 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Lexical Feature Analysis of Spoken Language for Predicting Major Depression Symptom Severity
Nov 10, 2025Background: Captured between clinical appointments using mobile devices, spoken language has potential for objective, more regular assessment of symptom severity and earlier detection of relapse in major depressive disorder. However, research to date has largely been in non-clinical cross-sectional samples of written language using complex machine learning (ML) approaches with limited interpretability. Methods: We describe an initial exploratory analysis of longitudinal speech data and PHQ-8 assessments from 5,836 recordings of 586 participants in the UK, Netherlands, and Spain, collected in the RADAR-MDD study. We sought to identify interpretable lexical features associated with MDD symptom severity with linear mixed-effects modelling. Interpretable features and high-dimensional vector embeddings were also used to test the prediction performance of four regressor ML models. Results: In English data, MDD symptom severity was associated with 7 features including lexical diversity measures and absolutist language. In Dutch, associations were observed with words per sentence and positive word frequency; no associations were observed in recordings collected in Spain. The predictive power of lexical features and vector embeddings was near chance level across all languages. Limitations: Smaller samples in non-English speech and methodological choices, such as the elicitation prompt, may have also limited the effect sizes observable. A lack of NLP tools in languages other than English restricted our feature choice. Conclusion: To understand the value of lexical markers in clinical research and practice, further research is needed in larger samples across several languages using improved protocols, and ML models that account for within- and between-individual variations in language.
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Sep 05, 2023



Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.
Fitbeat: COVID-19 Estimation based on Wristband Heart Rate
Apr 19, 2021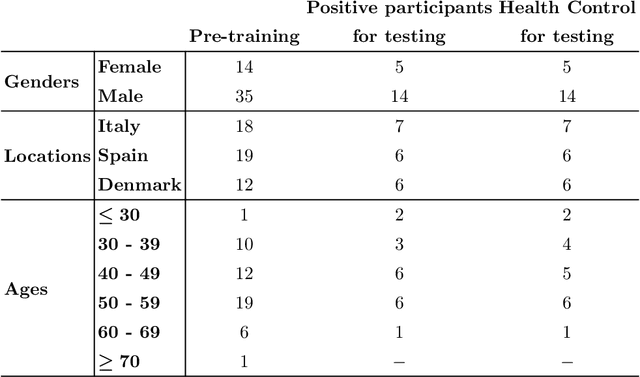

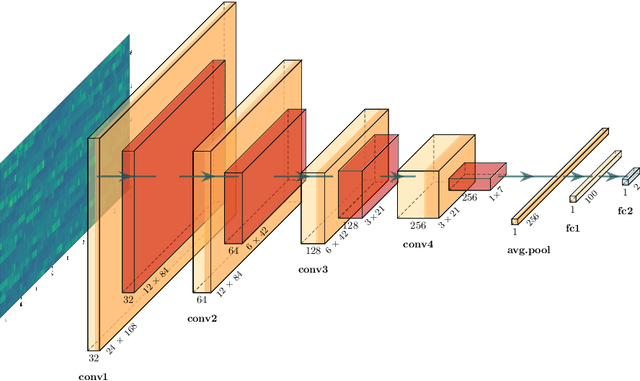
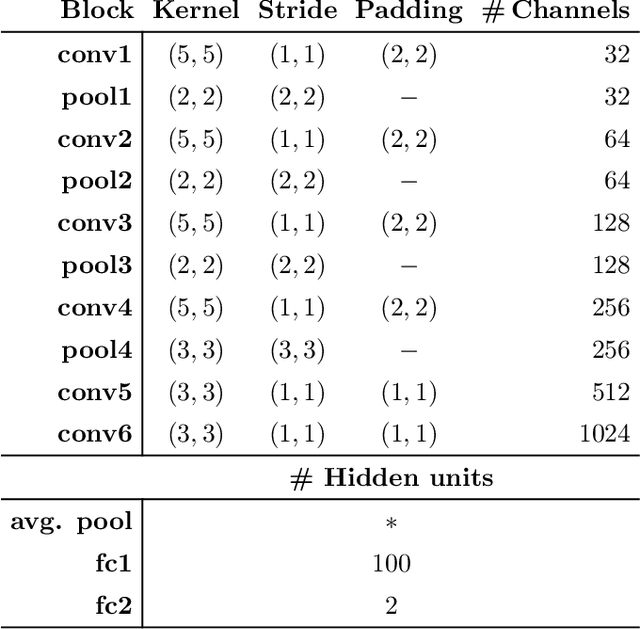
This study investigates the potential of deep learning methods to identify individuals with suspected COVID-19 infection using remotely collected heart-rate data. The study utilises data from the ongoing EU IMI RADAR-CNS research project that is investigating the feasibility of wearable devices and smart phones to monitor individuals with multiple sclerosis (MS), depression or epilepsy. Aspart of the project protocol, heart-rate data was collected from participants using a Fitbit wristband. The presence of COVID-19 in the cohort in this work was either confirmed through a positive swab test, or inferred through the self-reporting of a combination of symptoms including fever, respiratory symptoms, loss of smell or taste, tiredness and gastrointestinal symptoms. Experimental results indicate that our proposed contrastive convolutional auto-encoder (contrastive CAE), i. e., a combined architecture of an auto-encoder and contrastive loss, outperforms a conventional convolutional neural network (CNN), as well as a convolutional auto-encoder (CAE) without using contrastive loss. Our final contrastive CAE achieves 95.3% unweighted average recall, 86.4% precision, anF1 measure of 88.2%, a sensitivity of 100% and a specificity of 90.6% on a testset of 19 participants with MS who reported symptoms of COVID-19. Each of these participants was paired with a participant with MS with no COVID-19 symptoms.