 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRC-Mixup: A Data Augmentation Strategy against Noisy Data for Regression Tasks
May 28, 2024



We study the problem of robust data augmentation for regression tasks in the presence of noisy data. Data augmentation is essential for generalizing deep learning models, but most of the techniques like the popular Mixup are primarily designed for classification tasks on image data. Recently, there are also Mixup techniques that are specialized to regression tasks like C-Mixup. In comparison to Mixup, which takes linear interpolations of pairs of samples, C-Mixup is more selective in which samples to mix based on their label distances for better regression performance. However, C-Mixup does not distinguish noisy versus clean samples, which can be problematic when mixing and lead to suboptimal model performance. At the same time, robust training has been heavily studied where the goal is to train accurate models against noisy data through multiple rounds of model training. We thus propose our data augmentation strategy RC-Mixup, which tightly integrates C-Mixup with multi-round robust training methods for a synergistic effect. In particular, C-Mixup improves robust training in identifying clean data, while robust training provides cleaner data to C-Mixup for it to perform better. A key advantage of RC-Mixup is that it is data-centric where the robust model training algorithm itself does not need to be modified, but can simply benefit from data mixing. We show in our experiments that RC-Mixup significantly outperforms C-Mixup and robust training baselines on noisy data benchmarks and can be integrated with various robust training methods.
ERBench: An Entity-Relationship based Automatically Verifiable Hallucination Benchmark for Large Language Models
Mar 08, 2024



Large language models (LLMs) have achieved unprecedented performance in various applications, yet their evaluation remains a critical issue. Existing hallucination benchmarks are either static or lack adjustable complexity for thorough analysis. We contend that utilizing existing relational databases is a promising approach for constructing benchmarks due to their accurate knowledge description via functional dependencies. We propose ERBench to automatically convert any relational database into a benchmark based on the entity-relationship (ER) model. Our key idea is to construct questions using the database schema, records, and functional dependencies such that they can be automatically verified. In addition, we use foreign key constraints to join relations and construct multihop questions, which can be arbitrarily complex and used to debug the intermediate answers of LLMs. Finally, ERBench supports continuous evaluation, multimodal questions, and various prompt engineering techniques. In our experiments, we construct an LLM benchmark using databases of multiple domains and make an extensive comparison of contemporary LLMs. We observe that better LLMs like GPT-4 can handle a larger variety of question types, but are by no means perfect. Also, correct answers do not necessarily imply correct rationales, which is an important evaluation that ERBench does better than other benchmarks for various question types. Code is available at https: //github.com/DILAB-KAIST/ERBench.
LEVI: Generalizable Fine-tuning via Layer-wise Ensemble of Different Views
Feb 07, 2024



Fine-tuning is becoming widely used for leveraging the power of pre-trained foundation models in new downstream tasks. While there are many successes of fine-tuning on various tasks, recent studies have observed challenges in the generalization of fine-tuned models to unseen distributions (i.e., out-of-distribution; OOD). To improve OOD generalization, some previous studies identify the limitations of fine-tuning data and regulate fine-tuning to preserve the general representation learned from pre-training data. However, potential limitations in the pre-training data and models are often ignored. In this paper, we contend that overly relying on the pre-trained representation may hinder fine-tuning from learning essential representations for downstream tasks and thus hurt its OOD generalization. It can be especially catastrophic when new tasks are from different (sub)domains compared to pre-training data. To address the issues in both pre-training and fine-tuning data, we propose a novel generalizable fine-tuning method LEVI, where the pre-trained model is adaptively ensembled layer-wise with a small task-specific model, while preserving training and inference efficiencies. By combining two complementing models, LEVI effectively suppresses problematic features in both the fine-tuning data and pre-trained model and preserves useful features for new tasks. Broad experiments with large language and vision models show that LEVI greatly improves fine-tuning generalization via emphasizing different views from fine-tuning data and pre-trained features.
Falcon: Fair Active Learning using Multi-armed Bandits
Jan 24, 2024



Biased data can lead to unfair machine learning models, highlighting the importance of embedding fairness at the beginning of data analysis, particularly during dataset curation and labeling. In response, we propose Falcon, a scalable fair active learning framework. Falcon adopts a data-centric approach that improves machine learning model fairness via strategic sample selection. Given a user-specified group fairness measure, Falcon identifies samples from "target groups" (e.g., (attribute=female, label=positive)) that are the most informative for improving fairness. However, a challenge arises since these target groups are defined using ground truth labels that are not available during sample selection. To handle this, we propose a novel trial-and-error method, where we postpone using a sample if the predicted label is different from the expected one and falls outside the target group. We also observe the trade-off that selecting more informative samples results in higher likelihood of postponing due to undesired label prediction, and the optimal balance varies per dataset. We capture the trade-off between informativeness and postpone rate as policies and propose to automatically select the best policy using adversarial multi-armed bandit methods, given their computational efficiency and theoretical guarantees. Experiments show that Falcon significantly outperforms existing fair active learning approaches in terms of fairness and accuracy and is more efficient. In particular, only Falcon supports a proper trade-off between accuracy and fairness where its maximum fairness score is 1.8-4.5x higher than the second-best results.
Quilt: Robust Data Segment Selection against Concept Drifts
Dec 15, 2023Continuous machine learning pipelines are common in industrial settings where models are periodically trained on data streams. Unfortunately, concept drifts may occur in data streams where the joint distribution of the data X and label y, P(X, y), changes over time and possibly degrade model accuracy. Existing concept drift adaptation approaches mostly focus on updating the model to the new data possibly using ensemble techniques of previous models and tend to discard the drifted historical data. However, we contend that explicitly utilizing the drifted data together leads to much better model accuracy and propose Quilt, a data-centric framework for identifying and selecting data segments that maximize model accuracy. To address the potential downside of efficiency, Quilt extends existing data subset selection techniques, which can be used to reduce the training data without compromising model accuracy. These techniques cannot be used as is because they only assume virtual drifts where the posterior probabilities P(y|X) are assumed not to change. In contrast, a key challenge in our setup is to also discard undesirable data segments with concept drifts. Quilt thus discards drifted data segments and selects data segment subsets holistically for accurate and efficient model training. The two operations use gradient-based scores, which have little computation overhead. In our experiments, we show that Quilt outperforms state-of-the-art drift adaptation and data selection baselines on synthetic and real datasets.
Personalized DP-SGD using Sampling Mechanisms
May 24, 2023



Personalized privacy becomes critical in deep learning for Trustworthy AI. While Differentially Private Stochastic Gradient Descent (DP-SGD) is widely used in deep learning methods supporting privacy, it provides the same level of privacy to all individuals, which may lead to overprotection and low utility. In practice, different users may require different privacy levels, and the model can be improved by using more information about the users with lower privacy requirements. There are also recent works on differential privacy of individuals when using DP-SGD, but they are mostly about individual privacy accounting and do not focus on satisfying different privacy levels. We thus extend DP-SGD to support a recent privacy notion called ($\Phi$,$\Delta$)-Personalized Differential Privacy (($\Phi$,$\Delta$)-PDP), which extends an existing PDP concept called $\Phi$-PDP. Our algorithm uses a multi-round personalized sampling mechanism and embeds it within the DP-SGD iterations. Experiments on real datasets show that our algorithm outperforms DP-SGD and simple combinations of DP-SGD with existing PDP mechanisms in terms of model performance and efficiency due to its embedded sampling mechanism.
Improving Fair Training under Correlation Shifts
Feb 05, 2023



Model fairness is an essential element for Trustworthy AI. While many techniques for model fairness have been proposed, most of them assume that the training and deployment data distributions are identical, which is often not true in practice. In particular, when the bias between labels and sensitive groups changes, the fairness of the trained model is directly influenced and can worsen. We make two contributions for solving this problem. First, we analytically show that existing in-processing fair algorithms have fundamental limits in accuracy and group fairness. We introduce the notion of correlation shifts, which can explicitly capture the change of the above bias. Second, we propose a novel pre-processing step that samples the input data to reduce correlation shifts and thus enables the in-processing approaches to overcome their limitations. We formulate an optimization problem for adjusting the data ratio among labels and sensitive groups to reflect the shifted correlation. A key benefit of our approach lies in decoupling the roles of pre- and in-processing approaches: correlation adjustment via pre-processing and unfairness mitigation on the processed data via in-processing. Experiments show that our framework effectively improves existing in-processing fair algorithms w.r.t. accuracy and fairness, both on synthetic and real datasets.
XClusters: Explainability-first Clustering
Sep 22, 2022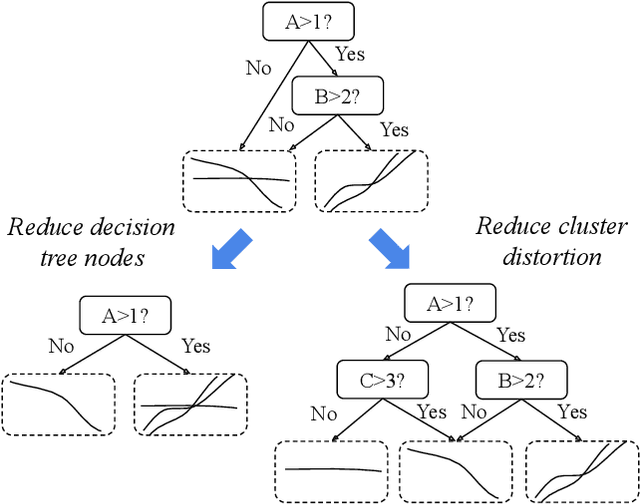

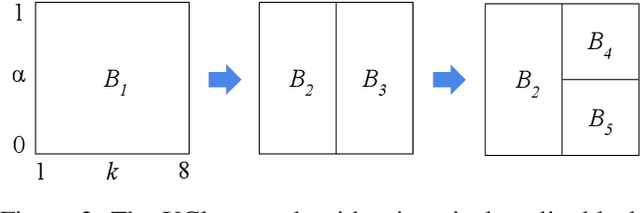
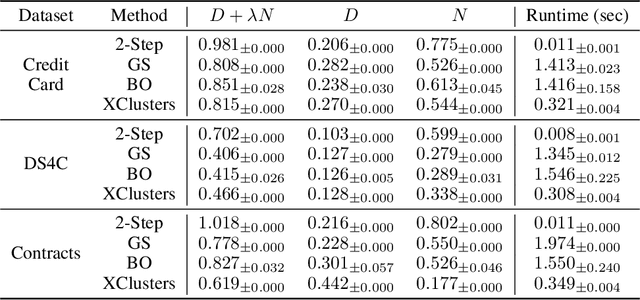
We study the problem of explainability-first clustering where explainability becomes a first-class citizen for clustering. Previous clustering approaches use decision trees for explanation, but only after the clustering is completed. In contrast, our approach is to perform clustering and decision tree training holistically where the decision tree's performance and size also influence the clustering results. We assume the attributes for clustering and explaining are distinct, although this is not necessary. We observe that our problem is a monotonic optimization where the objective function is a difference of monotonic functions. We then propose an efficient branch-and-bound algorithm for finding the best parameters that lead to a balance of cluster distortion and decision tree explainability. Our experiments show that our method can improve the explainability of any clustering that fits in our framework.
iFlipper: Label Flipping for Individual Fairness
Sep 15, 2022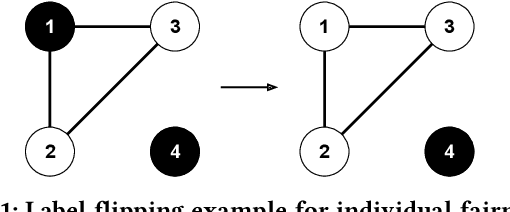
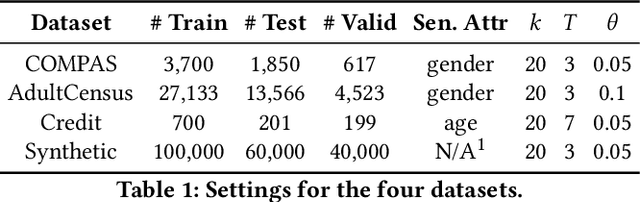
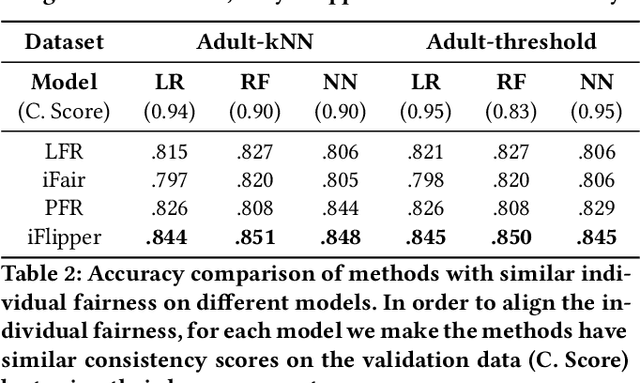
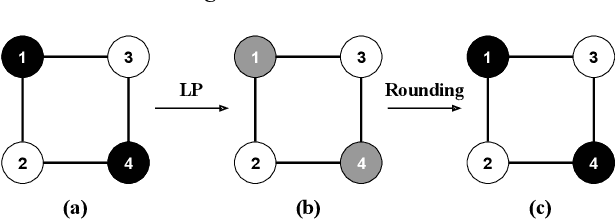
As machine learning becomes prevalent, mitigating any unfairness present in the training data becomes critical. Among the various notions of fairness, this paper focuses on the well-known individual fairness, which states that similar individuals should be treated similarly. While individual fairness can be improved when training a model (in-processing), we contend that fixing the data before model training (pre-processing) is a more fundamental solution. In particular, we show that label flipping is an effective pre-processing technique for improving individual fairness. Our system iFlipper solves the optimization problem of minimally flipping labels given a limit to the individual fairness violations, where a violation occurs when two similar examples in the training data have different labels. We first prove that the problem is NP-hard. We then propose an approximate linear programming algorithm and provide theoretical guarantees on how close its result is to the optimal solution in terms of the number of label flips. We also propose techniques for making the linear programming solution more optimal without exceeding the violations limit. Experiments on real datasets show that iFlipper significantly outperforms other pre-processing baselines in terms of individual fairness and accuracy on unseen test sets. In addition, iFlipper can be combined with in-processing techniques for even better results.
Redactor: Targeted Disinformation Generation using Probabilistic Decision Boundaries
Feb 07, 2022



Information leakage is becoming a critical problem as various information becomes publicly available by mistake, and machine learning models train on that data to provide services. As a result, one's private information could easily be memorized by such trained models. Unfortunately, deleting information is out of the question as the data is already exposed to the Web or third-party platforms. Moreover, we cannot necessarily control the labeling process and the model trainings by other parties either. In this setting, we study the problem of targeted disinformation where the goal is to lower the accuracy of inference attacks on a specific target (e.g., a person's profile) only using data insertion. While our problem is related to data privacy and defenses against exploratory attacks, our techniques are inspired by targeted data poisoning attacks with some key differences. We show that our problem is best solved by finding the closest points to the target in the input space that will be labeled as a different class. Since we do not control the labeling process, we instead conservatively estimate the labels probabilistically by combining decision boundaries of multiple classifiers using data programming techniques. We also propose techniques for making the disinformation realistic. Our experiments show that a probabilistic decision boundary can be a good proxy for labelers, and that our approach outperforms other targeted poisoning methods when using end-to-end training on real datasets.