 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization Gap in Self-Evolving Language Model Reasoning
May 31, 2026Recent work suggests that large language models (LLMs) can improve through self-evolution (SE), using supervision signals generated by the model itself. In this work, we ask: under a strict closed-loop setup, where the self-evolution algorithm has access only to an unlabeled prompt set and a base model, how close can internally generated supervision come to oracle-supervised training? We analyze four representative strategies in a unified offline self-evolution framework: single-round verification, multi-turn revision with feedback, iterative training, and curriculum learning. Our primary experiments use Knights and Knaves (KK) logical reasoning tasks, which provide deterministic solutions, controlled difficulty levels, and a clean testbed for easy-to-hard generalization. We first show that self-evolution consistently improves over the base model, but plateaus after excessive training compute is invested, and eventually still leaves a non-trivial gap to oracle supervision. We find that multi-turn critic-revision with large models can reach strong self-evolution performance, with Gemma 12B nearly matching oracle-supervised training. Beyond Knights and Knaves, we also evaluate self-evolution on real-world reasoning benchmarks, where gains are also modest. Overall, our results characterize when closed-loop self-evolution can help and show how internally generated supervision remains insufficient under this minimal formulation.
Dynamic Vision Sensors for Human Activity Recognition
Mar 13, 2018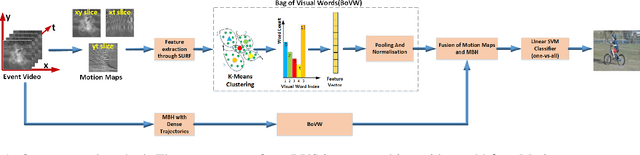
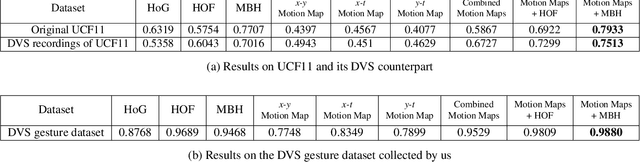

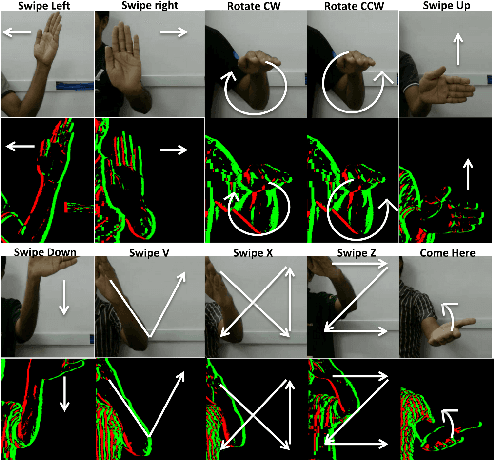
Unlike conventional cameras which capture video at a fixed frame rate, Dynamic Vision Sensors (DVS) record only changes in pixel intensity values. The output of DVS is simply a stream of discrete ON/OFF events based on the polarity of change in its pixel values. DVS has many attractive features such as low power consumption, high temporal resolution, high dynamic range and fewer storage requirements. All these make DVS a very promising camera for potential applications in wearable platforms where power consumption is a major concern. In this paper, we explore the feasibility of using DVS for Human Activity Recognition (HAR). We propose to use the various slices (such as $x-y$, $x-t$, and $y-t$) of the DVS video as a feature map for HAR and denote them as Motion Maps. We show that fusing motion maps with Motion Boundary Histogram (MBH) give good performance on the benchmark DVS dataset as well as on a real DVS gesture dataset collected by us. Interestingly, the performance of DVS is comparable to that of conventional videos although DVS captures only sparse motion information.