 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPM 1.0: Video-based Character Performance Model
Apr 09, 2026Performance, the externalization of intent, emotion, and personality through visual, vocal, and temporal behavior, is what makes a character alive. Learning such performance from video is a promising alternative to traditional 3D pipelines. However, existing video models struggle to jointly achieve high expressiveness, real-time inference, and long-horizon identity stability, a tension we call the performance trilemma. Conversation is the most comprehensive performance scenario, as characters simultaneously speak, listen, react, and emote while maintaining identity over time. To address this, we present LPM 1.0 (Large Performance Model), focusing on single-person full-duplex audio-visual conversational performance. Concretely, we build a multimodal human-centric dataset through strict filtering, speaking-listening audio-video pairing, performance understanding, and identity-aware multi-reference extraction; train a 17B-parameter Diffusion Transformer (Base LPM) for highly controllable, identity-consistent performance through multimodal conditioning; and distill it into a causal streaming generator (Online LPM) for low-latency, infinite-length interaction. At inference, given a character image with identity-aware references, LPM 1.0 generates listening videos from user audio and speaking videos from synthesized audio, with text prompts for motion control, all at real-time speed with identity-stable, infinite-length generation. LPM 1.0 thus serves as a visual engine for conversational agents, live streaming characters, and game NPCs. To systematically evaluate this setting, we propose LPM-Bench, the first benchmark for interactive character performance. LPM 1.0 achieves state-of-the-art results across all evaluated dimensions while maintaining real-time inference.
Modelling Student Behavior using Granular Large Scale Action Data from a MOOC
Aug 16, 2016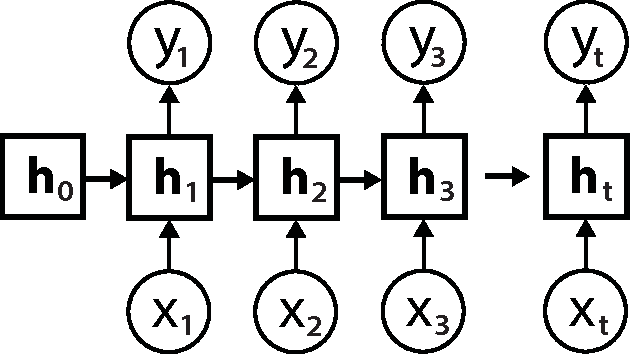

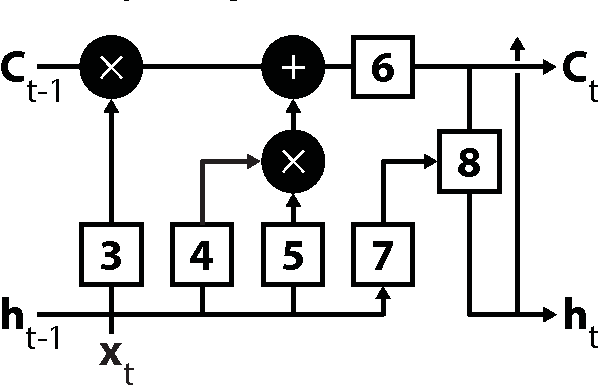
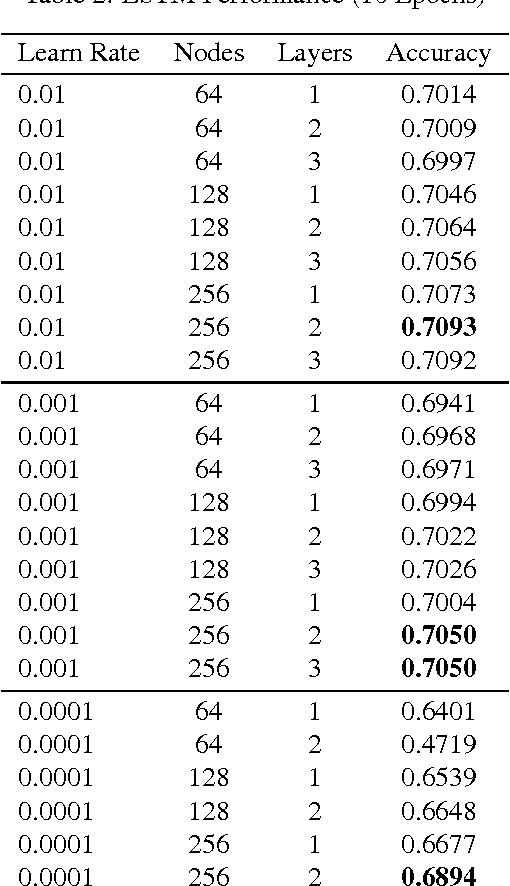
Digital learning environments generate a precise record of the actions learners take as they interact with learning materials and complete exercises towards comprehension. With this high quantity of sequential data comes the potential to apply time series models to learn about underlying behavioral patterns and trends that characterize successful learning based on the granular record of student actions. There exist several methods for looking at longitudinal, sequential data like those recorded from learning environments. In the field of language modelling, traditional n-gram techniques and modern recurrent neural network (RNN) approaches have been applied to algorithmically find structure in language and predict the next word given the previous words in the sentence or paragraph as input. In this paper, we draw an analogy to this work by treating student sequences of resource views and interactions in a MOOC as the inputs and predicting students' next interaction as outputs. In this study, we train only on students who received a certificate of completion. In doing so, the model could potentially be used for recommendation of sequences eventually leading to success, as opposed to perpetuating unproductive behavior. Given that the MOOC used in our study had over 3,500 unique resources, predicting the exact resource that a student will interact with next might appear to be a difficult classification problem. We find that simply following the syllabus (built-in structure of the course) gives on average 23% accuracy in making this prediction, followed by the n-gram method with 70.4%, and RNN based methods with 72.2%. This research lays the ground work for recommendation in a MOOC and other digital learning environments where high volumes of sequential data exist.