 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumMUSS: Human Motion Understanding using State Space Models
Apr 16, 2024



Understanding human motion from video is essential for a range of applications, including pose estimation, mesh recovery and action recognition. While state-of-the-art methods predominantly rely on transformer-based architectures, these approaches have limitations in practical scenarios. Transformers are slower when sequentially predicting on a continuous stream of frames in real-time, and do not generalize to new frame rates. In light of these constraints, we propose a novel attention-free spatiotemporal model for human motion understanding building upon recent advancements in state space models. Our model not only matches the performance of transformer-based models in various motion understanding tasks but also brings added benefits like adaptability to different video frame rates and enhanced training speed when working with longer sequence of keypoints. Moreover, the proposed model supports both offline and real-time applications. For real-time sequential prediction, our model is both memory efficient and several times faster than transformer-based approaches while maintaining their high accuracy.
Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation
Apr 01, 2020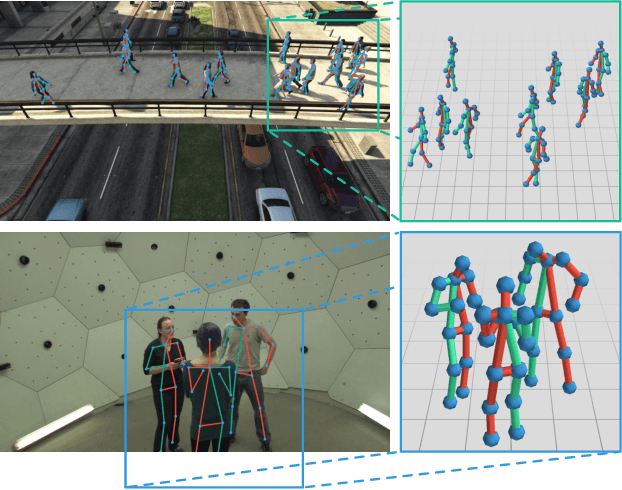
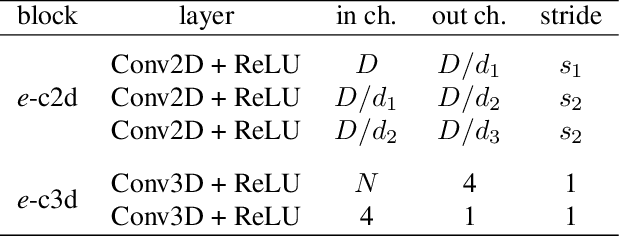
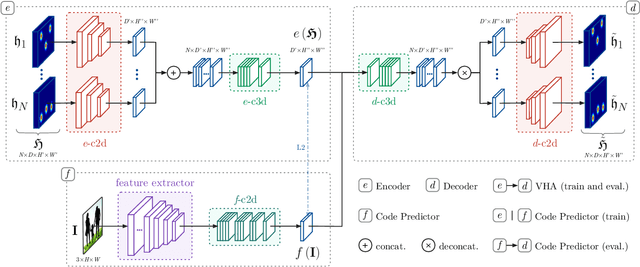

In this paper we present a novel approach for bottom-up multi-person 3D human pose estimation from monocular RGB images. We propose to use high resolution volumetric heatmaps to model joint locations, devising a simple and effective compression method to drastically reduce the size of this representation. At the core of the proposed method lies our Volumetric Heatmap Autoencoder, a fully-convolutional network tasked with the compression of ground-truth heatmaps into a dense intermediate representation. A second model, the Code Predictor, is then trained to predict these codes, which can be decompressed at test time to re-obtain the original representation. Our experimental evaluation shows that our method performs favorably when compared to state of the art on both multi-person and single-person 3D human pose estimation datasets and, thanks to our novel compression strategy, can process full-HD images at the constant runtime of 8 fps regardless of the number of subjects in the scene. Code and models available at https://github.com/fabbrimatteo/LoCO .
RandomNet: Towards Fully Automatic Neural Architecture Design for Multimodal Learning
Mar 02, 2020
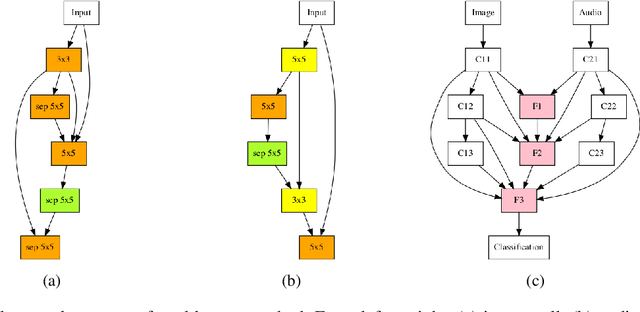

Almost all neural architecture search methods are evaluated in terms of performance (i.e. test accuracy) of the model structures that it finds. Should it be the only metric for a good autoML approach? To examine aspects beyond performance, we propose a set of criteria aimed at evaluating the core of autoML problem: the amount of human intervention required to deploy these methods into real world scenarios. Based on our proposed evaluation checklist, we study the effectiveness of a random search strategy for fully automated multimodal neural architecture search. Compared to traditional methods that rely on manually crafted feature extractors, our method selects each modality from a large search space with minimal human supervision. We show that our proposed random search strategy performs close to the state of the art on the AV-MNIST dataset while meeting the desirable characteristics for a fully automated design process.
Can Adversarial Networks Hallucinate Occluded People With a Plausible Aspect?
Jan 23, 2019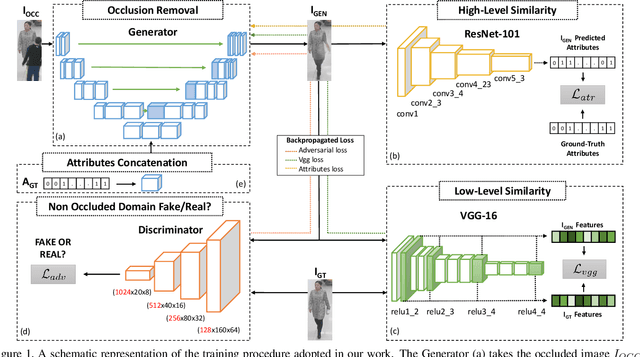
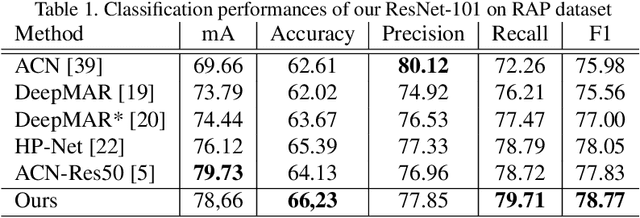
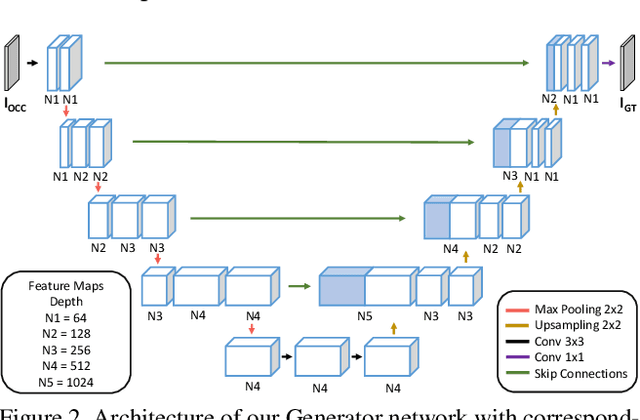

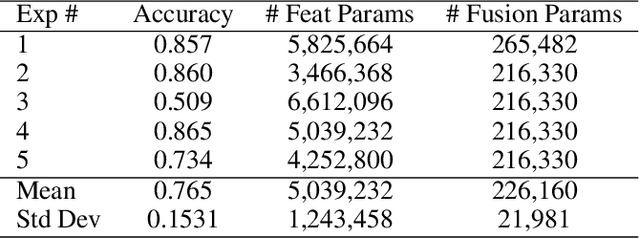
When you see a person in a crowd, occluded by other persons, you miss visual information that can be used to recognize, re-identify or simply classify him or her. You can imagine its appearance given your experience, nothing more. Similarly, AI solutions can try to hallucinate missing information with specific deep learning architectures, suitably trained with people with and without occlusions. The goal of this work is to generate a complete image of a person, given an occluded version in input, that should be a) without occlusion b) similar at pixel level to a completely visible people shape c) capable to conserve similar visual attributes (e.g. male/female) of the original one. For the purpose, we propose a new approach by integrating the state-of-the-art of neural network architectures, namely U-nets and GANs, as well as discriminative attribute classification nets, with an architecture specifically designed to de-occlude people shapes. The network is trained to optimize a Loss function which could take into account the aforementioned objectives. As well we propose two datasets for testing our solution: the first one, occluded RAP, created automatically by occluding real shapes of the RAP dataset (which collects also attributes of the people aspect); the second is a large synthetic dataset, AiC, generated in computer graphics with data extracted from the GTA video game, that contains 3D data of occluded objects by construction. Results are impressive and outperform any other previous proposal. This result could be an initial step to many further researches to recognize people and their behavior in an open crowded world.
TransFlow: Unsupervised Motion Flow by Joint Geometric and Pixel-level Estimation
Oct 30, 2017
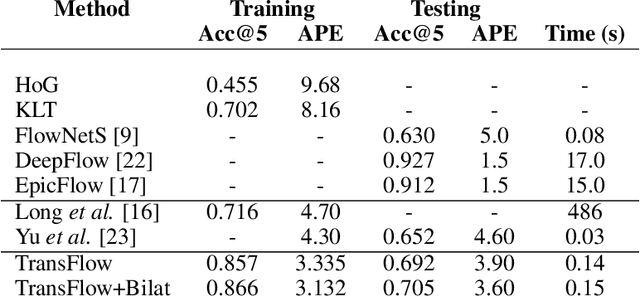
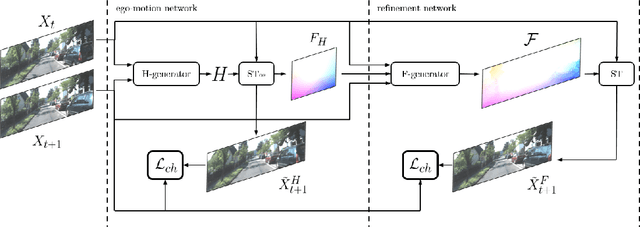

We address unsupervised optical flow estimation for ego-centric motion. We argue that optical flow can be cast as a geometrical warping between two successive video frames and devise a deep architecture to estimate such transformation in two stages. First, a dense pixel-level flow is computed with a geometric prior imposing strong spatial constraints. Such prior is typical of driving scenes, where the point of view is coherent with the vehicle motion. We show how such global transformation can be approximated with an homography and how spatial transformer layers can be employed to compute the flow field implied by such transformation. The second stage then refines the prediction feeding a second deeper network. A final reconstruction loss compares the warping of frame X(t) with the subsequent frame X(t+1) and guides both estimates. The model, which we named TransFlow, performs favorably compared to other unsupervised algorithms, and shows better generalization compared to supervised methods with a 3x reduction in error on unseen data.
Learning Where to Attend Like a Human Driver
May 09, 2017
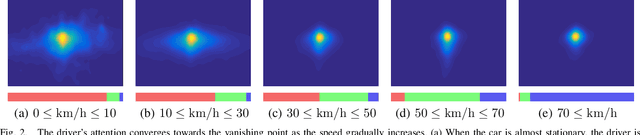


Despite the advent of autonomous cars, it's likely - at least in the near future - that human attention will still maintain a central role as a guarantee in terms of legal responsibility during the driving task. In this paper we study the dynamics of the driver's gaze and use it as a proxy to understand related attentional mechanisms. First, we build our analysis upon two questions: where and what the driver is looking at? Second, we model the driver's gaze by training a coarse-to-fine convolutional network on short sequences extracted from the DR(eye)VE dataset. Experimental comparison against different baselines reveal that the driver's gaze can indeed be learnt to some extent, despite i) being highly subjective and ii) having only one driver's gaze available for each sequence due to the irreproducibility of the scene. Eventually, we advocate for a new assisted driving paradigm which suggests to the driver, with no intervention, where she should focus her attention.
Similarity Mapping with Enhanced Siamese Network for Multi-Object Tracking
Jan 24, 2017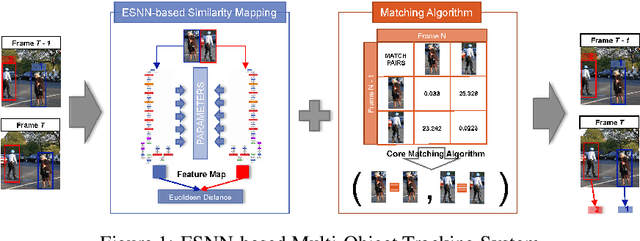
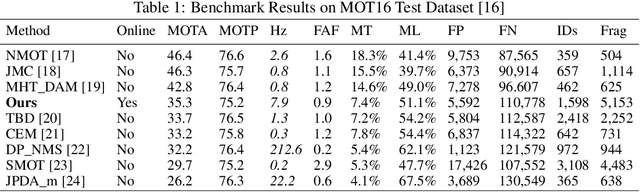
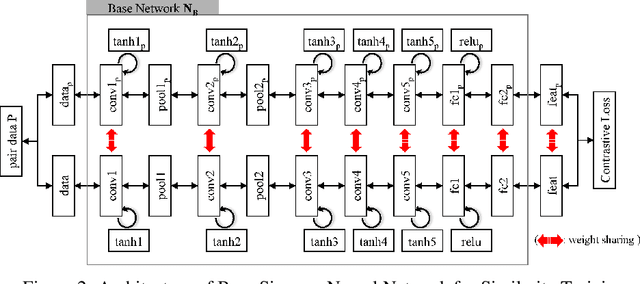

Multi-object tracking has recently become an important area of computer vision, especially for Advanced Driver Assistance Systems (ADAS). Despite growing attention, achieving high performance tracking is still challenging, with state-of-the- art systems resulting in high complexity with a large number of hyper parameters. In this paper, we focus on reducing overall system complexity and the number hyper parameters that need to be tuned to a specific environment. We introduce a novel tracking system based on similarity mapping by Enhanced Siamese Neural Network (ESNN), which accounts for both appearance and geometric information, and is trainable end-to-end. Our system achieves competitive performance in both speed and accuracy on MOT16 challenge, compared to known state-of-the-art methods.
Video Registration in Egocentric Vision under Day and Night Illumination Changes
Jul 28, 2016
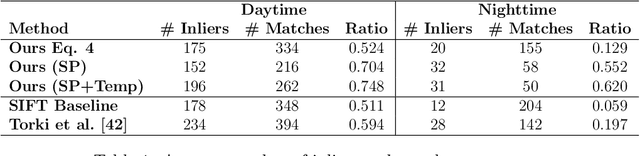
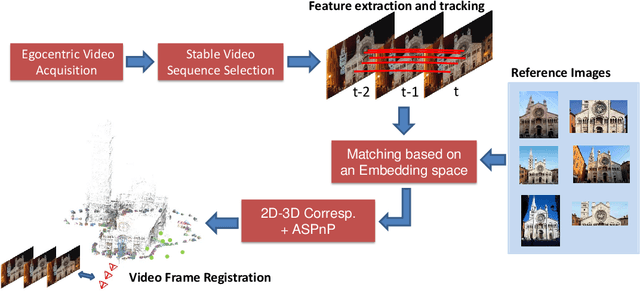

With the spread of wearable devices and head mounted cameras, a wide range of application requiring precise user localization is now possible. In this paper we propose to treat the problem of obtaining the user position with respect to a known environment as a video registration problem. Video registration, i.e. the task of aligning an input video sequence to a pre-built 3D model, relies on a matching process of local keypoints extracted on the query sequence to a 3D point cloud. The overall registration performance is strictly tied to the actual quality of this 2D-3D matching, and can degrade if environmental conditions such as steep changes in lighting like the ones between day and night occur. To effectively register an egocentric video sequence under these conditions, we propose to tackle the source of the problem: the matching process. To overcome the shortcomings of standard matching techniques, we introduce a novel embedding space that allows us to obtain robust matches by jointly taking into account local descriptors, their spatial arrangement and their temporal robustness. The proposal is evaluated using unconstrained egocentric video sequences both in terms of matching quality and resulting registration performance using different 3D models of historical landmarks. The results show that the proposed method can outperform state of the art registration algorithms, in particular when dealing with the challenges of night and day sequences.