 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Framework for Post-disruption Travel Time Prediction in Metro Networks
Feb 23, 2026Disruptions are an inherent feature of transportation systems, occurring unpredictably and with varying durations. Even after an incident is reported as resolved, disruptions can induce irregular train operations that generate substantial uncertainty in passenger waiting and travel times. Accurately forecasting post-disruption travel times therefore remains a critical challenge for transit operators and passenger information systems. This paper develops a Bayesian spatiotemporal modeling framework for post-disruption train travel times that explicitly captures train interactions, headway imbalance, and non-Gaussian distributional characteristics observed during recovery periods. The proposed model decomposes travel times into delay and journey components and incorporates a moving-average error structure to represent dependence between consecutive trains. Skew-normal and skew-$t$ distributions are employed to flexibly accommodate heteroskedasticity, skewness, and heavy-tailed behavior in post-disruption travel times. The framework is evaluated using high-resolution track-occupancy and disruption log data from the Montréal metro system, covering two lines in both travel directions. Empirical results indicate that post-disruption travel times exhibit pronounced distributional asymmetries that vary with traveled distance, as well as significant error dependence across trains. The proposed models consistently outperform baseline specifications in both point prediction accuracy and uncertainty quantification, with the skew-$t$ model demonstrating the most robust performance for longer journeys. These findings underscore the importance of incorporating both distributional flexibility and error dependence when forecasting post-disruption travel times in urban rail systems.
Nearest Labelset Using Double Distances for Multi-label Classification
Feb 15, 2017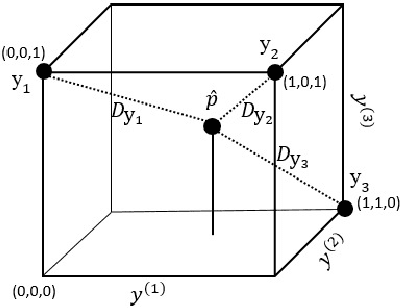
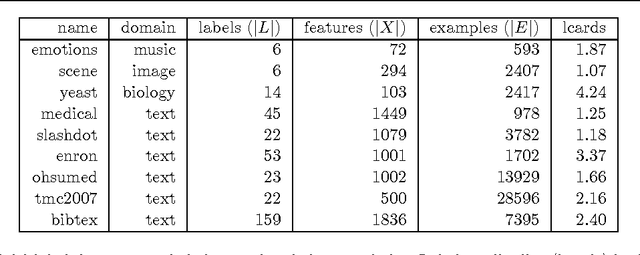
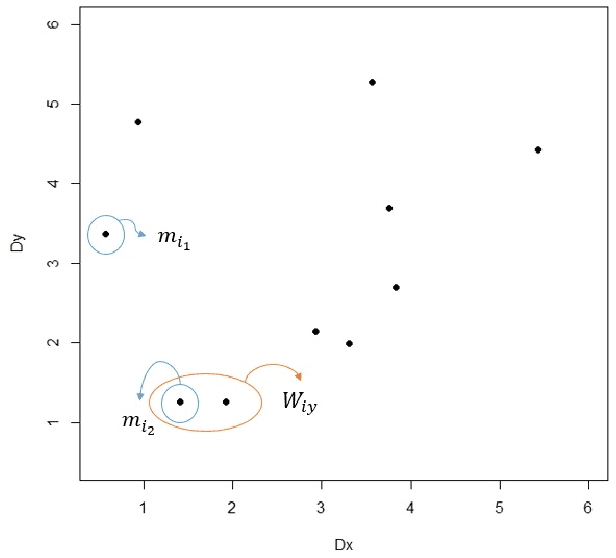
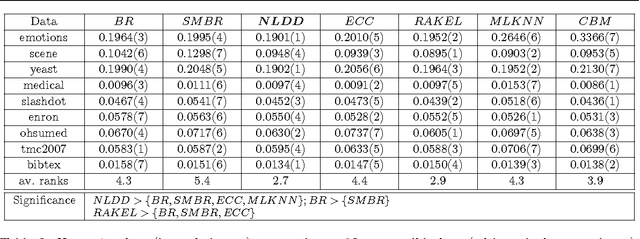
Multi-label classification is a type of supervised learning where an instance may belong to multiple labels simultaneously. Predicting each label independently has been criticized for not exploiting any correlation between labels. In this paper we propose a novel approach, Nearest Labelset using Double Distances (NLDD), that predicts the labelset observed in the training data that minimizes a weighted sum of the distances in both the feature space and the label space to the new instance. The weights specify the relative tradeoff between the two distances. The weights are estimated from a binomial regression of the number of misclassified labels as a function of the two distances. Model parameters are estimated by maximum likelihood. NLDD only considers labelsets observed in the training data, thus implicitly taking into account label dependencies. Experiments on benchmark multi-label data sets show that the proposed method on average outperforms other well-known approaches in terms of Hamming loss, 0/1 loss, and multi-label accuracy and ranks second after ECC on the F-measure.