 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust sensor fusion against on-vehicle sensor staleness
Jun 06, 2025Sensor fusion is crucial for a performant and robust Perception system in autonomous vehicles, but sensor staleness, where data from different sensors arrives with varying delays, poses significant challenges. Temporal misalignment between sensor modalities leads to inconsistent object state estimates, severely degrading the quality of trajectory predictions that are critical for safety. We present a novel and model-agnostic approach to address this problem via (1) a per-point timestamp offset feature (for LiDAR and radar both relative to camera) that enables fine-grained temporal awareness in sensor fusion, and (2) a data augmentation strategy that simulates realistic sensor staleness patterns observed in deployed vehicles. Our method is integrated into a perspective-view detection model that consumes sensor data from multiple LiDARs, radars and cameras. We demonstrate that while a conventional model shows significant regressions when one sensor modality is stale, our approach reaches consistently good performance across both synchronized and stale conditions.
SNN: Stacked Neural Networks
May 27, 2016
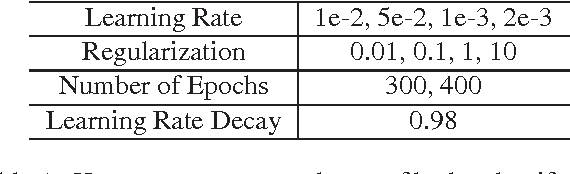


It has been proven that transfer learning provides an easy way to achieve state-of-the-art accuracies on several vision tasks by training a simple classifier on top of features obtained from pre-trained neural networks. The goal of this work is to generate better features for transfer learning from multiple publicly available pre-trained neural networks. To this end, we propose a novel architecture called Stacked Neural Networks which leverages the fast training time of transfer learning while simultaneously being much more accurate. We show that using a stacked NN architecture can result in up to 8% improvements in accuracy over state-of-the-art techniques using only one pre-trained network for transfer learning. A second aim of this work is to make network fine- tuning retain the generalizability of the base network to unseen tasks. To this end, we propose a new technique called "joint fine-tuning" that is able to give accuracies comparable to finetuning the same network individually over two datasets. We also show that a jointly finetuned network generalizes better to unseen tasks when compared to a network finetuned over a single task.