 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterising equilibrium logic and nested logic programs: Reductions and complexity
Jun 13, 2009Equilibrium logic is an approach to nonmonotonic reasoning that extends the stable-model and answer-set semantics for logic programs. In particular, it includes the general case of nested logic programs, where arbitrary Boolean combinations are permitted in heads and bodies of rules, as special kinds of theories. In this paper, we present polynomial reductions of the main reasoning tasks associated with equilibrium logic and nested logic programs into quantified propositional logic, an extension of classical propositional logic where quantifications over atomic formulas are permitted. We provide reductions not only for decision problems, but also for the central semantical concepts of equilibrium logic and nested logic programs. In particular, our encodings map a given decision problem into some formula such that the latter is valid precisely in case the former holds. The basic tasks we deal with here are the consistency problem, brave reasoning, and skeptical reasoning. Additionally, we also provide encodings for testing equivalence of theories or programs under different notions of equivalence, viz. ordinary, strong, and uniform equivalence. For all considered reasoning tasks, we analyse their computational complexity and give strict complexity bounds.
A Common View on Strong, Uniform, and Other Notions of Equivalence in Answer-Set Programming
Dec 06, 2007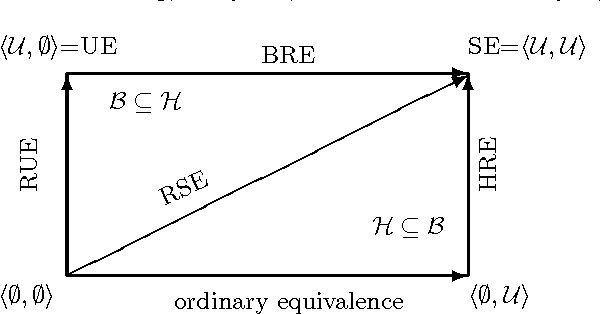
Logic programming under the answer-set semantics nowadays deals with numerous different notions of program equivalence. This is due to the fact that equivalence for substitution (known as strong equivalence) and ordinary equivalence are different concepts. The former holds, given programs P and Q, iff P can be faithfully replaced by Q within any context R, while the latter holds iff P and Q provide the same output, that is, they have the same answer sets. Notions in between strong and ordinary equivalence have been introduced as theoretical tools to compare incomplete programs and are defined by either restricting the syntactic structure of the considered context programs R or by bounding the set A of atoms allowed to occur in R (relativized equivalence).For the latter approach, different A yield properly different equivalence notions, in general. For the former approach, however, it turned out that any ``reasonable'' syntactic restriction to R coincides with either ordinary, strong, or uniform equivalence. In this paper, we propose a parameterization for equivalence notions which takes care of both such kinds of restrictions simultaneously by bounding, on the one hand, the atoms which are allowed to occur in the rule heads of the context and, on the other hand, the atoms which are allowed to occur in the rule bodies of the context. We introduce a general semantical characterization which includes known ones as SE-models (for strong equivalence) or UE-models (for uniform equivalence) as special cases. Moreover,we provide complexity bounds for the problem in question and sketch a possible implementation method. To appear in Theory and Practice of Logic Programming (TPLP).
Semantical Characterizations and Complexity of Equivalences in Answer Set Programming
Feb 18, 2005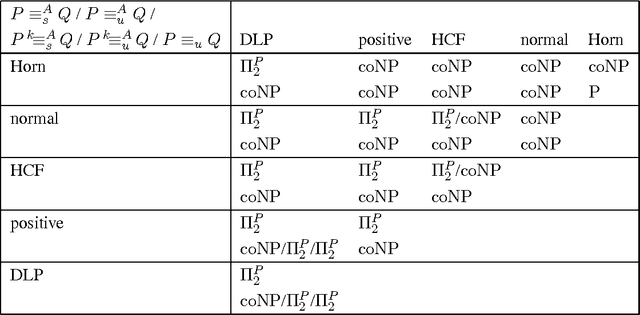

In recent research on non-monotonic logic programming, repeatedly strong equivalence of logic programs P and Q has been considered, which holds if the programs P union R and Q union R have the same answer sets for any other program R. This property strengthens equivalence of P and Q with respect to answer sets (which is the particular case for R is the empty set), and has its applications in program optimization, verification, and modular logic programming. In this paper, we consider more liberal notions of strong equivalence, in which the actual form of R may be syntactically restricted. On the one hand, we consider uniform equivalence, where R is a set of facts rather than a set of rules. This notion, which is well known in the area of deductive databases, is particularly useful for assessing whether programs P and Q are equivalent as components of a logic program which is modularly structured. On the other hand, we consider relativized notions of equivalence, where R ranges over rules over a fixed alphabet, and thus generalize our results to relativized notions of strong and uniform equivalence. For all these notions, we consider disjunctive logic programs in the propositional (ground) case, as well as some restricted classes, provide semantical characterizations and analyze the computational complexity. Our results, which naturally extend to answer set semantics for programs with strong negation, complement the results on strong equivalence of logic programs and pave the way for optimizations in answer set solvers as a tool for input-based problem solving.
A Polynomial Translation of Logic Programs with Nested Expressions into Disjunctive Logic Programs: Preliminary Report
Jul 19, 2002Nested logic programs have recently been introduced in order to allow for arbitrarily nested formulas in the heads and the bodies of logic program rules under the answer sets semantics. Nested expressions can be formed using conjunction, disjunction, as well as the negation as failure operator in an unrestricted fashion. This provides a very flexible and compact framework for knowledge representation and reasoning. Previous results show that nested logic programs can be transformed into standard (unnested) disjunctive logic programs in an elementary way, applying the negation as failure operator to body literals only. This is of great practical relevance since it allows us to evaluate nested logic programs by means of off-the-shelf disjunctive logic programming systems, like DLV. However, it turns out that this straightforward transformation results in an exponential blow-up in the worst-case, despite the fact that complexity results indicate that there is a polynomial translation among both formalisms. In this paper, we take up this challenge and provide a polynomial translation of logic programs with nested expressions into disjunctive logic programs. Moreover, we show that this translation is modular and (strongly) faithful. We have implemented both the straightforward as well as our advanced transformation; the resulting compiler serves as a front-end to DLV and is publicly available on the Web.
QUIP - A Tool for Computing Nonmonotonic Reasoning Tasks
Mar 08, 2000

In this paper, we outline the prototype of an automated inference tool, called QUIP, which provides a uniform implementation for several nonmonotonic reasoning formalisms. The theoretical basis of QUIP is derived from well-known results about the computational complexity of nonmonotonic logics and exploits a representation of the different reasoning tasks in terms of quantified boolean formulae.