 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Data-to-Document Generation
Jul 25, 2017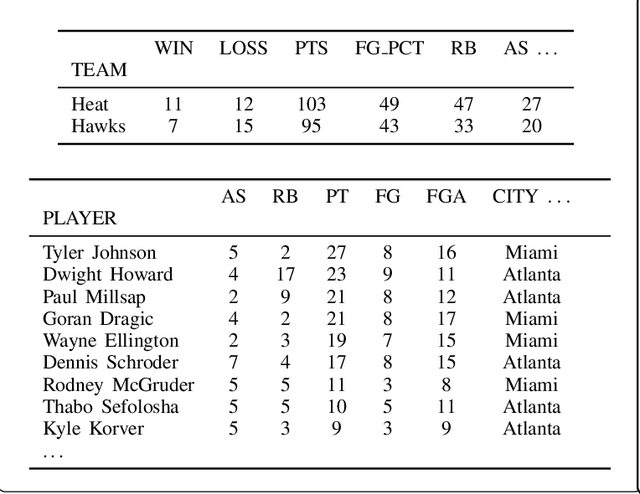
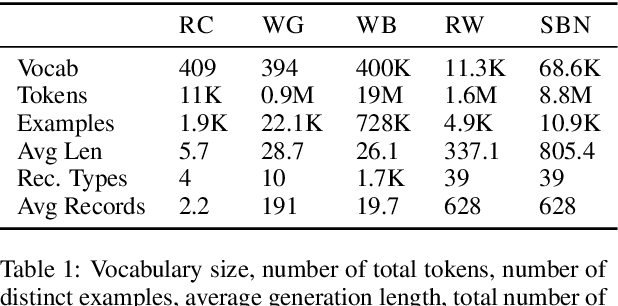

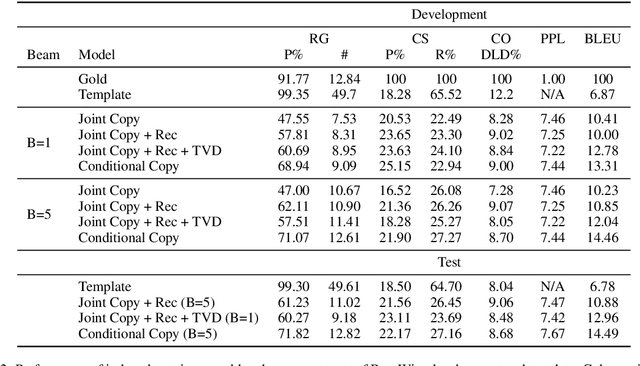
Recent neural models have shown significant progress on the problem of generating short descriptive texts conditioned on a small number of database records. In this work, we suggest a slightly more difficult data-to-text generation task, and investigate how effective current approaches are on this task. In particular, we introduce a new, large-scale corpus of data records paired with descriptive documents, propose a series of extractive evaluation methods for analyzing performance, and obtain baseline results using current neural generation methods. Experiments show that these models produce fluent text, but fail to convincingly approximate human-generated documents. Moreover, even templated baselines exceed the performance of these neural models on some metrics, though copy- and reconstruction-based extensions lead to noticeable improvements.
Word Ordering Without Syntax
Sep 24, 2016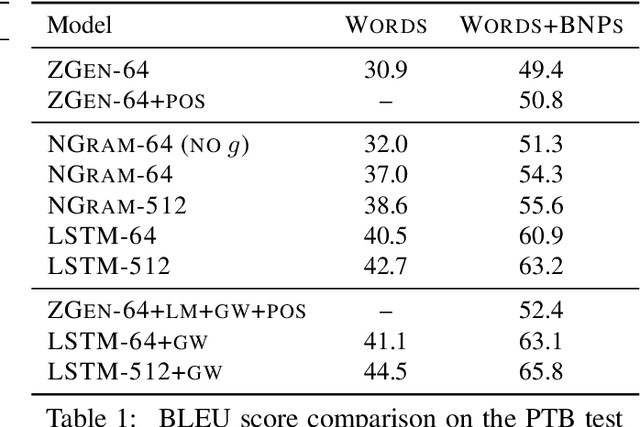
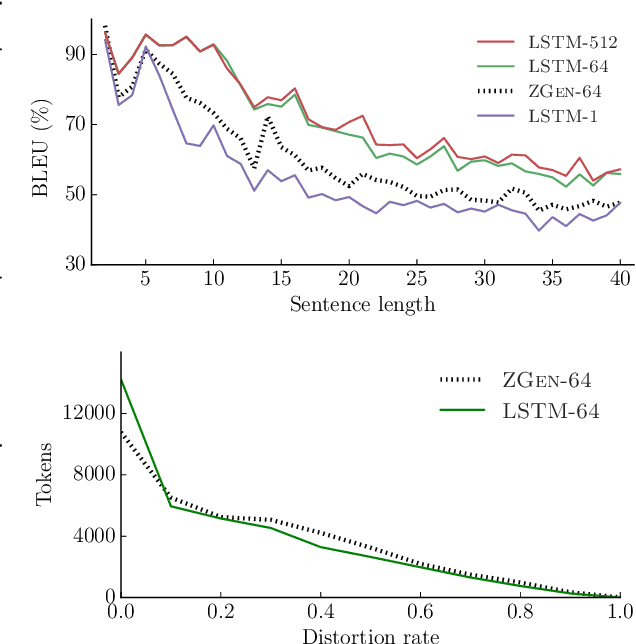
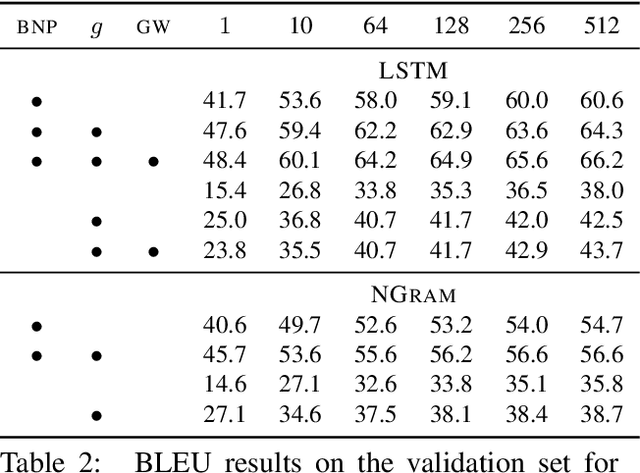
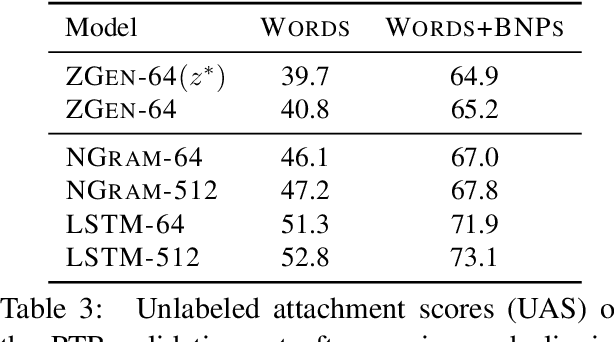
Recent work on word ordering has argued that syntactic structure is important, or even required, for effectively recovering the order of a sentence. We find that, in fact, an n-gram language model with a simple heuristic gives strong results on this task. Furthermore, we show that a long short-term memory (LSTM) language model is even more effective at recovering order, with our basic model outperforming a state-of-the-art syntactic model by 11.5 BLEU points. Additional data and larger beams yield further gains, at the expense of training and search time.
Sentence-Level Grammatical Error Identification as Sequence-to-Sequence Correction
Apr 16, 2016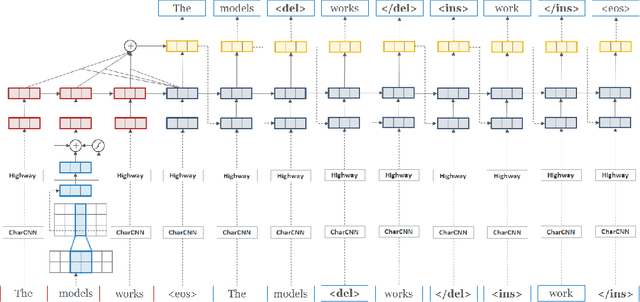
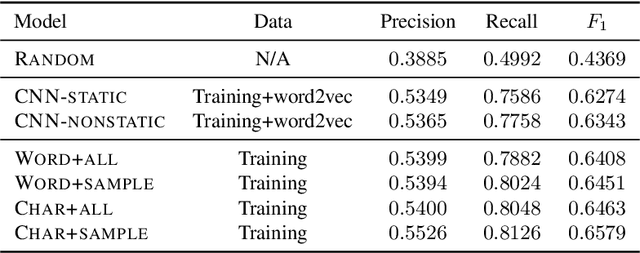
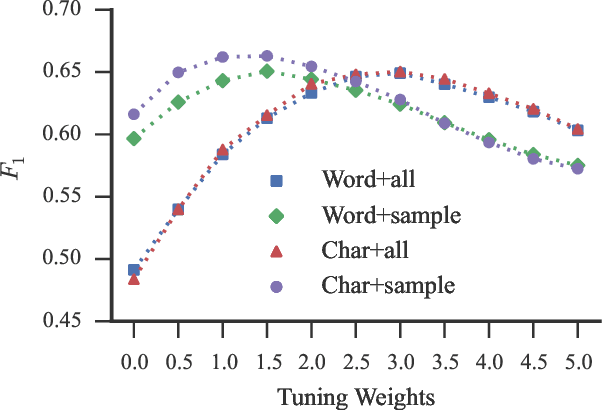
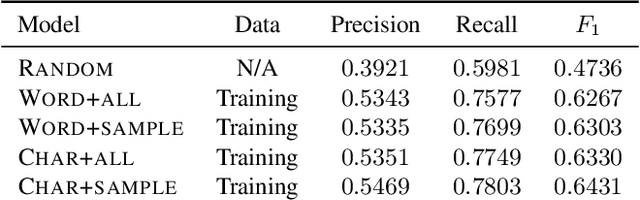
We demonstrate that an attention-based encoder-decoder model can be used for sentence-level grammatical error identification for the Automated Evaluation of Scientific Writing (AESW) Shared Task 2016. The attention-based encoder-decoder models can be used for the generation of corrections, in addition to error identification, which is of interest for certain end-user applications. We show that a character-based encoder-decoder model is particularly effective, outperforming other results on the AESW Shared Task on its own, and showing gains over a word-based counterpart. Our final model--a combination of three character-based encoder-decoder models, one word-based encoder-decoder model, and a sentence-level CNN--is the highest performing system on the AESW 2016 binary prediction Shared Task.
Learning Global Features for Coreference Resolution
Apr 11, 2016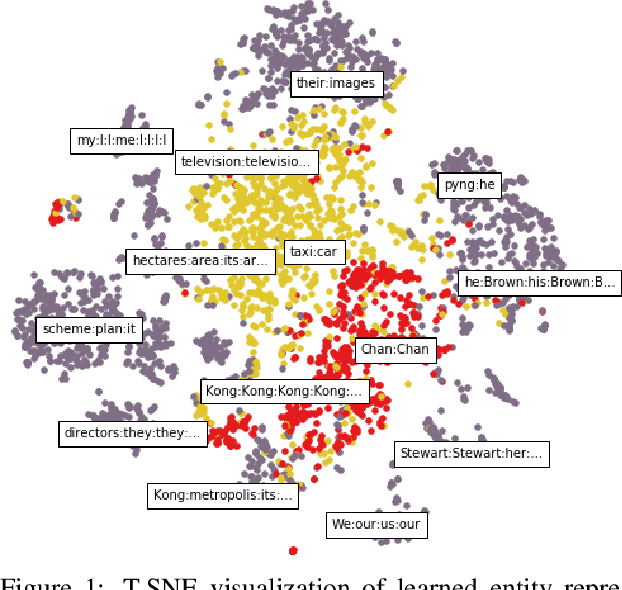
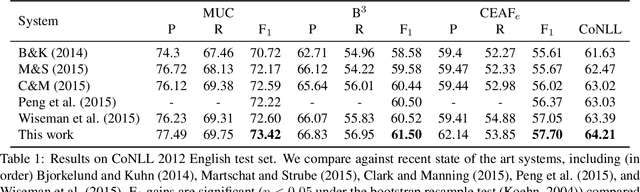

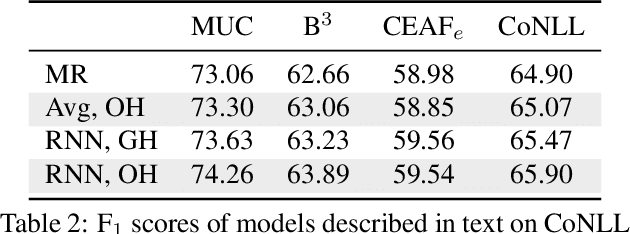
There is compelling evidence that coreference prediction would benefit from modeling global information about entity-clusters. Yet, state-of-the-art performance can be achieved with systems treating each mention prediction independently, which we attribute to the inherent difficulty of crafting informative cluster-level features. We instead propose to use recurrent neural networks (RNNs) to learn latent, global representations of entity clusters directly from their mentions. We show that such representations are especially useful for the prediction of pronominal mentions, and can be incorporated into an end-to-end coreference system that outperforms the state of the art without requiring any additional search.
Recognizing Uncertainty in Speech
Mar 09, 2011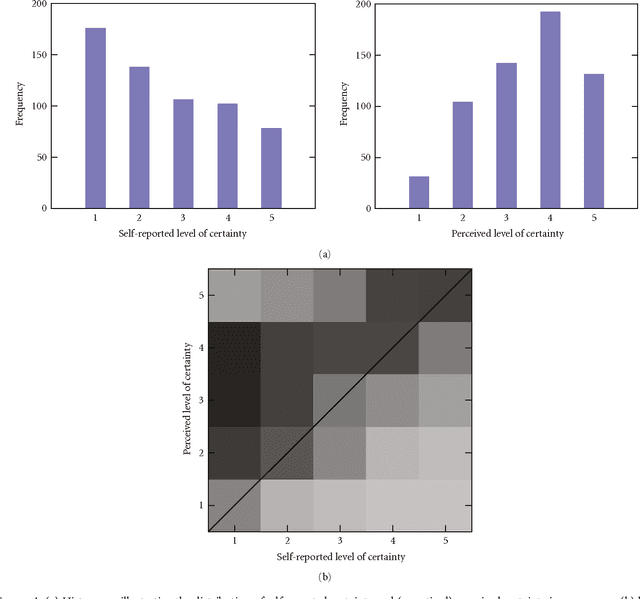
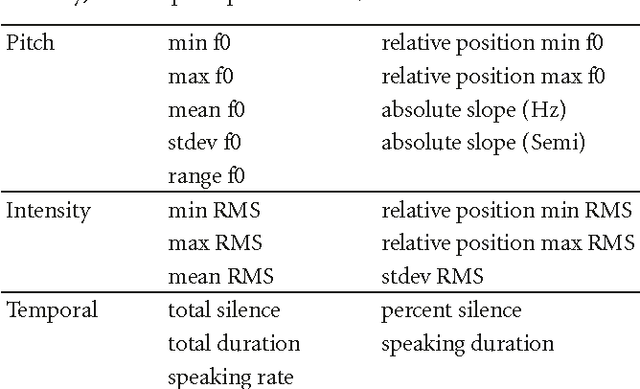

We address the problem of inferring a speaker's level of certainty based on prosodic information in the speech signal, which has application in speech-based dialogue systems. We show that using phrase-level prosodic features centered around the phrases causing uncertainty, in addition to utterance-level prosodic features, improves our model's level of certainty classification. In addition, our models can be used to predict which phrase a person is uncertain about. These results rely on a novel method for eliciting utterances of varying levels of certainty that allows us to compare the utility of contextually-based feature sets. We elicit level of certainty ratings from both the speakers themselves and a panel of listeners, finding that there is often a mismatch between speakers' internal states and their perceived states, and highlighting the importance of this distinction.
* 11 pages
Ellipsis and Higher-Order Unification
Mar 08, 1995We present a new method for characterizing the interpretive possibilities generated by elliptical constructions in natural language. Unlike previous analyses, which postulate ambiguity of interpretation or derivation in the full clause source of the ellipsis, our analysis requires no such hidden ambiguity. Further, the analysis follows relatively directly from an abstract statement of the ellipsis interpretation problem. It predicts correctly a wide range of interactions between ellipsis and other semantic phenomena such as quantifier scope and bound anaphora. Finally, although the analysis itself is stated nonprocedurally, it admits of a direct computational method for generating interpretations.
* 54 pages
Restricting the Weak-Generative Capacity of Synchronous Tree-Adjoining Grammars
Aug 30, 1994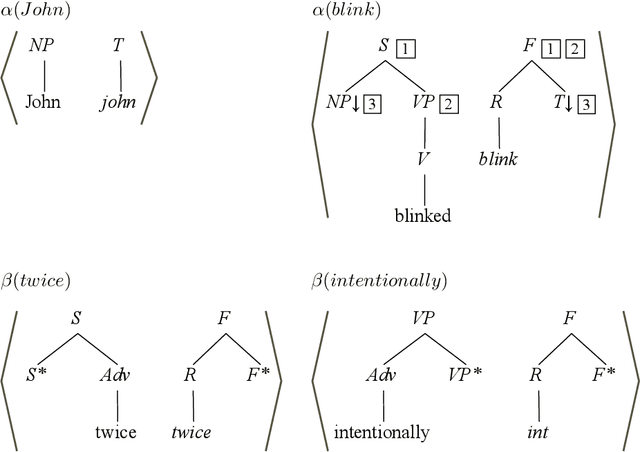
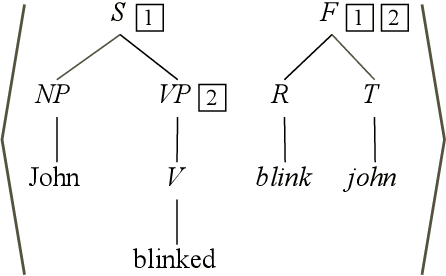
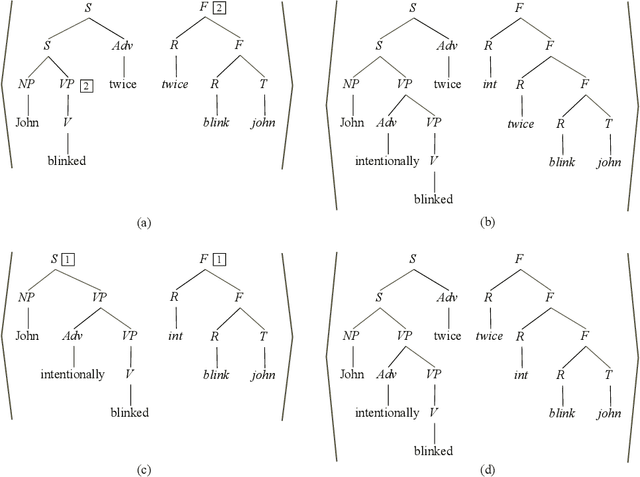
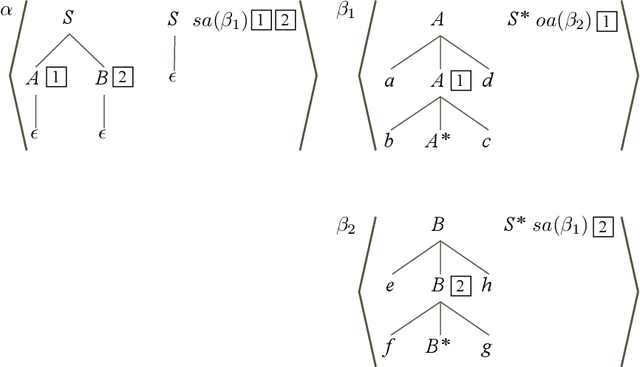
The formalism of synchronous tree-adjoining grammars, a variant of standard tree-adjoining grammars (TAG), was intended to allow the use of TAGs for language transduction in addition to language specification. In previous work, the definition of the transduction relation defined by a synchronous TAG was given by appeal to an iterative rewriting process. The rewriting definition of derivation is problematic in that it greatly extends the expressivity of the formalism and makes the design of parsing algorithms difficult if not impossible. We introduce a simple, natural definition of synchronous tree-adjoining derivation, based on isomorphisms between standard tree-adjoining derivations, that avoids the expressivity and implementability problems of the original rewriting definition. The decrease in expressivity, which would otherwise make the method unusable, is offset by the incorporation of an alternative definition of standard tree-adjoining derivation, previously proposed for completely separate reasons, thereby making it practical to entertain using the natural definition of synchronous derivation. Nonetheless, some remaining problematic cases call for yet more flexibility in the definition; the isomorphism requirement may have to be relaxed. It remains for future research to tune the exact requirements on the allowable mappings.
* 21 pages, uses lingmacros.sty, psfig.sty, fullname.sty; minor typographical changes only
Principles and Implementation of Deductive Parsing
Apr 26, 1994



We present a system for generating parsers based directly on the metaphor of parsing as deduction. Parsing algorithms can be represented directly as deduction systems, and a single deduction engine can interpret such deduction systems so as to implement the corresponding parser. The method generalizes easily to parsers for augmented phrase structure formalisms, such as definite-clause grammars and other logic grammar formalisms, and has been used for rapid prototyping of parsing algorithms for a variety of formalisms including variants of tree-adjoining grammars, categorial grammars, and lexicalized context-free grammars.
Lessons from a Restricted Turing Test
Apr 04, 1994We report on the recent Loebner prize competition inspired by Turing's test of intelligent behavior. The presentation covers the structure of the competition and the outcome of its first instantiation in an actual event, and an analysis of the purpose, design, and appropriateness of such a competition. We argue that the competition has no clear purpose, that its design prevents any useful outcome, and that such a competition is inappropriate given the current level of technology. We then speculate as to suitable alternatives to the Loebner prize.
An Alternative Conception of Tree-Adjoining Derivation
Apr 04, 1994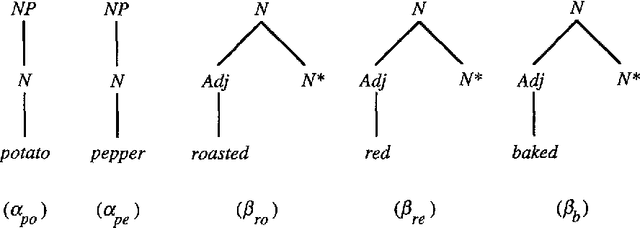
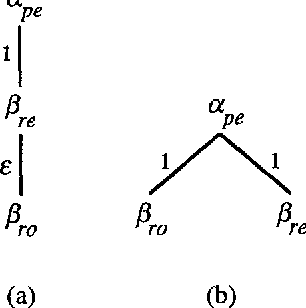
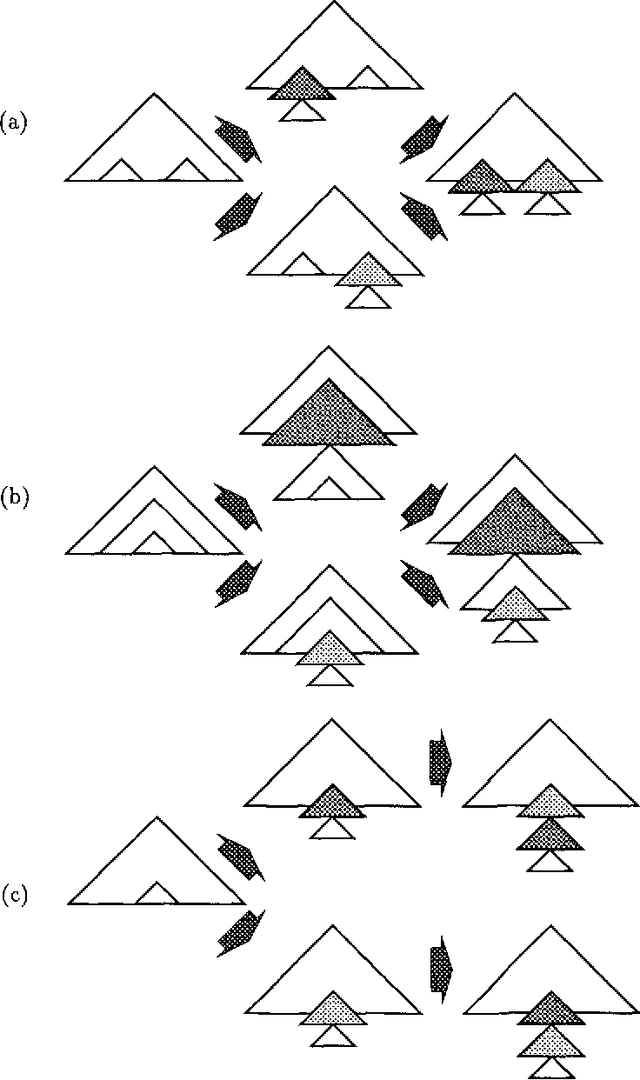
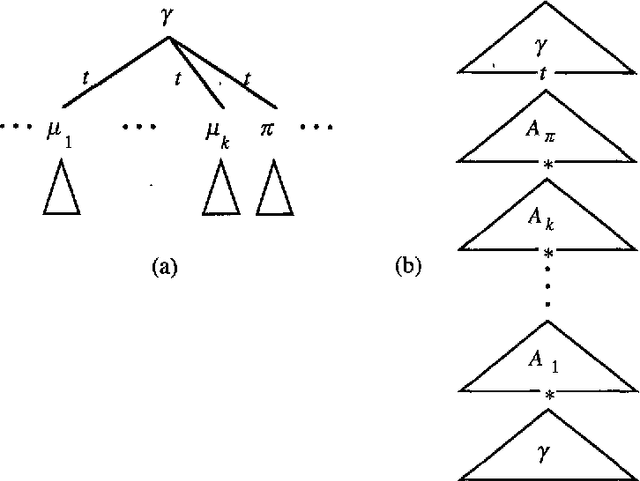
The precise formulation of derivation for tree-adjoining grammars has important ramifications for a wide variety of uses of the formalism, from syntactic analysis to semantic interpretation and statistical language modeling. We argue that the definition of tree-adjoining derivation must be reformulated in order to manifest the proper linguistic dependencies in derivations. The particular proposal is both precisely characterizable through a definition of TAG derivations as equivalence classes of ordered derivation trees, and computationally operational, by virtue of a compilation to linear indexed grammars together with an efficient algorithm for recognition and parsing according to the compiled grammar.
* 33 pages