 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarine Mammal Species Classification using Convolutional Neural Networks and a Novel Acoustic Representation
Jul 30, 2019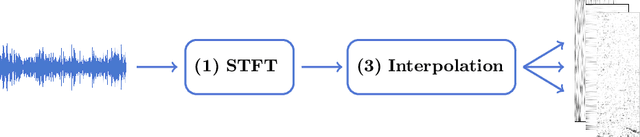
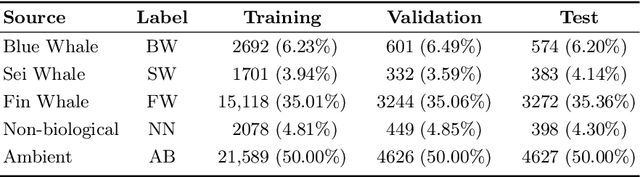
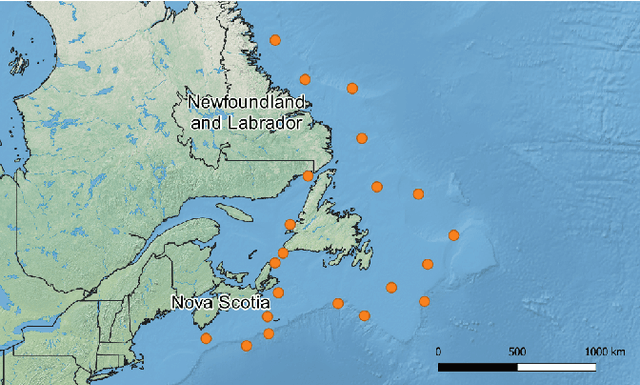
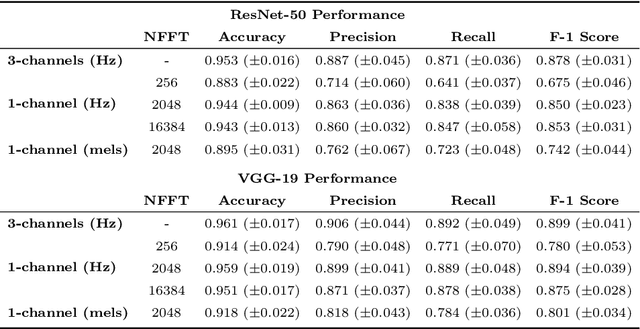
Research into automated systems for detecting and classifying marine mammals in acoustic recordings is expanding internationally due to the necessity to analyze large collections of data for conservation purposes. In this work, we present a Convolutional Neural Network that is capable of classifying the vocalizations of three species of whales, non-biological sources of noise, and a fifth class pertaining to ambient noise. In this way, the classifier is capable of detecting the presence and absence of whale vocalizations in an acoustic recording. Through transfer learning, we show that the classifier is capable of learning high-level representations and can generalize to additional species. We also propose a novel representation of acoustic signals that builds upon the commonly used spectrogram representation by way of interpolating and stacking multiple spectrograms produced using different Short-time Fourier Transform (STFT) parameters. The proposed representation is particularly effective for the task of marine mammal species classification where the acoustic events we are attempting to classify are sensitive to the parameters of the STFT.
Efficient Neural Task Adaptation by Maximum Entropy Initialization
May 25, 2019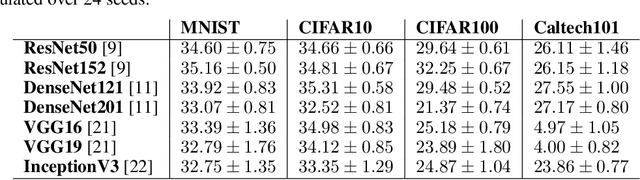
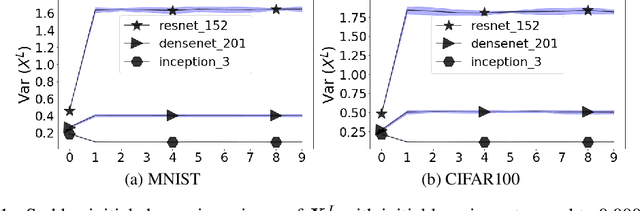
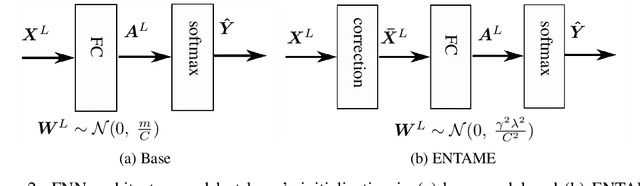
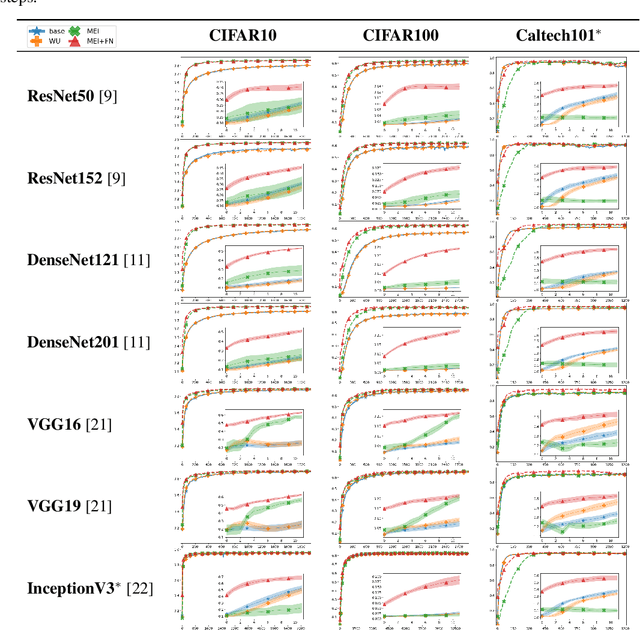
Transferring knowledge from one neural network to another has been shown to be helpful for learning tasks with few training examples. Prevailing fine-tuning methods could potentially contaminate pre-trained features by comparably high energy random noise. This noise is mainly delivered from a careless replacement of task-specific parameters. We analyze theoretically such knowledge contamination for classification tasks and propose a practical and easy to apply method to trap and minimize the contaminant. In our approach, the entropy of the output estimates gets maximized initially and the first back-propagated error is stalled at the output of the last layer. Our proposed method not only outperforms the traditional fine-tuning, but also significantly speeds up the convergence of the learner. It is robust to randomness and independent of the choice of architecture. Overall, our experiments show that the power of transfer learning has been substantially underestimated so far.
When a Tweet is Actually Sexist. A more Comprehensive Classification of Different Online Harassment Categories and The Challenges in NLP
Feb 27, 2019
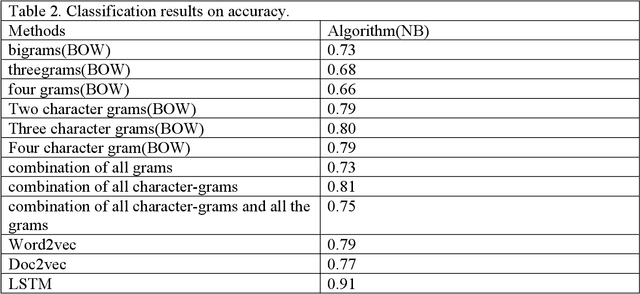
Sexism is very common in social media and makes the boundaries of freedom tighter for feminist and female users. There is still no comprehensive classification of sexism attracting natural language processing techniques. Categorizing sexism in social media in the categories of hostile or benevolent sexism are so general that simply ignores the other types of sexism happening in these media. This paper proposes a more comprehensive and in-depth categories of online harassment in social media e.g. twitter into the following categories, "Indirect harassment", "Information threat", "sexual harassment", "Physical harassment" and "Not sexist" and address the challenge of labeling them along with presenting the classification result of the categories. It is preliminary work applying machine learning to learn the concept of sexism and distinguishes itself by looking at more precise categories of sexism in social media.
Recurrent Neural Networks with Stochastic Layers for Acoustic Novelty Detection
Feb 13, 2019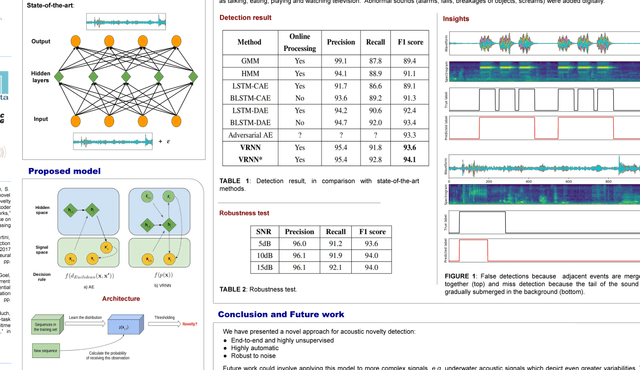
In this paper, we adapt Recurrent Neural Networks with Stochastic Layers, which are the state-of-the-art for generating text, music and speech, to the problem of acoustic novelty detection. By integrating uncertainty into the hidden states, this type of network is able to learn the distribution of complex sequences. Because the learned distribution can be calculated explicitly in terms of probability, we can evaluate how likely an observation is then detect low-probability events as novel. The model is robust, highly unsupervised, end-to-end and requires minimum preprocessing, feature engineering or hyperparameter tuning. An experiment on a benchmark dataset shows that our model outperforms the state-of-the-art acoustic novelty detectors.
2-D Embedding of Large and High-dimensional Data with Minimal Memory and Computational Time Requirements
Feb 04, 2019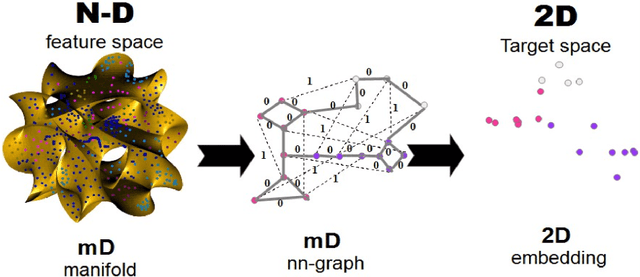

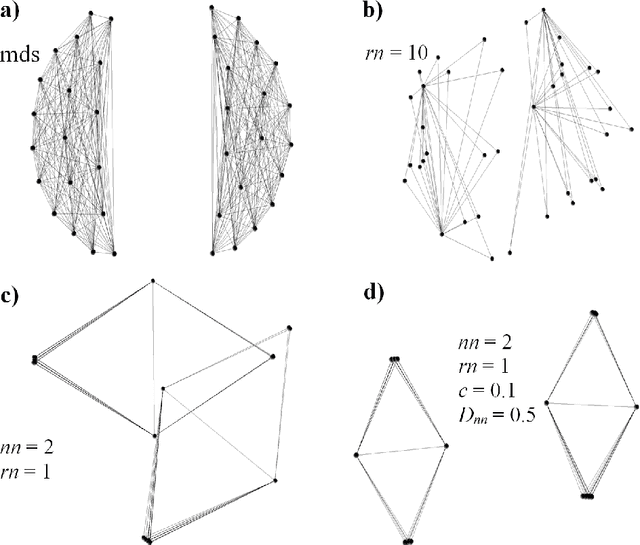

In the advent of big data era, interactive visualization of large data sets consisting of M*10^5+ high-dimensional feature vectors of length N (N ~ 10^3+), is an indispensable tool for data exploratory analysis. The state-of-the-art data embedding (DE) methods of N-D data into 2-D (3-D) visually perceptible space (e.g., based on t-SNE concept) are too demanding computationally to be efficiently employed for interactive data analytics of large and high-dimensional datasets. Herein we present a simple method, ivhd (interactive visualization of high-dimensional data tool), which radically outperforms the modern data-embedding algorithms in both computational and memory loads, while retaining high quality of N-D data embedding in 2-D (3-D). We show that DE problem is equivalent to the nearest neighbor nn-graph visualization, where only indices of a few nearest neighbors of each data sample has to be known, and binary distance between data samples -- 0 to the nearest and 1 to the other samples -- is defined. These improvements reduce the time-complexity and memory load from O(M log M) to O(M), and ensure minimal O(M) proportionality coefficient as well. We demonstrate high efficiency, quality and robustness of ivhd on popular benchmark datasets such as MNIST, 20NG, NORB and RCV1.
How is Your Mood When Writing Sexist tweets? Detecting the Emotion Type and Intensity of Emotion Using Natural Language Processing Techniques
Jan 28, 2019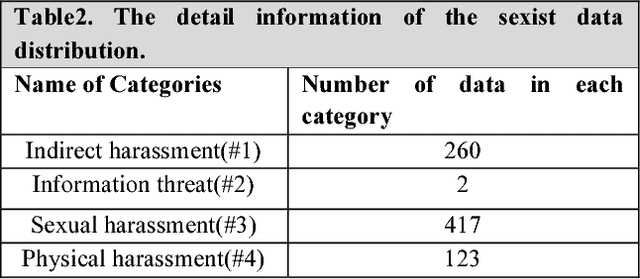
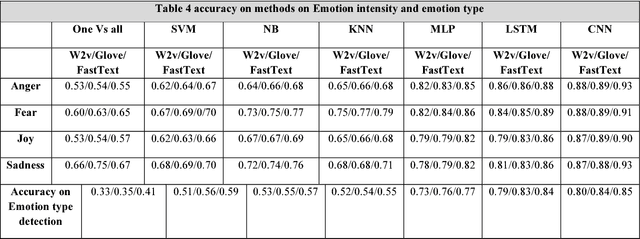
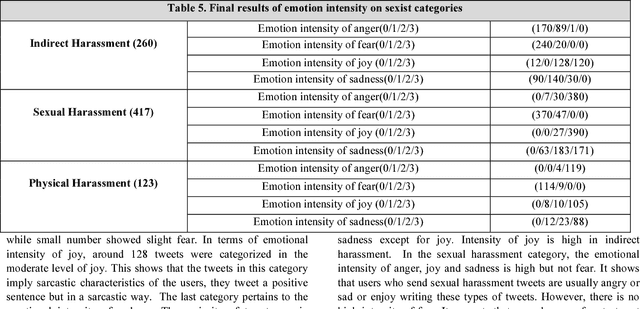
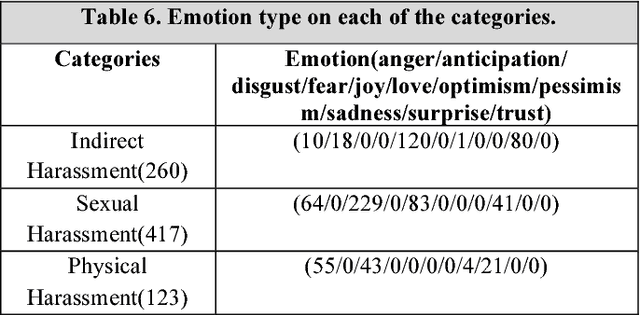
Online social platforms have been the battlefield of users with different emotions and attitudes toward each other in recent years. While sexism has been considered as a category of hateful speech in the literature, there is no comprehensive definition and category of sexism attracting natural language processing techniques. Categorizing sexism as either benevolent or hostile sexism is so broad that it easily ignores the other categories of sexism on social media. Sharifirad S and Matwin S 2018 proposed a well-defined category of sexism including indirect harassment, information threat, sexual harassment and physical harassment, inspired from social science for the purpose of natural language processing techniques. In this article, we take advantage of a newly released dataset in SemEval-2018 task1: Affect in tweets, to show the type of emotion and intensity of emotion in each category. We train, test and evaluate different classification methods on the SemEval- 2018 dataset and choose the classifier with highest accuracy for testing on each category of sexist tweets to know the mental state and the affectual state of the user who tweets in each category. It is a nice avenue to explore because not all the tweets are directly sexist and they carry different emotions from the users. This is the first work experimenting on affect detection this in depth on sexist tweets. Based on our best knowledge they are all new contributions to the field; we are the first to demonstrate the power of such in-depth sentiment analysis on the sexist tweets.
Improving the Interpretability of Deep Neural Networks with Knowledge Distillation
Dec 28, 2018
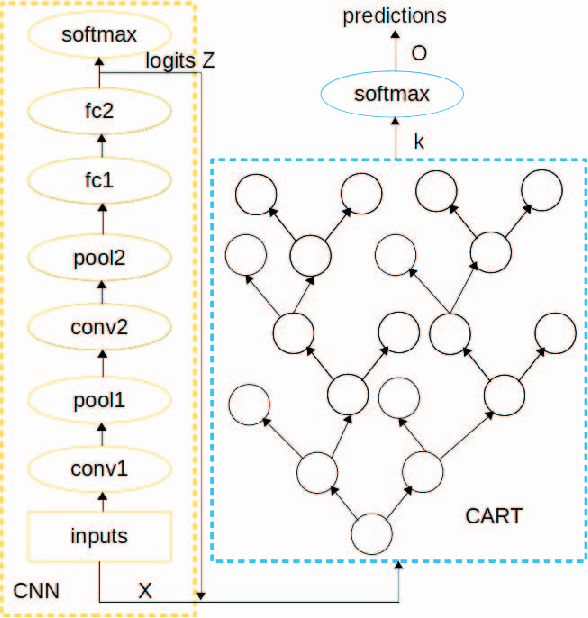
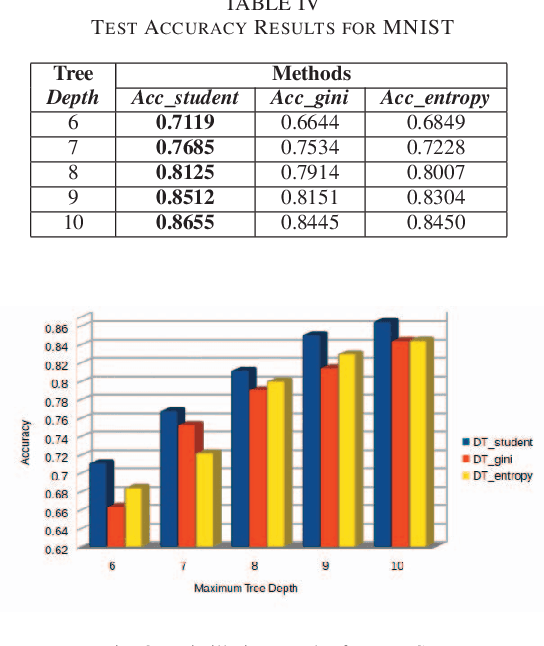
Deep Neural Networks have achieved huge success at a wide spectrum of applications from language modeling, computer vision to speech recognition. However, nowadays, good performance alone is not sufficient to satisfy the needs of practical deployment where interpretability is demanded for cases involving ethics and mission critical applications. The complex models of Deep Neural Networks make it hard to understand and reason the predictions, which hinders its further progress. To tackle this problem, we apply the Knowledge Distillation technique to distill Deep Neural Networks into decision trees in order to attain good performance and interpretability simultaneously. We formulate the problem at hand as a multi-output regression problem and the experiments demonstrate that the student model achieves significantly better accuracy performance (about 1\% to 5\%) than vanilla decision trees at the same level of tree depth. The experiments are implemented on the TensorFlow platform to make it scalable to big datasets. To the best of our knowledge, we are the first to distill Deep Neural Networks into vanilla decision trees on multi-class datasets.
On feature selection and evaluation of transportation mode prediction strategies
Sep 05, 2018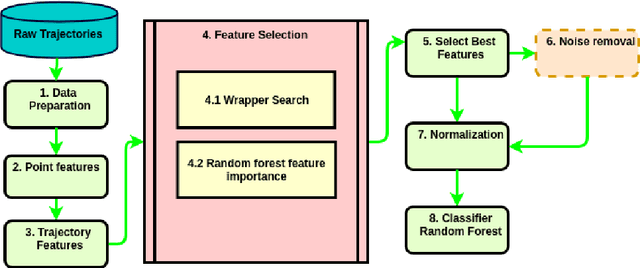
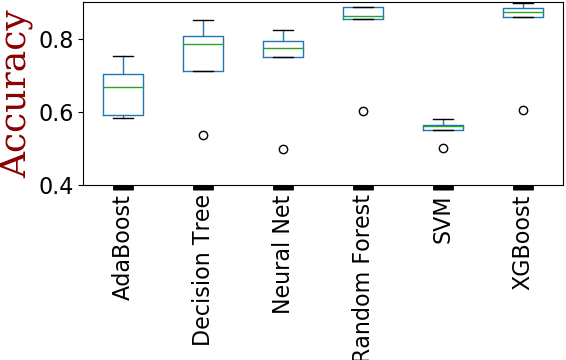
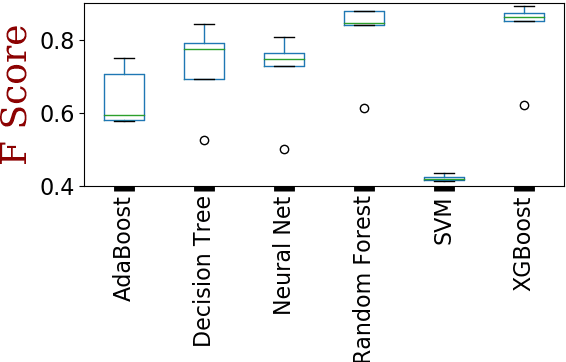
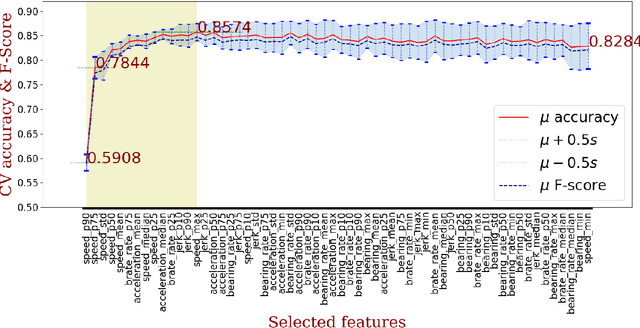
Transportation modes prediction is a fundamental task for decision making in smart cities and traffic management systems. Traffic policies designed based on trajectory mining can save money and time for authorities and the public. It may reduce the fuel consumption and commute time and moreover, may provide more pleasant moments for residents and tourists. Since the number of features that may be used to predict a user transportation mode can be substantial, finding a subset of features that maximizes a performance measure is worth investigating. In this work, we explore wrapper and information retrieval methods to find the best subset of trajectory features. After finding the best classifier and the best feature subset, our results were compared with two related papers that applied deep learning methods and the results showed that our framework achieved better performance. Furthermore, two types of cross-validation approaches were investigated, and the performance results show that the random cross-validation method provides optimistic results.
Interpretable Deep Convolutional Neural Networks via Meta-learning
Aug 19, 2018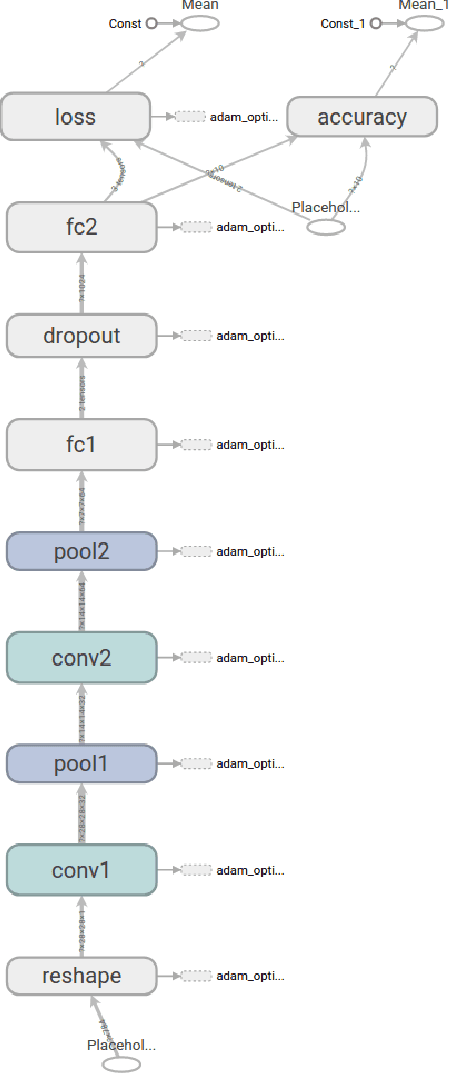
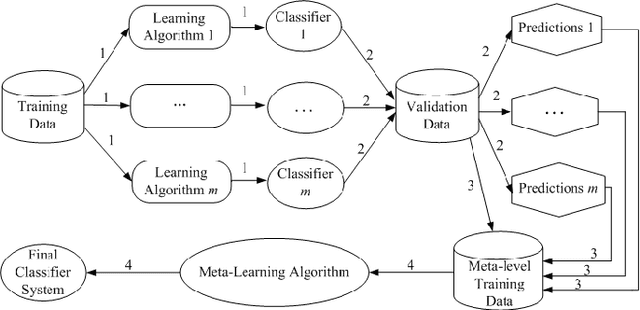
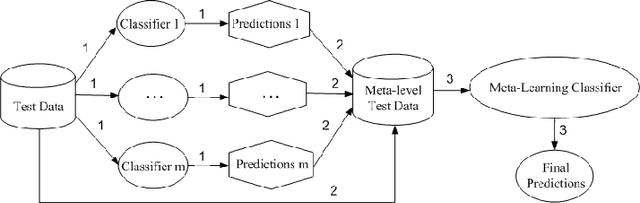
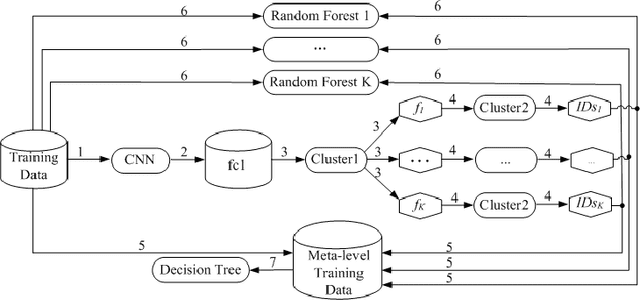
Model interpretability is a requirement in many applications in which crucial decisions are made by users relying on a model's outputs. The recent movement for "algorithmic fairness" also stipulates explainability, and therefore interpretability of learning models. And yet the most successful contemporary Machine Learning approaches, the Deep Neural Networks, produce models that are highly non-interpretable. We attempt to address this challenge by proposing a technique called CNN-INTE to interpret deep Convolutional Neural Networks (CNN) via meta-learning. In this work, we interpret a specific hidden layer of the deep CNN model on the MNIST image dataset. We use a clustering algorithm in a two-level structure to find the meta-level training data and Random Forest as base learning algorithms to generate the meta-level test data. The interpretation results are displayed visually via diagrams, which clearly indicates how a specific test instance is classified. Our method achieves global interpretation for all the test instances without sacrificing the accuracy obtained by the original deep CNN model. This means our model is faithful to the deep CNN model, which leads to reliable interpretations.
On the Importance of Attention in Meta-Learning for Few-Shot Text Classification
Jun 03, 2018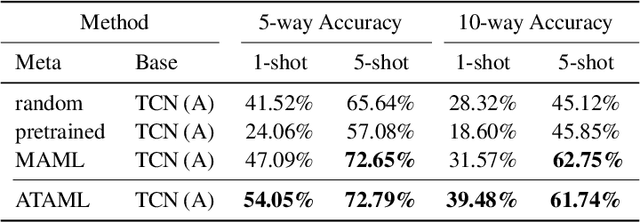
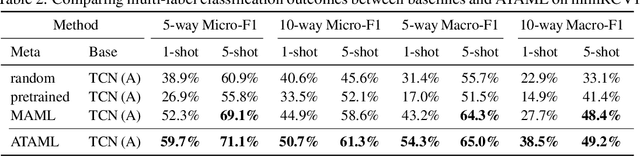
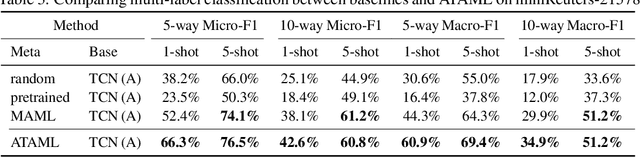
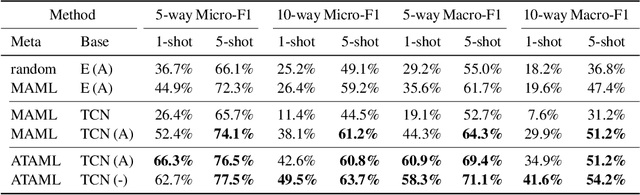
Current deep learning based text classification methods are limited by their ability to achieve fast learning and generalization when the data is scarce. We address this problem by integrating a meta-learning procedure that uses the knowledge learned across many tasks as an inductive bias towards better natural language understanding. Based on the Model-Agnostic Meta-Learning framework (MAML), we introduce the Attentive Task-Agnostic Meta-Learning (ATAML) algorithm for text classification. The essential difference between MAML and ATAML is in the separation of task-agnostic representation learning and task-specific attentive adaptation. The proposed ATAML is designed to encourage task-agnostic representation learning by way of task-agnostic parameterization and facilitate task-specific adaptation via attention mechanisms. We provide evidence to show that the attention mechanism in ATAML has a synergistic effect on learning performance. In comparisons with models trained from random initialization, pretrained models and meta trained MAML, our proposed ATAML method generalizes better on single-label and multi-label classification tasks in miniRCV1 and miniReuters-21578 datasets.