, using 12 diverse datasets, evaluates two core skills: 1) \textbf{Causal Detection} (identifying if a text contains a causal link) and 2) \textbf{Causal Extraction} (pulling out the exact cause and effect phrases). We tested various prompting methods, from simple instructions (zero-shot) to more complex strategies like Chain-of-Thought (CoT) and Few-shot In-Context Learning (FICL). The results show major deficiencies in current models. The best model for detection, DeepSeek-R1-Distill-Llama-70B, only achieved a mean score of 49.57\% ($C_{detect}$), while the best for extraction, Qwen2.5-Coder-32B-Instruct, reached just 47.12\% ($C_{extract}$). Models performed best on simple, explicit, single-sentence relations. However, performance plummeted for more difficult (and realistic) cases, such as implicit relationships, links spanning multiple sentences, and texts containing multiple causal pairs. We provide a unified evaluation framework, built on a dataset validated with high inter-annotator agreement ($κ\ge 0.758$), and make all our data, code, and prompts publicly available to spur further research. \href{https://github.com/sydneyanuyah/CausalDiscovery}{Code available here: https://github.com/sydneyanuyah/CausalDiscovery}
Domain-Specific Knowledge Graphs in RAG-Enhanced Healthcare LLMs
Jan 21, 2026Large Language Models (LLMs) generate fluent answers but can struggle with trustworthy, domain-specific reasoning. We evaluate whether domain knowledge graphs (KGs) improve Retrieval-Augmented Generation (RAG) for healthcare by constructing three PubMed-derived graphs: $\mathbb{G}_1$ (T2DM), $\mathbb{G}_2$ (Alzheimer's disease), and $\mathbb{G}_3$ (AD+T2DM). We design two probes: Probe 1 targets merged AD T2DM knowledge, while Probe 2 targets the intersection of $\mathbb{G}_1$ and $\mathbb{G}_2$. Seven instruction-tuned LLMs are tested across retrieval sources {No-RAG, $\mathbb{G}_1$, $\mathbb{G}_2$, $\mathbb{G}_1$ + $\mathbb{G}_2$, $\mathbb{G}_3$, $\mathbb{G}_1$+$\mathbb{G}_2$ + $\mathbb{G}_3$} and three decoding temperatures. Results show that scope alignment between probe and KG is decisive: precise, scope-matched retrieval (notably $\mathbb{G}_2$) yields the most consistent gains, whereas indiscriminate graph unions often introduce distractors that reduce accuracy. Larger models frequently match or exceed KG-RAG with a No-RAG baseline on Probe 1, indicating strong parametric priors, whereas smaller/mid-sized models benefit more from well-scoped retrieval. Temperature plays a secondary role; higher values rarely help. We conclude that precision-first, scope-matched KG-RAG is preferable to breadth-first unions, and we outline practical guidelines for graph selection, model sizing, and retrieval/reranking. Code and Data available here - https://github.com/sydneyanuyah/RAGComparison
A Cost-Effective LLM-based Approach to Identify Wildlife Trafficking in Online Marketplaces
Apr 29, 2025



Wildlife trafficking remains a critical global issue, significantly impacting biodiversity, ecological stability, and public health. Despite efforts to combat this illicit trade, the rise of e-commerce platforms has made it easier to sell wildlife products, putting new pressure on wild populations of endangered and threatened species. The use of these platforms also opens a new opportunity: as criminals sell wildlife products online, they leave digital traces of their activity that can provide insights into trafficking activities as well as how they can be disrupted. The challenge lies in finding these traces. Online marketplaces publish ads for a plethora of products, and identifying ads for wildlife-related products is like finding a needle in a haystack. Learning classifiers can automate ad identification, but creating them requires costly, time-consuming data labeling that hinders support for diverse ads and research questions. This paper addresses a critical challenge in the data science pipeline for wildlife trafficking analytics: generating quality labeled data for classifiers that select relevant data. While large language models (LLMs) can directly label advertisements, doing so at scale is prohibitively expensive. We propose a cost-effective strategy that leverages LLMs to generate pseudo labels for a small sample of the data and uses these labels to create specialized classification models. Our novel method automatically gathers diverse and representative samples to be labeled while minimizing the labeling costs. Our experimental evaluation shows that our classifiers achieve up to 95% F1 score, outperforming LLMs at a lower cost. We present real use cases that demonstrate the effectiveness of our approach in enabling analyses of different aspects of wildlife trafficking.
An Empirical Study of Causal Relation Extraction Transfer: Design and Data
Mar 08, 2025



We conduct an empirical analysis of neural network architectures and data transfer strategies for causal relation extraction. By conducting experiments with various contextual embedding layers and architectural components, we show that a relatively straightforward BioBERT-BiGRU relation extraction model generalizes better than other architectures across varying web-based sources and annotation strategies. Furthermore, we introduce a metric for evaluating transfer performance, $F1_{phrase}$ that emphasizes noun phrase localization rather than directly matching target tags. Using this metric, we can conduct data transfer experiments, ultimately revealing that augmentation with data with varying domains and annotation styles can improve performance. Data augmentation is especially beneficial when an adequate proportion of implicitly and explicitly causal sentences are included.
A Flexible and Scalable Approach for Collecting Wildlife Advertisements on the Web
Jul 26, 2024



Wildlife traffickers are increasingly carrying out their activities in cyberspace. As they advertise and sell wildlife products in online marketplaces, they leave digital traces of their activity. This creates a new opportunity: by analyzing these traces, we can obtain insights into how trafficking networks work as well as how they can be disrupted. However, collecting such information is difficult. Online marketplaces sell a very large number of products and identifying ads that actually involve wildlife is a complex task that is hard to automate. Furthermore, given that the volume of data is staggering, we need scalable mechanisms to acquire, filter, and store the ads, as well as to make them available for analysis. In this paper, we present a new approach to collect wildlife trafficking data at scale. We propose a data collection pipeline that combines scoped crawlers for data discovery and acquisition with foundational models and machine learning classifiers to identify relevant ads. We describe a dataset we created using this pipeline which is, to the best of our knowledge, the largest of its kind: it contains almost a million ads obtained from 41 marketplaces, covering 235 species and 20 languages. The source code is publicly available at \url{https://github.com/VIDA-NYU/wildlife_pipeline}.
Creolizing the Web
Feb 24, 2021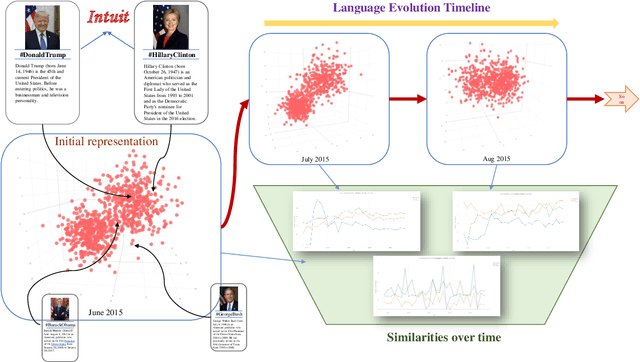

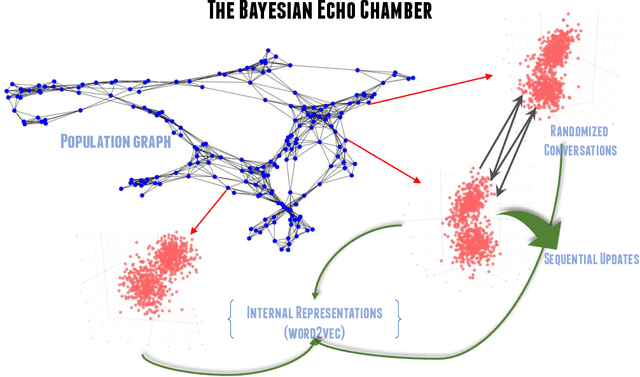
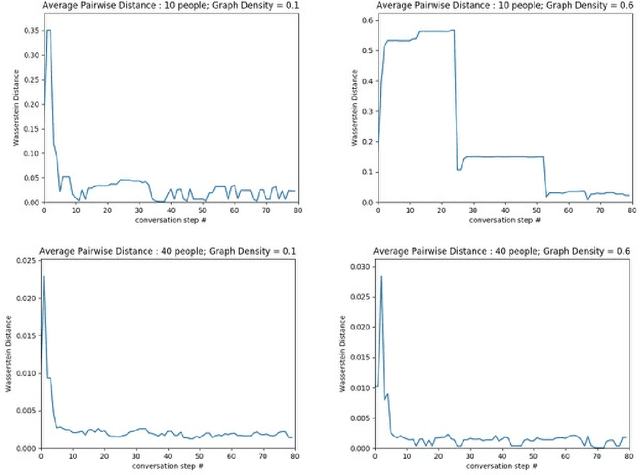
The evolution of language has been a hotly debated subject with contradicting hypotheses and unreliable claims. Drawing from signalling games, dynamic population mechanics, machine learning and algebraic topology, we present a method for detecting evolutionary patterns in a sociological model of language evolution. We develop a minimalistic model that provides a rigorous base for any generalized evolutionary model for language based on communication between individuals. We also discuss theoretical guarantees of this model, ranging from stability of language representations to fast convergence of language by temporal communication and language drift in an interactive setting. Further we present empirical results and their interpretations on a real world dataset from \rdt to identify communities and echo chambers for opinions, thus placing obstructions to reliable communication among communities.