 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Theory and Application of Contextual Optimal Transport
Feb 22, 2024



Optimal Transport (OT) has fueled machine learning (ML) applications across many domains. In cases where paired data measurements ($\mu$, $\nu$) are coupled to a context variable $p_i$ , one may aspire to learn a global transportation map that can be parameterized through a potentially unseen con-text. Existing approaches utilize Neural OT and largely rely on Brenier's theorem. Here, we propose a first-of-its-kind quantum computing formulation for amortized optimization of contextualized transportation plans. We exploit a direct link between doubly stochastic matrices and unitary operators thus finding a natural connection between OT and quantum computation. We verify our method on synthetic and real data, by predicting variations in cell type distributions parameterized through drug dosage as context. Our comparisons to several baselines reveal that our method can capture dose-induced variations in cell distributions, even to some extent when dosages are extrapolated and sometimes with performance similar to the best classical models. In summary, this is a first step toward learning to predict contextualized transportation plans through quantum.
Quantum Kernel Alignment with Stochastic Gradient Descent
Apr 19, 2023



Quantum support vector machines have the potential to achieve a quantum speedup for solving certain machine learning problems. The key challenge for doing so is finding good quantum kernels for a given data set -- a task called kernel alignment. In this paper we study this problem using the Pegasos algorithm, which is an algorithm that uses stochastic gradient descent to solve the support vector machine optimization problem. We extend Pegasos to the quantum case and and demonstrate its effectiveness for kernel alignment. Unlike previous work which performs kernel alignment by training a QSVM within an outer optimization loop, we show that using Pegasos it is possible to simultaneously train the support vector machine and align the kernel. Our experiments show that this approach is capable of aligning quantum feature maps with high accuracy, and outperforms existing quantum kernel alignment techniques. Specifically, we demonstrate that Pegasos is particularly effective for non-stationary data, which is an important challenge in real-world applications.
The complexity of quantum support vector machines
Feb 28, 2022
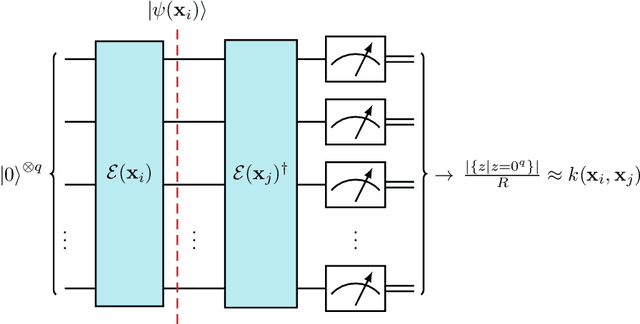
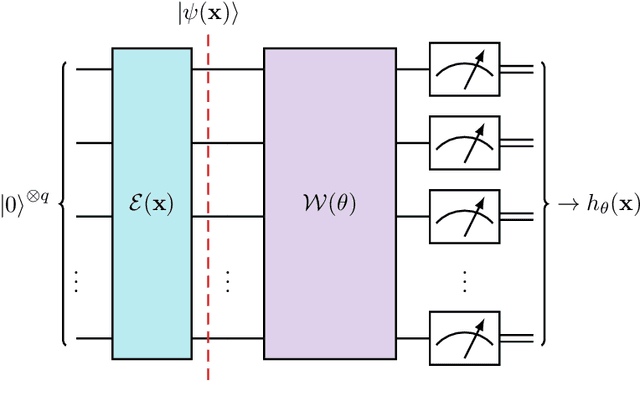

Quantum support vector machines employ quantum circuits to define the kernel function. It has been shown that this approach offers a provable exponential speedup compared to any known classical algorithm for certain data sets. The training of such models corresponds to solving a convex optimization problem either via its primal or dual formulation. Due to the probabilistic nature of quantum mechanics, the training algorithms are affected by statistical uncertainty, which has a major impact on their complexity. We show that the dual problem can be solved in $\mathcal{O}(M^{4.67}/\varepsilon^2)$ quantum circuit evaluations, where $M$ denotes the size of the data set and $\varepsilon$ the solution accuracy. We prove under an empirically motivated assumption that the kernelized primal problem can alternatively be solved in $\mathcal{O}(\min \{ M^2/\varepsilon^6, \, 1/\varepsilon^{10} \})$ evaluations by employing a generalization of a known classical algorithm called Pegasos. Accompanying empirical results demonstrate these analytical complexities to be essentially tight. In addition, we investigate a variational approximation to quantum support vector machines and show that their heuristic training achieves considerably better scaling in our experiments.
Effective dimension of machine learning models
Dec 09, 2021
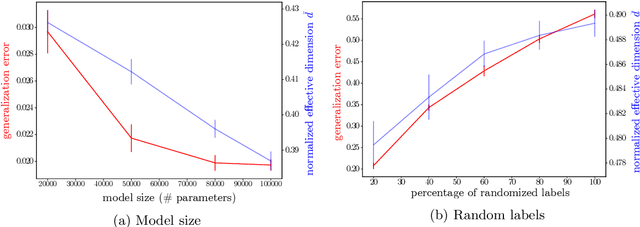
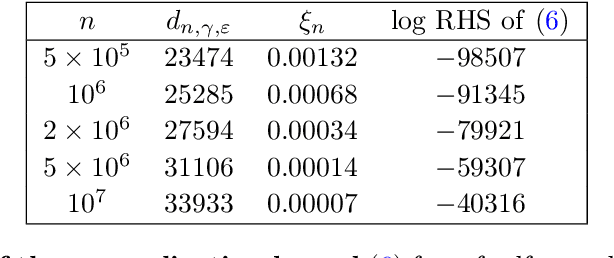
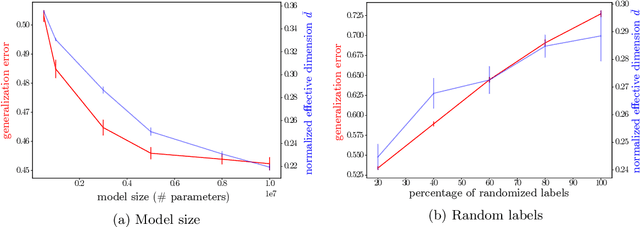
Making statements about the performance of trained models on tasks involving new data is one of the primary goals of machine learning, i.e., to understand the generalization power of a model. Various capacity measures try to capture this ability, but usually fall short in explaining important characteristics of models that we observe in practice. In this study, we propose the local effective dimension as a capacity measure which seems to correlate well with generalization error on standard data sets. Importantly, we prove that the local effective dimension bounds the generalization error and discuss the aptness of this capacity measure for machine learning models.
The power of quantum neural networks
Oct 30, 2020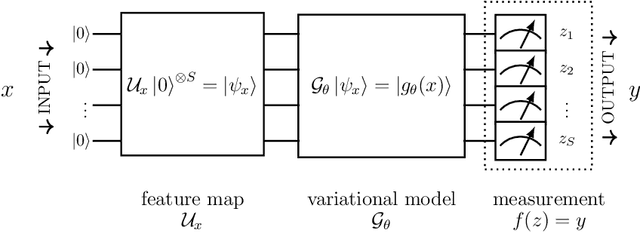
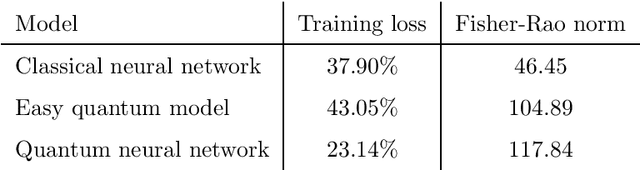
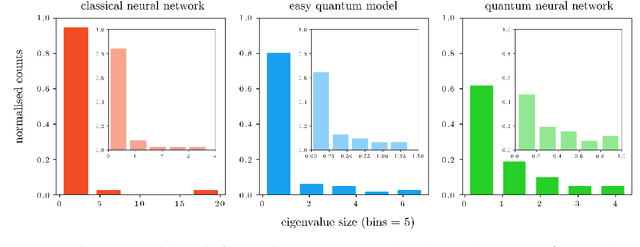
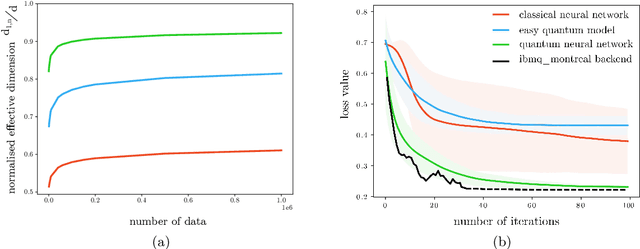
Fault-tolerant quantum computers offer the promise of dramatically improving machine learning through speed-ups in computation or improved model scalability. In the near-term, however, the benefits of quantum machine learning are not so clear. Understanding expressibility and trainability of quantum models-and quantum neural networks in particular-requires further investigation. In this work, we use tools from information geometry to define a notion of expressibility for quantum and classical models. The effective dimension, which depends on the Fisher information, is used to prove a novel generalisation bound and establish a robust measure of expressibility. We show that quantum neural networks are able to achieve a significantly better effective dimension than comparable classical neural networks. To then assess the trainability of quantum models, we connect the Fisher information spectrum to barren plateaus, the problem of vanishing gradients. Importantly, certain quantum neural networks can show resilience to this phenomenon and train faster than classical models due to their favourable optimisation landscapes, captured by a more evenly spread Fisher information spectrum. Our work is the first to demonstrate that well-designed quantum neural networks offer an advantage over classical neural networks through a higher effective dimension and faster training ability, which we verify on real quantum hardware.