 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Scalable Provenance Tracking for LLM-Generated Code Snippets
May 27, 2026Large language models (LLMs) for code completion and generation are increasingly used in software development, yet they may reproduce training examples verbatim and without authorship attribution, raising legal and ethical concerns around plagiarism and license compliance. Classical fingerprint-based plagiarism detectors based on fingerprinting, such as Winnowing, remain highly effective, yet the inspection requires comparing fragments of code to the entire training set, and their linear-time search makes them impractical for the billion-scale corpora used to train modern code LLMs. To bridge this gap, we introduce SOURCETRACKER, a 300M-parameter encoder tailored for code retrieval, together with a hybrid two-stage provenance-tracking pipeline HYBRIDSOURCETRACKER (HST). HST first narrows down a small set of candidate snippets via vector search, then re-ranks those candidates using Winnowing on exact fingerprints. We train and evaluate our system on a 10M-snippet subset of the THESTACKV2 dataset, with both verbatim and adapted snippets that emulate realistic identifier renaming. On an in vitro 100k-snippet search space with adapted queries, our hybrid approach reaches a mean reciprocal rank on par with Winnowing for 30-token fragments. Then, starting from windows >= 60 tokens, it consistently over-performs by up to 5.4% while preserving logarithmic-time query complexity. In a complementary evaluation using an LLM-based judge, we find that many retrieved snippets not labeled as ground truth are still highly similar to the expected sources, particularly with longer context windows, and thus remain useful for end users. Overall, our results demonstrate that integrating vector search with fingerprinting enables scalable, high-precision provenance tracking for code produced by LLMs.
DRAGON: Robust Classification for Very Large Collections of Software Repositories
Feb 09, 2026The ability to automatically classify source code repositories with ''topics'' that reflect their content and purpose is very useful, especially when navigating or searching through large software collections. However, existing approaches often rely heavily on README files and other metadata, which are frequently missing, limiting their applicability in real-world large-scale settings. We present DRAGON, a repository classifier designed for very large and diverse software collections. It operates entirely on lightweight signals commonly stored in version control systems: file and directory names, and optionally the README when available. In repository classification at scale, DRAGON improves F1@5 from 54.8% to 60.8%, surpassing the state of the art. DRAGON remains effective even when README files are absent, with performance degrading by only 6% w.r.t. when they are present. This robustness makes it practical for real-world settings where documentation is sparse or inconsistent. Furthermore, many of the remaining classification errors are near misses, where predicted labels are semantically close to the correct topics. This property increases the practical value of the predictions in real-world software collections, where suggesting a few related topics can still guide search and discovery. As a byproduct of developing DRAGON, we also release the largest open dataset to date for repository classification, consisting of 825 thousand repositories with associated ground-truth topics, sourced from the Software Heritage archive, providing a foundation for future large-scale and language-agnostic research on software repository understanding.
Content-Based Textual File Type Detection at Scale
Jan 21, 2021
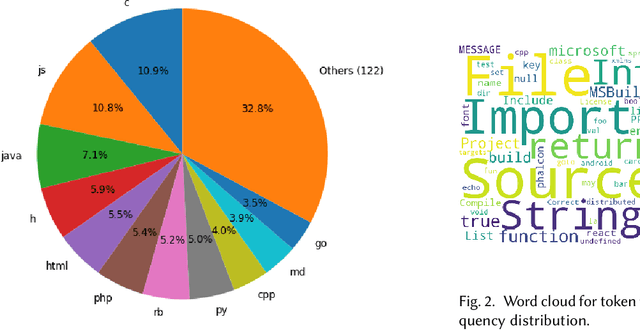
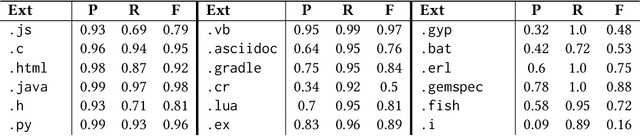
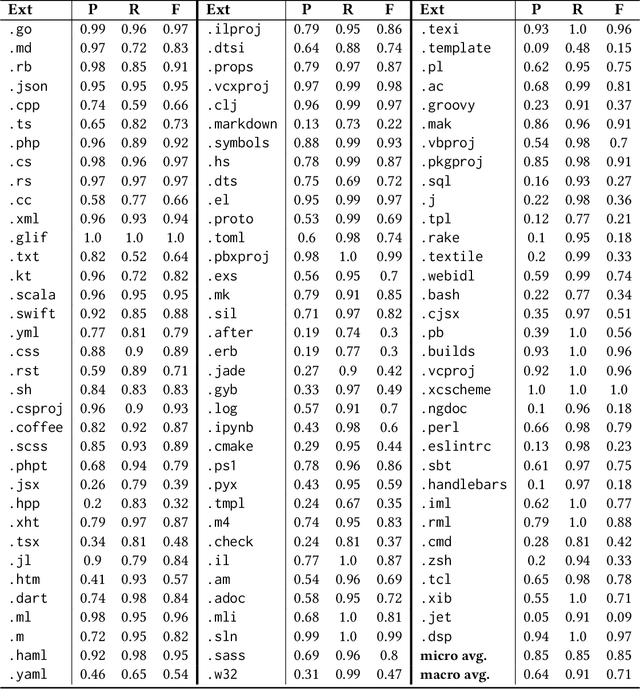
Programming language detection is a common need in the analysis of large source code bases. It is supported by a number of existing tools that rely on several features, and most notably file extensions, to determine file types. We consider the problem of accurately detecting the type of files commonly found in software code bases, based solely on textual file content. Doing so is helpful to classify source code that lack file extensions (e.g., code snippets posted on the Web or executable scripts), to avoid misclassifying source code that has been recorded with wrong or uncommon file extensions, and also shed some light on the intrinsic recognizability of source code files. We propose a simple model that (a) use a language-agnostic word tokenizer for textual files, (b) group tokens in 1-/2-grams, (c) build feature vectors based on N-gram frequencies, and (d) use a simple fully connected neural network as classifier. As training set we use textual files extracted from GitHub repositories with at least 1000 stars, using existing file extensions as ground truth. Despite its simplicity the proposed model reaches 85% in our experiments for a relatively high number of recognized classes (more than 130 file types).