 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Multiplicity in SHAP: Characterization and Assessment
Jan 19, 2026Post-hoc explanations are widely used to justify, contest, and audit automated decisions in high-stakes domains. SHAP, in particular, is often treated as a reliable account of which features drove an individual prediction. Yet SHAP explanations can vary substantially across repeated runs even when the input, task, and trained model are held fixed. We term this phenomenon explanation multiplicity: multiple internally valid but substantively different explanations for the same decision. We present a methodology to characterize multiplicity in feature-attribution explanations and to disentangle sources due to model training/selection from stochasticity intrinsic to the explanation pipeline. We further show that apparent stability depends on the metric: magnitude-based distances can remain near zero while rank-based measures reveal substantial churn in the identity and ordering of top features. To contextualize observed disagreement, we derive randomized baseline values under plausible null models. Across datasets, model classes, and confidence regimes, we find explanation multiplicity is pervasive and persists even for high-confidence predictions, highlighting the need for metrics and baselines that match the intended use of explanations.
SHAP-based Explanations are Sensitive to Feature Representation
May 13, 2025



Local feature-based explanations are a key component of the XAI toolkit. These explanations compute feature importance values relative to an ``interpretable'' feature representation. In tabular data, feature values themselves are often considered interpretable. This paper examines the impact of data engineering choices on local feature-based explanations. We demonstrate that simple, common data engineering techniques, such as representing age with a histogram or encoding race in a specific way, can manipulate feature importance as determined by popular methods like SHAP. Notably, the sensitivity of explanations to feature representation can be exploited by adversaries to obscure issues like discrimination. While the intuition behind these results is straightforward, their systematic exploration has been lacking. Previous work has focused on adversarial attacks on feature-based explainers by biasing data or manipulating models. To the best of our knowledge, this is the first study demonstrating that explainers can be misled by standard, seemingly innocuous data engineering techniques.
XClusters: Explainability-first Clustering
Sep 22, 2022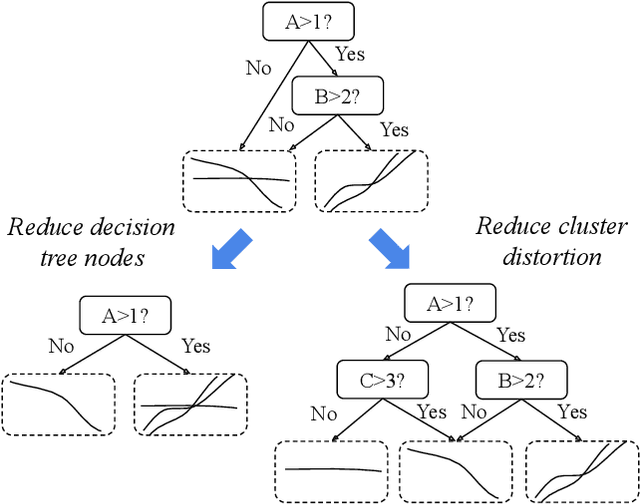

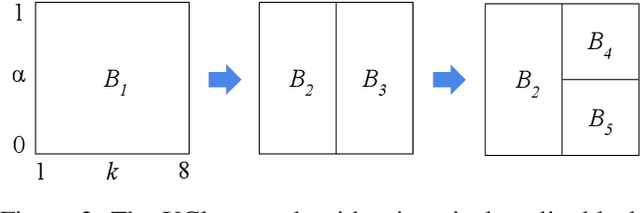
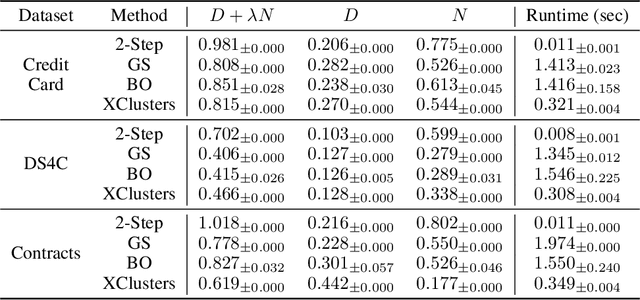
We study the problem of explainability-first clustering where explainability becomes a first-class citizen for clustering. Previous clustering approaches use decision trees for explanation, but only after the clustering is completed. In contrast, our approach is to perform clustering and decision tree training holistically where the decision tree's performance and size also influence the clustering results. We assume the attributes for clustering and explaining are distinct, although this is not necessary. We observe that our problem is a monotonic optimization where the objective function is a difference of monotonic functions. We then propose an efficient branch-and-bound algorithm for finding the best parameters that lead to a balance of cluster distortion and decision tree explainability. Our experiments show that our method can improve the explainability of any clustering that fits in our framework.