 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Neural Networks with Joint Quantization and Pruning of Weights and Activations
Nov 01, 2021
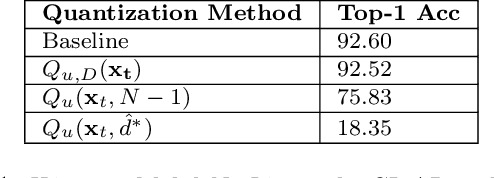
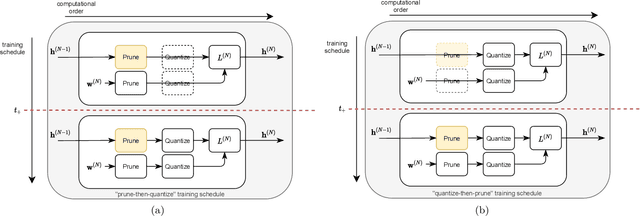

Quantization and pruning are core techniques used to reduce the inference costs of deep neural networks. State-of-the-art quantization techniques are currently applied to both the weights and activations; however, pruning is most often applied to only the weights of the network. In this work, we jointly apply novel uniform quantization and unstructured pruning methods to both the weights and activations of deep neural networks during training. Using our methods, we empirically evaluate the currently accepted prune-then-quantize paradigm across a wide range of computer vision tasks and observe a non-commutative nature when applied to both the weights and activations of deep neural networks. Informed by these observations, we articulate the non-commutativity hypothesis: for a given deep neural network being trained for a specific task, there exists an exact training schedule in which quantization and pruning can be introduced to optimize network performance. We identify that this optimal ordering not only exists, but also varies across discriminative and generative tasks. Using the optimal training schedule within our training framework, we demonstrate increased performance per memory footprint over existing solutions.
Tuning Confidence Bound for Stochastic Bandits with Bandit Distance
Oct 06, 2021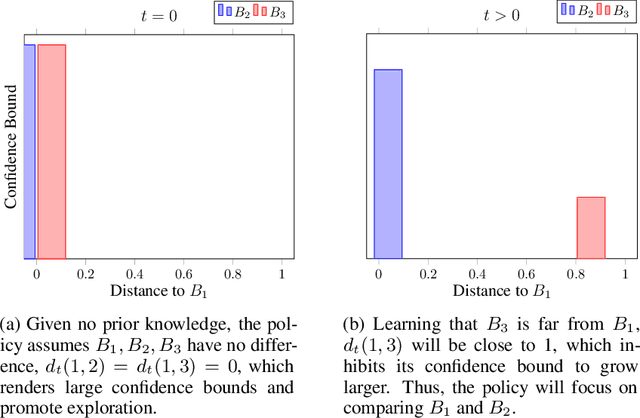
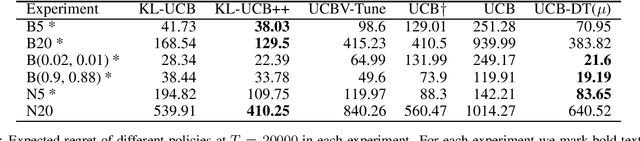
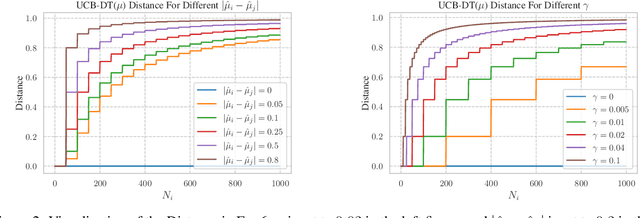
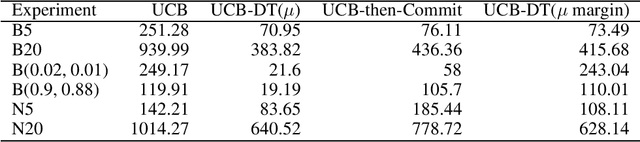
We propose a novel modification of the standard upper confidence bound (UCB) method for the stochastic multi-armed bandit (MAB) problem which tunes the confidence bound of a given bandit based on its distance to others. Our UCB distance tuning (UCB-DT) formulation enables improved performance as measured by expected regret by preventing the MAB algorithm from focusing on non-optimal bandits which is a well-known deficiency of standard UCB. "Distance tuning" of the standard UCB is done using a proposed distance measure, which we call bandit distance, that is parameterizable and which therefore can be optimized to control the transition rate from exploration to exploitation based on problem requirements. We empirically demonstrate increased performance of UCB-DT versus many existing state-of-the-art methods which use the UCB formulation for the MAB problem. Our contribution also includes the development of a conceptual tool called the "Exploration Bargain Point" which gives insights into the tradeoffs between exploration and exploitation. We argue that the Exploration Bargain Point provides an intuitive perspective that is useful for comparatively analyzing the performance of UCB-based methods.
Kernel distance measures for time series, random fields and other structured data
Sep 29, 2021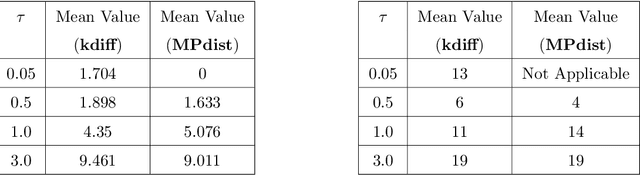
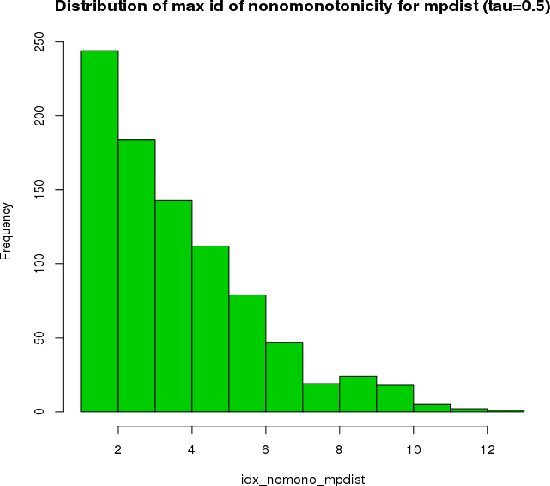
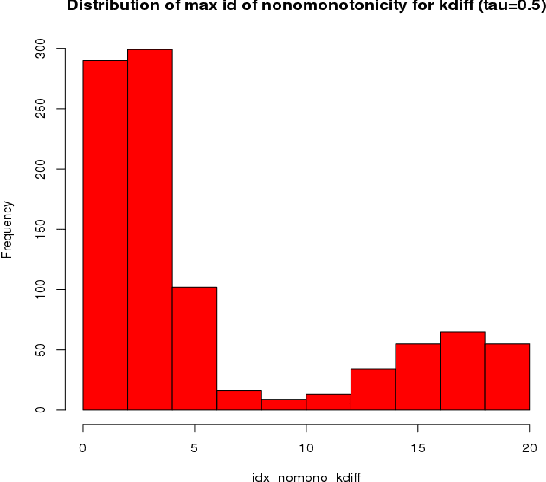
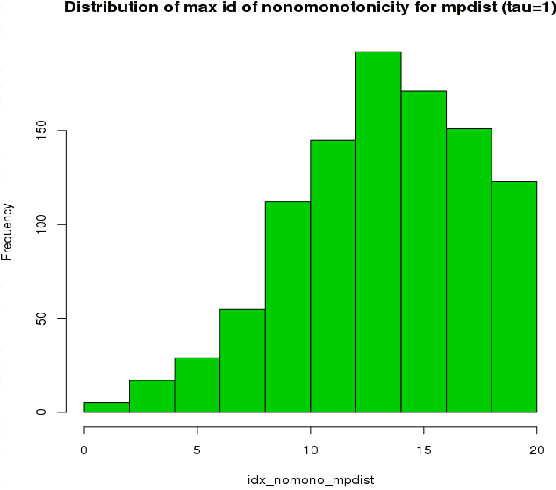
This paper introduces kdiff, a novel kernel-based measure for estimating distances between instances of time series, random fields and other forms of structured data. This measure is based on the idea of matching distributions that only overlap over a portion of their region of support. Our proposed measure is inspired by MPdist which has been previously proposed for such datasets and is constructed using Euclidean metrics, whereas kdiff is constructed using non-linear kernel distances. Also, kdiff accounts for both self and cross similarities across the instances and is defined using a lower quantile of the distance distribution. Comparing the cross similarity to self similarity allows for measures of similarity that are more robust to noise and partial occlusions of the relevant signals. Our proposed measure kdiff is a more general form of the well known kernel-based Maximum Mean Discrepancy (MMD) distance estimated over the embeddings. Some theoretical results are provided for separability conditions using kdiff as a distance measure for clustering and classification problems where the embedding distributions can be modeled as two component mixtures. Applications are demonstrated for clustering of synthetic and real-life time series and image data, and the performance of kdiff is compared to competing distance measures for clustering.
An Energy-Efficient Edge Computing Paradigm for Convolution-based Image Upsampling
Jul 26, 2021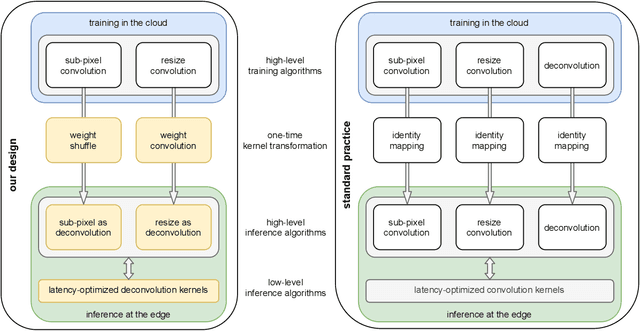

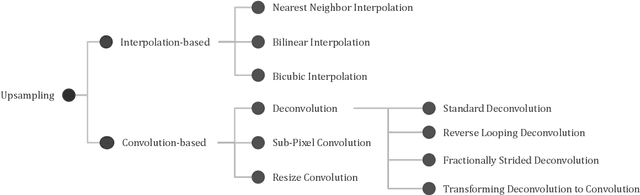

A novel energy-efficient edge computing paradigm is proposed for real-time deep learning-based image upsampling applications. State-of-the-art deep learning solutions for image upsampling are currently trained using either resize or sub-pixel convolution to learn kernels that generate high fidelity images with minimal artifacts. However, performing inference with these learned convolution kernels requires memory-intensive feature map transformations that dominate time and energy costs in real-time applications. To alleviate this pressure on memory bandwidth, we confine the use of resize or sub-pixel convolution to training in the cloud by transforming learned convolution kernels to deconvolution kernels before deploying them for inference as a functionally equivalent deconvolution. These kernel transformations, intended as a one-time cost when shifting from training to inference, enable a systems designer to use each algorithm in their optimal context by preserving the image fidelity learned when training in the cloud while minimizing data transfer penalties during inference at the edge. We also explore existing variants of deconvolution inference algorithms and introduce a novel variant for consideration. We analyze and compare the inference properties of convolution-based upsampling algorithms using a quantitative model of incurred time and energy costs and show that using deconvolution for inference at the edge improves both system latency and energy efficiency when compared to their sub-pixel or resize convolution counterparts.
Generative and Discriminative Deep Belief Network Classifiers: Comparisons Under an Approximate Computing Framework
Jan 31, 2021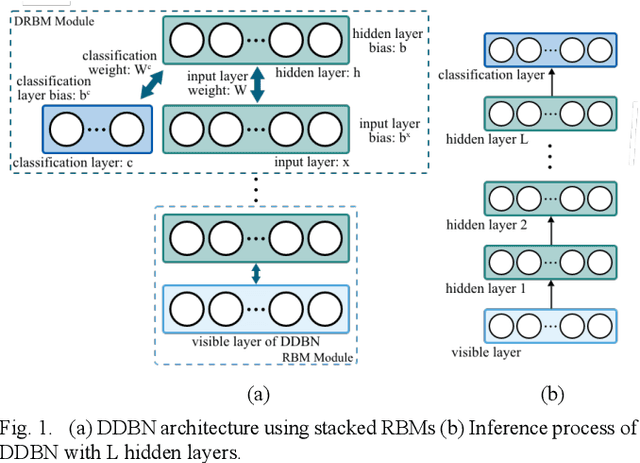

The use of Deep Learning hardware algorithms for embedded applications is characterized by challenges such as constraints on device power consumption, availability of labeled data, and limited internet bandwidth for frequent training on cloud servers. To enable low power implementations, we consider efficient bitwidth reduction and pruning for the class of Deep Learning algorithms known as Discriminative Deep Belief Networks (DDBNs) for embedded-device classification tasks. We train DDBNs with both generative and discriminative objectives under an approximate computing framework and analyze their power-at-performance for supervised and semi-supervised applications. We also investigate the out-of-distribution performance of DDBNs when the inference data has the same class structure yet is statistically different from the training data owing to dynamic real-time operating environments. Based on our analysis, we provide novel insights and recommendations for choice of training objectives, bitwidth values, and accuracy sensitivity with respect to the amount of labeled data for implementing DDBN inference with minimum power consumption on embedded hardware platforms subject to accuracy tolerances.
A Competitive Edge: Can FPGAs Beat GPUs at DCNN Inference Acceleration in Resource-Limited Edge Computing Applications?
Jan 30, 2021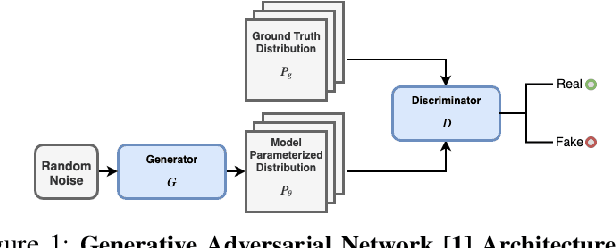
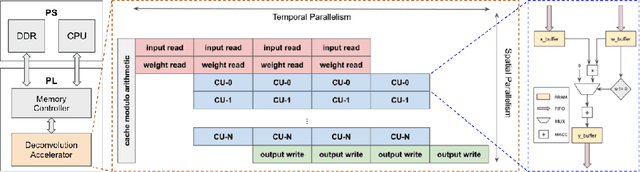
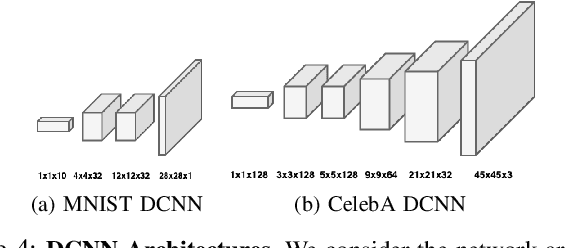
When trained as generative models, Deep Learning algorithms have shown exceptional performance on tasks involving high dimensional data such as image denoising and super-resolution. In an increasingly connected world dominated by mobile and edge devices, there is surging demand for these algorithms to run locally on embedded platforms. FPGAs, by virtue of their reprogrammability and low-power characteristics, are ideal candidates for these edge computing applications. As such, we design a spatio-temporally parallelized hardware architecture capable of accelerating a deconvolution algorithm optimized for power-efficient inference on a resource-limited FPGA. We propose this FPGA-based accelerator to be used for Deconvolutional Neural Network (DCNN) inference in low-power edge computing applications. To this end, we develop methods that systematically exploit micro-architectural innovations, design space exploration, and statistical analysis. Using a Xilinx PYNQ-Z2 FPGA, we leverage our architecture to accelerate inference for two DCNNs trained on the MNIST and CelebA datasets using the Wasserstein GAN framework. On these networks, our FPGA design achieves a higher throughput to power ratio with lower run-to-run variation when compared to the NVIDIA Jetson TX1 edge computing GPU.
PT-MMD: A Novel Statistical Framework for the Evaluation of Generative Systems
Oct 28, 2019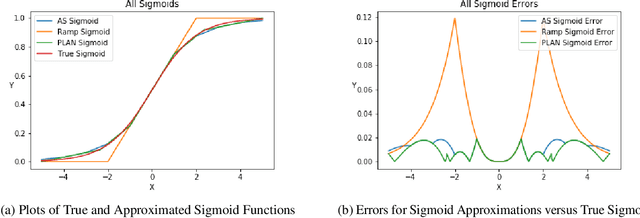

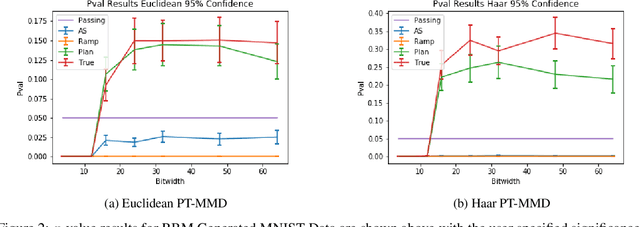

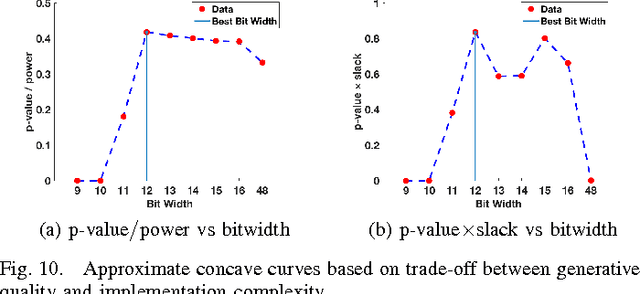
Stochastic-sampling-based Generative Neural Networks, such as Restricted Boltzmann Machines and Generative Adversarial Networks, are now used for applications such as denoising, image occlusion removal, pattern completion, and motion synthesis. In scenarios which involve performing such inference tasks with these models, it is critical to determine metrics that allow for model selection and/or maintenance of requisite generative performance under pre-specified implementation constraints. In this paper, we propose a new metric for evaluating generative model performance based on $p$-values derived from the combined use of Maximum Mean Discrepancy (MMD) and permutation-based (PT-based) resampling, which we refer to as PT-MMD. We demonstrate the effectiveness of this metric for two cases: (1) Selection of bitwidth and activation function complexity to achieve minimum power-at-performance for Restricted Boltzmann Machines; (2) Quantitative comparison of images generated by two types of Generative Adversarial Networks (PGAN and WGAN) to facilitate model selection in order to maximize the fidelity of generated images. For these applications, our results are shown using Euclidean and Haar-based kernels for the PT-MMD two sample hypothesis test. This demonstrates the critical role of distance functions in comparing generated images against their corresponding ground truth counterparts as what would be perceived by human users.
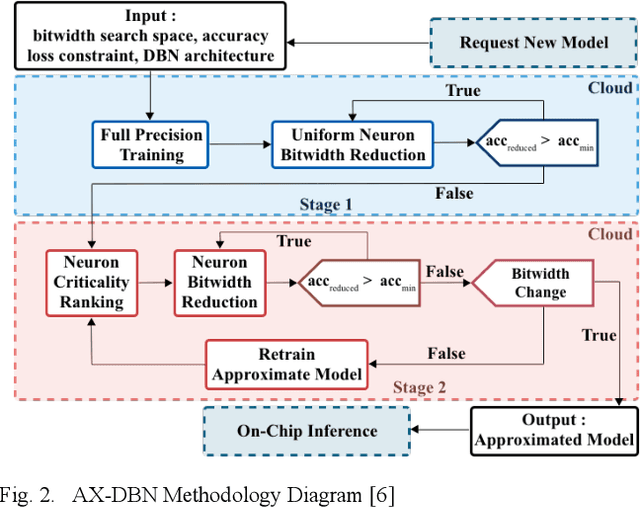
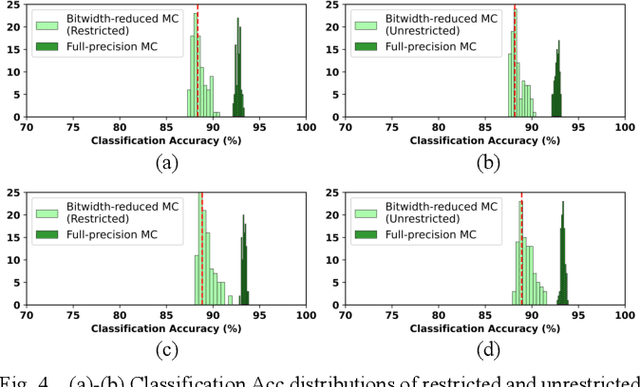
AX-DBN: An Approximate Computing Framework for the Design of Low-Power Discriminative Deep Belief Networks
Mar 26, 2019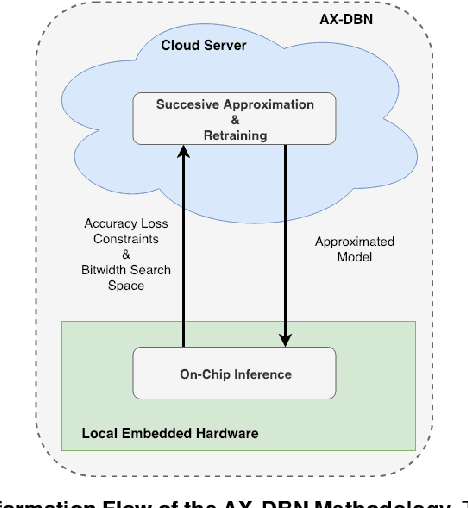
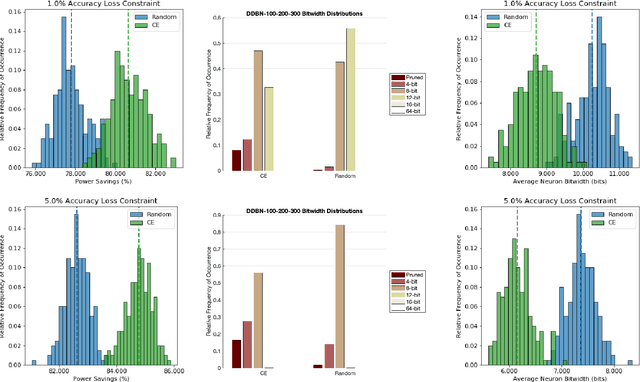
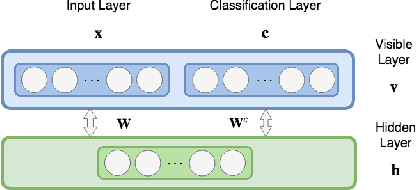
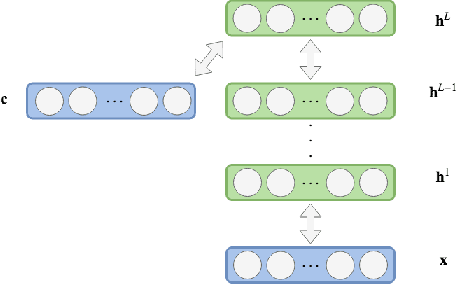
The power budget for embedded hardware implementations of Deep Learning algorithms can be extremely tight. To address implementation challenges in such domains, new design paradigms, like Approximate Computing, have drawn significant attention. Approximate Computing exploits the innate error-resilience of Deep Learning algorithms, a property that makes them amenable for deployment on low-power computing platforms. This paper describes an Approximate Computing design methodology, AX-DBN, for an architecture belonging to the class of stochastic Deep Learning algorithms known as Deep Belief Networks (DBNs). Specifically, we consider procedures for efficiently implementing the Discriminative Deep Belief Network (DDBN), a stochastic neural network which is used for classification tasks, extending Approximation Computing from the analysis of deterministic to stochastic neural networks. For the purpose of optimizing the DDBN for hardware implementations, we explore the use of: (a)Limited precision of neurons and functional approximations of activation functions; (b) Criticality analysis to identify nodes in the network which can operate at reduced precision while allowing the network to maintain target accuracy levels; and (c) A greedy search methodology with incremental retraining to determine the optimal reduction in precision for all neurons to maximize power savings. Using the AX-DBN methodology proposed in this paper, we present experimental results across several network architectures that show significant power savings under a user-specified accuracy loss constraint with respect to ideal full precision implementations.
A Design Methodology for Efficient Implementation of Deconvolutional Neural Networks on an FPGA
May 07, 2017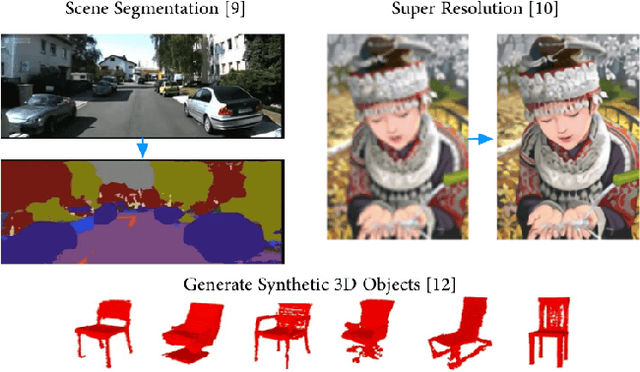
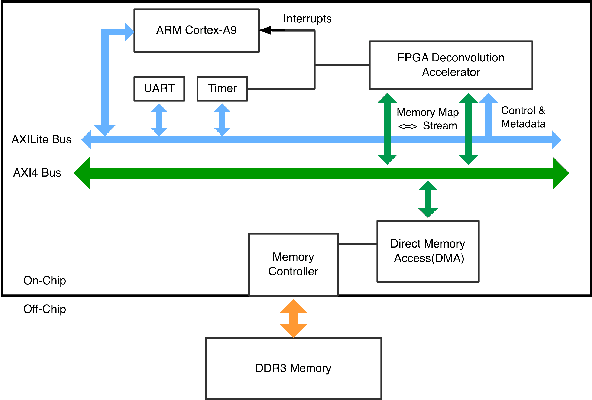

In recent years deep learning algorithms have shown extremely high performance on machine learning tasks such as image classification and speech recognition. In support of such applications, various FPGA accelerator architectures have been proposed for convolutional neural networks (CNNs) that enable high performance for classification tasks at lower power than CPU and GPU processors. However, to date, there has been little research on the use of FPGA implementations of deconvolutional neural networks (DCNNs). DCNNs, also known as generative CNNs, encode high-dimensional probability distributions and have been widely used for computer vision applications such as scene completion, scene segmentation, image creation, image denoising, and super-resolution imaging. We propose an FPGA architecture for deconvolutional networks built around an accelerator which effectively handles the complex memory access patterns needed to perform strided deconvolutions, and that supports convolution as well. We also develop a three-step design optimization method that systematically exploits statistical analysis, design space exploration and VLSI optimization. To verify our FPGA deconvolutional accelerator design methodology we train DCNNs offline on two representative datasets using the generative adversarial network method (GAN) run on Tensorflow, and then map these DCNNs to an FPGA DCNN-plus-accelerator implementation to perform generative inference on a Xilinx Zynq-7000 FPGA. Our DCNN implementation achieves a peak performance density of 0.012 GOPs/DSP.
ApproxDBN: Approximate Computing for Discriminative Deep Belief Networks
May 06, 2017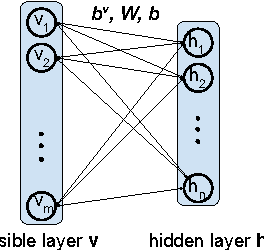
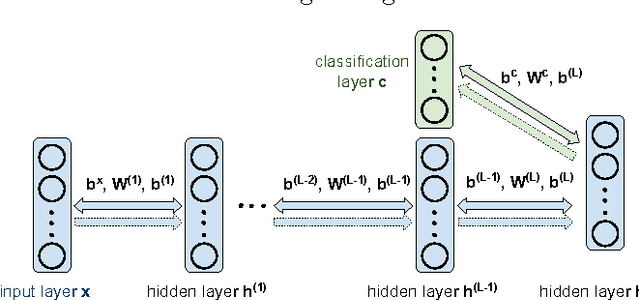
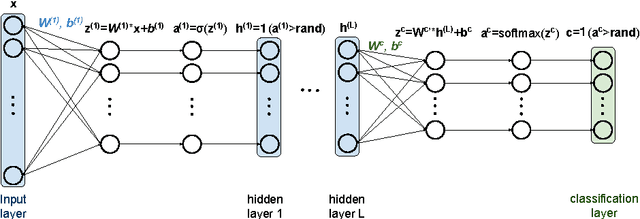
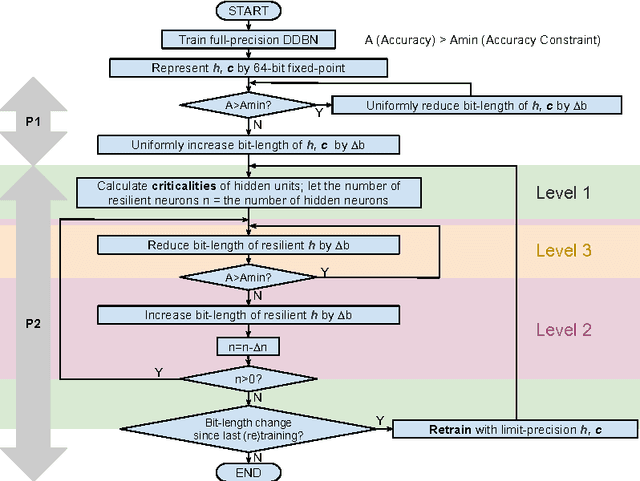
Probabilistic generative neural networks are useful for many applications, such as image classification, speech recognition and occlusion removal. However, the power budget for hardware implementations of neural networks can be extremely tight. To address this challenge we describe a design methodology for using approximate computing methods to implement Approximate Deep Belief Networks (ApproxDBNs) by systematically exploring the use of (1) limited precision of variables; (2) criticality analysis to identify the nodes in the network which can operate with such limited precision while allowing the network to maintain target accuracy levels; and (3) a greedy search methodology with incremental retraining to determine the optimal reduction in precision to enable maximize power savings under user-specified accuracy constraints. Experimental results show that significant bit-length reduction can be achieved by our ApproxDBN with constrained accuracy loss.