 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchemaGraphSQL: Efficient Schema Linking with Pathfinding Graph Algorithms for Text-to-SQL on Large-Scale Databases
May 23, 2025



Text-to-SQL systems translate natural language questions into executable SQL queries, and recent progress with large language models (LLMs) has driven substantial improvements in this task. Schema linking remains a critical component in Text-to-SQL systems, reducing prompt size for models with narrow context windows and sharpening model focus even when the entire schema fits. We present a zero-shot, training-free schema linking approach that first constructs a schema graph based on foreign key relations, then uses a single prompt to Gemini 2.5 Flash to extract source and destination tables from the user query, followed by applying classical path-finding algorithms and post-processing to identify the optimal sequence of tables and columns that should be joined, enabling the LLM to generate more accurate SQL queries. Despite being simple, cost-effective, and highly scalable, our method achieves state-of-the-art results on the BIRD benchmark, outperforming previous specialized, fine-tuned, and complex multi-step LLM-based approaches. We conduct detailed ablation studies to examine the precision-recall trade-off in our framework. Additionally, we evaluate the execution accuracy of our schema filtering method compared to other approaches across various model sizes.
PerMedCQA: Benchmarking Large Language Models on Medical Consumer Question Answering in Persian Language
May 23, 2025Medical consumer question answering (CQA) is crucial for empowering patients by providing personalized and reliable health information. Despite recent advances in large language models (LLMs) for medical QA, consumer-oriented and multilingual resources, particularly in low-resource languages like Persian, remain sparse. To bridge this gap, we present PerMedCQA, the first Persian-language benchmark for evaluating LLMs on real-world, consumer-generated medical questions. Curated from a large medical QA forum, PerMedCQA contains 68,138 question-answer pairs, refined through careful data cleaning from an initial set of 87,780 raw entries. We evaluate several state-of-the-art multilingual and instruction-tuned LLMs, utilizing MedJudge, a novel rubric-based evaluation framework driven by an LLM grader, validated against expert human annotators. Our results highlight key challenges in multilingual medical QA and provide valuable insights for developing more accurate and context-aware medical assistance systems. The data is publicly available on https://huggingface.co/datasets/NaghmehAI/PerMedCQA
SNN: Stacked Neural Networks
May 27, 2016
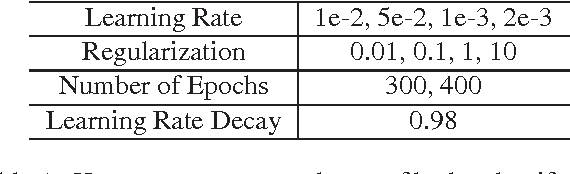


It has been proven that transfer learning provides an easy way to achieve state-of-the-art accuracies on several vision tasks by training a simple classifier on top of features obtained from pre-trained neural networks. The goal of this work is to generate better features for transfer learning from multiple publicly available pre-trained neural networks. To this end, we propose a novel architecture called Stacked Neural Networks which leverages the fast training time of transfer learning while simultaneously being much more accurate. We show that using a stacked NN architecture can result in up to 8% improvements in accuracy over state-of-the-art techniques using only one pre-trained network for transfer learning. A second aim of this work is to make network fine- tuning retain the generalizability of the base network to unseen tasks. To this end, we propose a new technique called "joint fine-tuning" that is able to give accuracies comparable to finetuning the same network individually over two datasets. We also show that a jointly finetuned network generalizes better to unseen tasks when compared to a network finetuned over a single task.