 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Intertranslatability of Argumentation Semantics
Jan 16, 2014



Translations between different nonmonotonic formalisms always have been an important topic in the field, in particular to understand the knowledge-representation capabilities those formalisms offer. We provide such an investigation in terms of different semantics proposed for abstract argumentation frameworks, a nonmonotonic yet simple formalism which received increasing interest within the last decade. Although the properties of these different semantics are nowadays well understood, there are no explicit results about intertranslatability. We provide such translations wrt. different properties and also give a few novel complexity results which underlie some negative results.
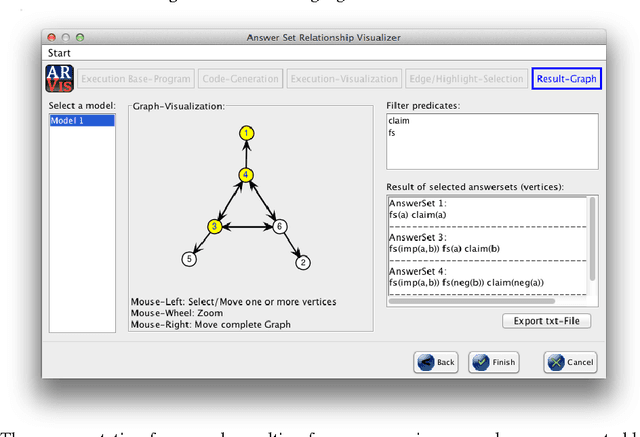
Modularity Aspects of Disjunctive Stable Models
Jan 15, 2014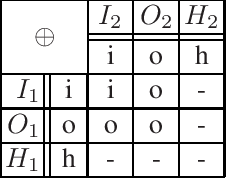
Practically all programming languages allow the programmer to split a program into several modules which brings along several advantages in software development. In this paper, we are interested in the area of answer-set programming where fully declarative and nonmonotonic languages are applied. In this context, obtaining a modular structure for programs is by no means straightforward since the output of an entire program cannot in general be composed from the output of its components. To better understand the effects of disjunctive information on modularity we restrict the scope of analysis to the case of disjunctive logic programs (DLPs) subject to stable-model semantics. We define the notion of a DLP-function, where a well-defined input/output interface is provided, and establish a novel module theorem which indicates the compositionality of stable-model semantics for DLP-functions. The module theorem extends the well-known splitting-set theorem and enables the decomposition of DLP-functions given their strongly connected components based on positive dependencies induced by rules. In this setting, it is also possible to split shared disjunctive rules among components using a generalized shifting technique. The concept of modular equivalence is introduced for the mutual comparison of DLP-functions using a generalization of a translation-based verification method.
Utilizing ASP for Generating and Visualizing Argumentation Frameworks
Jan 08, 2013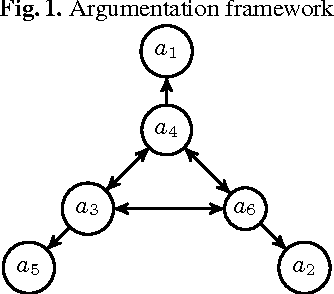
Within the area of computational models of argumentation, the instantiation-based approach is gaining more and more attention, not at least because meaningful input for Dung's abstract frameworks is provided in that way. In a nutshell, the aim of instantiation-based argumentation is to form, from a given knowledge base, a set of arguments and to identify the conflicts between them. The resulting network is then evaluated by means of extension-based semantics on an abstract level, i.e. on the resulting graph. While several systems are nowadays available for the latter step, the automation of the instantiation process itself has received less attention. In this work, we provide a novel approach to construct and visualize an argumentation framework from a given knowledge base. The system we propose relies on Answer-Set Programming and follows a two-step approach. A first program yields the logic-based arguments as its answer-sets; a second program is then used to specify the relations between arguments based on the answer-sets of the first program. As it turns out, this approach not only allows for a flexible and extensible tool for instantiation-based argumentation, but also provides a new method for answer-set visualization in general.
D-FLAT: Declarative Problem Solving Using Tree Decompositions and Answer-Set Programming
Oct 06, 2012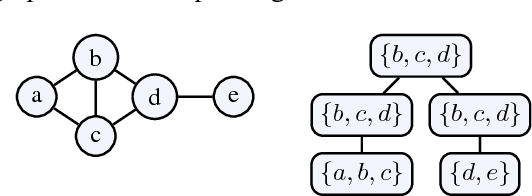

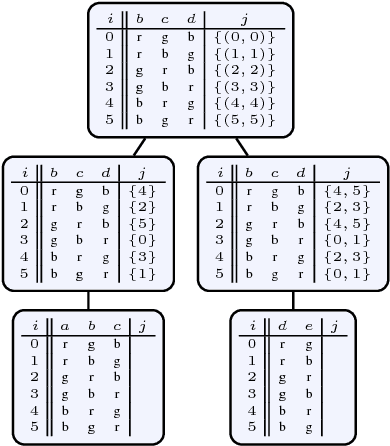

In this work, we propose Answer-Set Programming (ASP) as a tool for rapid prototyping of dynamic programming algorithms based on tree decompositions. In fact, many such algorithms have been designed, but only a few of them found their way into implementation. The main obstacle is the lack of easy-to-use systems which (i) take care of building a tree decomposition and (ii) provide an interface for declarative specifications of dynamic programming algorithms. In this paper, we present D-FLAT, a novel tool that relieves the user of having to handle all the technical details concerned with parsing, tree decomposition, the handling of data structures, etc. Instead, it is only the dynamic programming algorithm itself which has to be specified in the ASP language. D-FLAT employs an ASP solver in order to compute the local solutions in the dynamic programming algorithm. In the paper, we give a few examples illustrating the use of D-FLAT and describe the main features of the system. Moreover, we report experiments which show that ASP-based D-FLAT encodings for some problems outperform monolithic ASP encodings on instances of small treewidth.
Tractable Answer-Set Programming with Weight Constraints: Bounded Treewidth is not Enough
May 29, 2012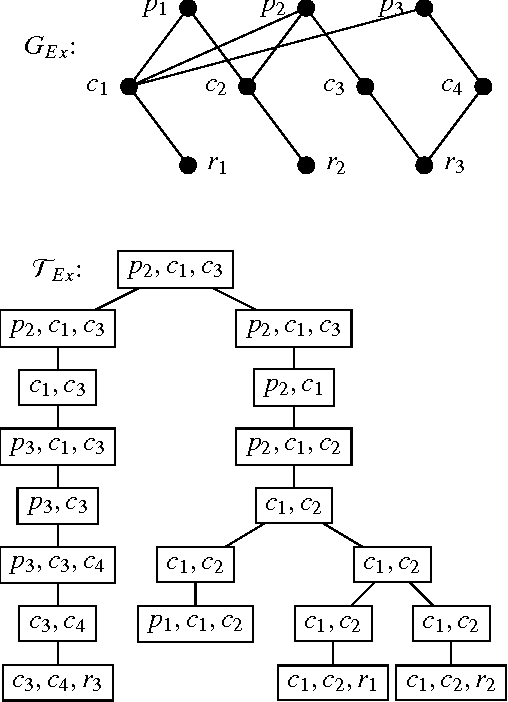
Cardinality constraints or, more generally, weight constraints are well recognized as an important extension of answer-set programming. Clearly, all common algorithmic tasks related to programs with cardinality or weight constraints - like checking the consistency of a program - are intractable. Many intractable problems in the area of knowledge representation and reasoning have been shown to become linear time tractable if the treewidth of the programs or formulas under consideration is bounded by some constant. The goal of this paper is to apply the notion of treewidth to programs with cardinality or weight constraints and to identify tractable fragments. It will turn out that the straightforward application of treewidth to such class of programs does not suffice to obtain tractability. However, by imposing further restrictions, tractability can be achieved.
* To appear in Theory and Practice of Logic Programming (TPLP)
Strong Equivalence of Qualitative Optimization Problems
Dec 04, 2011We introduce the framework of qualitative optimization problems (or, simply, optimization problems) to represent preference theories. The formalism uses separate modules to describe the space of outcomes to be compared (the generator) and the preferences on outcomes (the selector). We consider two types of optimization problems. They differ in the way the generator, which we model by a propositional theory, is interpreted: by the standard propositional logic semantics, and by the equilibrium-model (answer-set) semantics. Under the latter interpretation of generators, optimization problems directly generalize answer-set optimization programs proposed previously. We study strong equivalence of optimization problems, which guarantees their interchangeability within any larger context. We characterize several versions of strong equivalence obtained by restricting the class of optimization problems that can be used as extensions and establish the complexity of associated reasoning tasks. Understanding strong equivalence is essential for modular representation of optimization problems and rewriting techniques to simplify them without changing their inherent properties.
Making Use of Advances in Answer-Set Programming for Abstract Argumentation Systems
Aug 24, 2011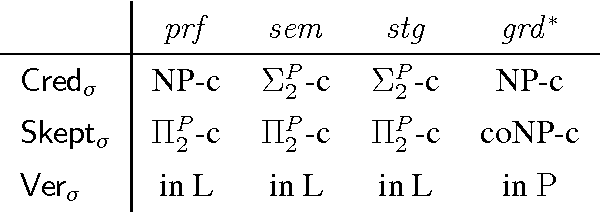
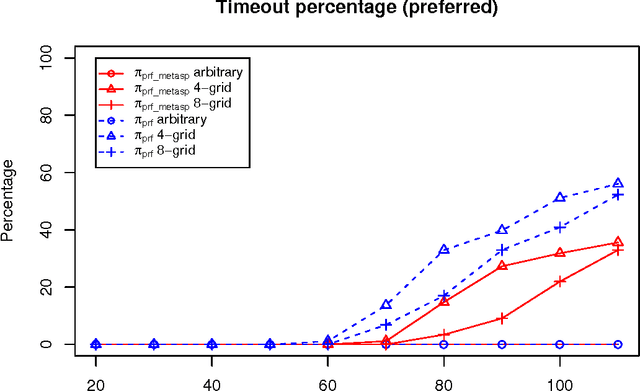
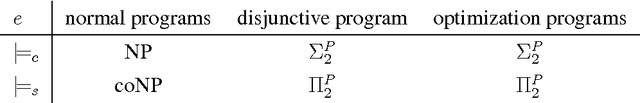
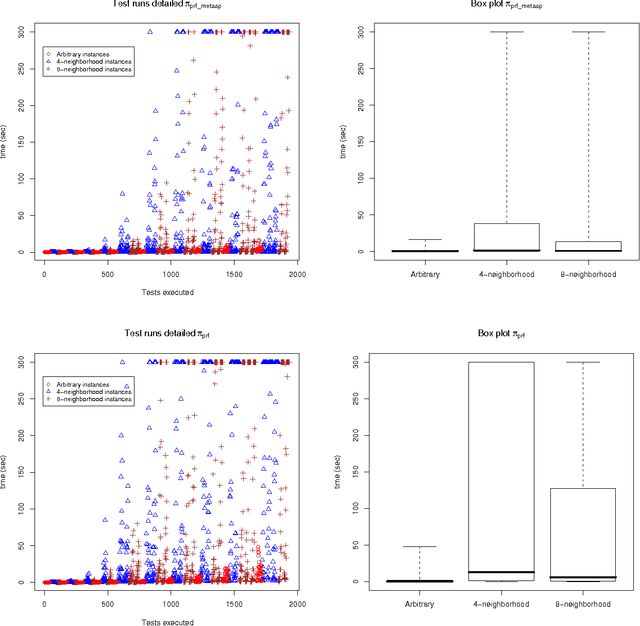
Dung's famous abstract argumentation frameworks represent the core formalism for many problems and applications in the field of argumentation which significantly evolved within the last decade. Recent work in the field has thus focused on implementations for these frameworks, whereby one of the main approaches is to use Answer-Set Programming (ASP). While some of the argumentation semantics can be nicely expressed within the ASP language, others required rather cumbersome encoding techniques. Recent advances in ASP systems, in particular, the metasp optimization frontend for the ASP-package gringo/claspD provides direct commands to filter answer sets satisfying certain subset-minimality (or -maximality) constraints. This allows for much simpler encodings compared to the ones in standard ASP language. In this paper, we experimentally compare the original encodings (for the argumentation semantics based on preferred, semi-stable, and respectively, stage extensions) with new metasp encodings. Moreover, we provide novel encodings for the recently introduced resolution-based grounded semantics. Our experimental results indicate that the metasp approach works well in those cases where the complexity of the encoded problem is adequately mirrored within the metasp approach.
dynPARTIX - A Dynamic Programming Reasoner for Abstract Argumentation
Aug 24, 2011
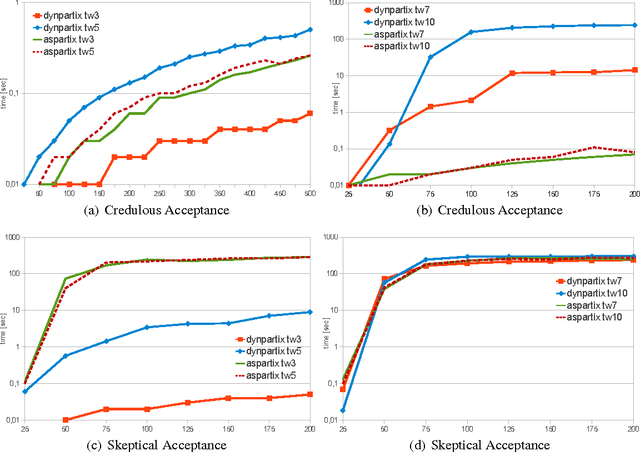
The aim of this paper is to announce the release of a novel system for abstract argumentation which is based on decomposition and dynamic programming. We provide first experimental evaluations to show the feasibility of this approach.
A general approach to belief change in answer set programming
Dec 30, 2009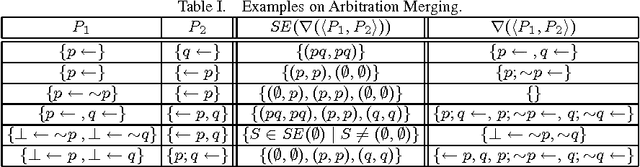
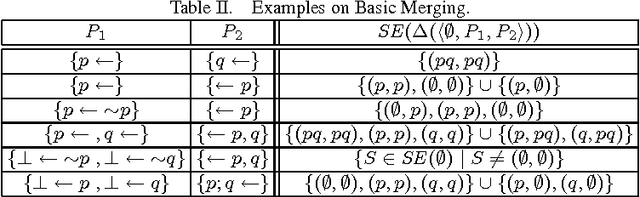
We address the problem of belief change in (nonmonotonic) logic programming under answer set semantics. Unlike previous approaches to belief change in logic programming, our formal techniques are analogous to those of distance-based belief revision in propositional logic. In developing our results, we build upon the model theory of logic programs furnished by SE models. Since SE models provide a formal, monotonic characterisation of logic programs, we can adapt techniques from the area of belief revision to belief change in logic programs. We introduce methods for revising and merging logic programs, respectively. For the former, we study both subset-based revision as well as cardinality-based revision, and we show that they satisfy the majority of the AGM postulates for revision. For merging, we consider operators following arbitration merging and IC merging, respectively. We also present encodings for computing the revision as well as the merging of logic programs within the same logic programming framework, giving rise to a direct implementation of our approach in terms of off-the-shelf answer set solvers. These encodings reflect in turn the fact that our change operators do not increase the complexity of the base formalism.
Relativized hyperequivalence of logic programs for modular programming
Jul 23, 2009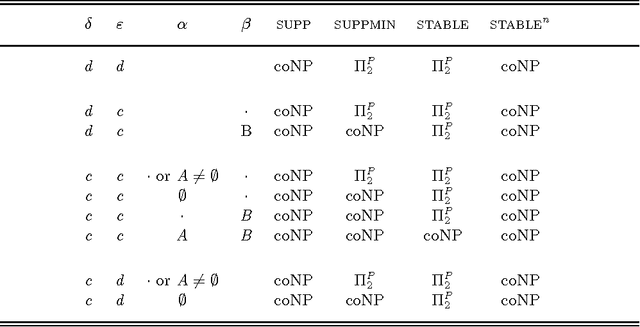
A recent framework of relativized hyperequivalence of programs offers a unifying generalization of strong and uniform equivalence. It seems to be especially well suited for applications in program optimization and modular programming due to its flexibility that allows us to restrict, independently of each other, the head and body alphabets in context programs. We study relativized hyperequivalence for the three semantics of logic programs given by stable, supported and supported minimal models. For each semantics, we identify four types of contexts, depending on whether the head and body alphabets are given directly or as the complement of a given set. Hyperequivalence relative to contexts where the head and body alphabets are specified directly has been studied before. In this paper, we establish the complexity of deciding relativized hyperequivalence with respect to the three other types of context programs. To appear in Theory and Practice of Logic Programming (TPLP).