 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1SPU: 1-step Speech Processing Unit
Nov 10, 2023Recent studies have made some progress in refining end-to-end (E2E) speech recognition encoders by applying Connectionist Temporal Classification (CTC) loss to enhance named entity recognition within transcriptions. However, these methods have been constrained by their exclusive use of the ASCII character set, allowing only a limited array of semantic labels. We propose 1SPU, a 1-step Speech Processing Unit which can recognize speech events (e.g: speaker change) or an NL event (Intent, Emotion) while also transcribing vocal content. It extends the E2E automatic speech recognition (ASR) system's vocabulary by adding a set of unused placeholder symbols, conceptually akin to the <pad> tokens used in sequence modeling. These placeholders are then assigned to represent semantic events (in form of tags) and are integrated into the transcription process as distinct tokens. We demonstrate notable improvements on the SLUE benchmark and yields results that are on par with those for the SLURP dataset. Additionally, we provide a visual analysis of the system's proficiency in accurately pinpointing meaningful tokens over time, illustrating the enhancement in transcription quality through the utilization of supplementary semantic tags.
Trustera: A Live Conversation Redaction System
Mar 16, 2023


Trustera, the first functional system that redacts personally identifiable information (PII) in real-time spoken conversations to remove agents' need to hear sensitive information while preserving the naturalness of live customer-agent conversations. As opposed to post-call redaction, audio masking starts as soon as the customer begins speaking to a PII entity. This significantly reduces the risk of PII being intercepted or stored in insecure data storage. Trustera's architecture consists of a pipeline of automatic speech recognition, natural language understanding, and a live audio redactor module. The system's goal is three-fold: redact entities that are PII, mask the audio that goes to the agent, and at the same time capture the entity, so that the captured PII can be used for a payment transaction or caller identification. Trustera is currently being used by thousands of agents to secure customers' sensitive information.
E2E Spoken Entity Extraction for Virtual Agents
Mar 01, 2023



This paper reimagines some aspects of speech processing using speech encoders, specifically about extracting entities directly from speech, with no intermediate textual representation. In human-computer conversations, extracting entities such as names, postal addresses and email addresses from speech is a challenging task. In this paper, we study the impact of fine-tuning pre-trained speech encoders on extracting spoken entities in human-readable form directly from speech without the need for text transcription. We illustrate that such a direct approach optimizes the encoder to transcribe only the entity relevant portions of speech, ignoring the superfluous portions such as carrier phrases and spellings of entities. In the context of dialogs from an enterprise virtual agent, we demonstrate that the 1-step approach outperforms the typical 2-step cascade of first generating lexical transcriptions followed by text-based entity extraction for identifying spoken entities.
Cross-stitched Multi-modal Encoders
Apr 20, 2022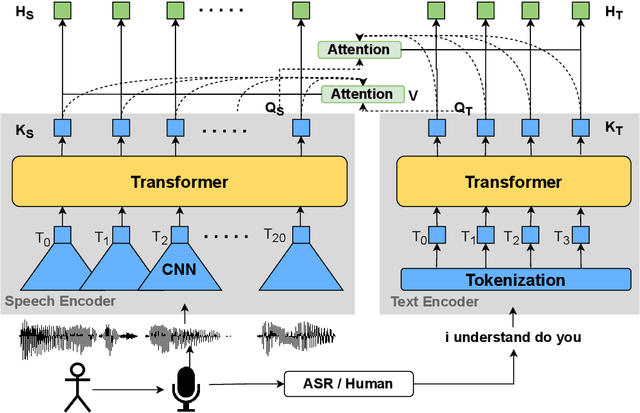
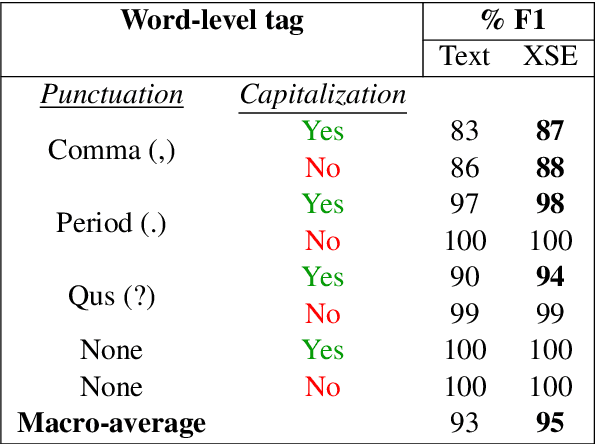
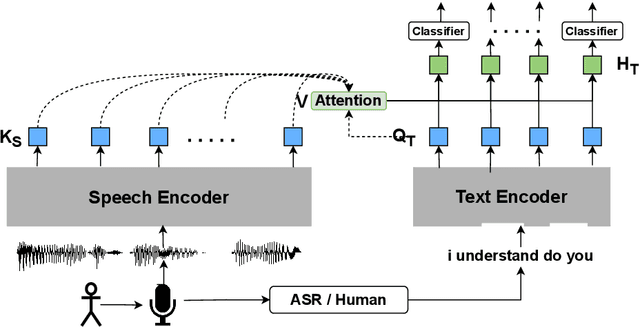
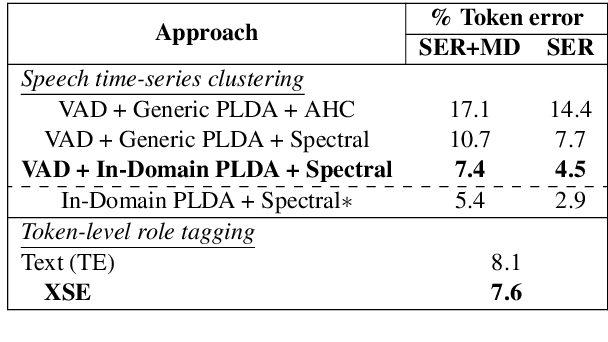
In this paper, we propose a novel architecture for multi-modal speech and text input. We combine pretrained speech and text encoders using multi-headed cross-modal attention and jointly fine-tune on the target problem. The resultant architecture can be used for continuous token-level classification or utterance-level prediction acting on simultaneous text and speech. The resultant encoder efficiently captures both acoustic-prosodic and lexical information. We compare the benefits of multi-headed attention-based fusion for multi-modal utterance-level classification against a simple concatenation of pre-pooled, modality-specific representations. Our model architecture is compact, resource efficient, and can be trained on a single consumer GPU card.
Seq-2-Seq based Refinement of ASR Output for Spoken Name Capture
Mar 29, 2022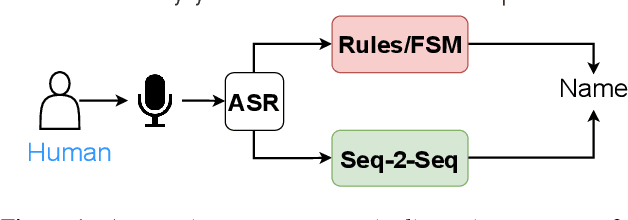
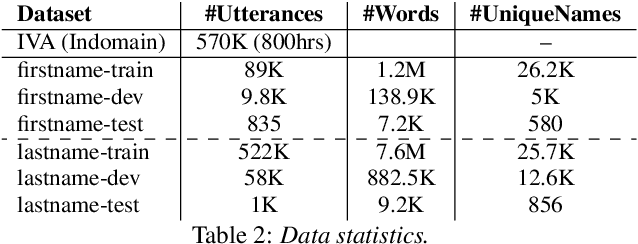
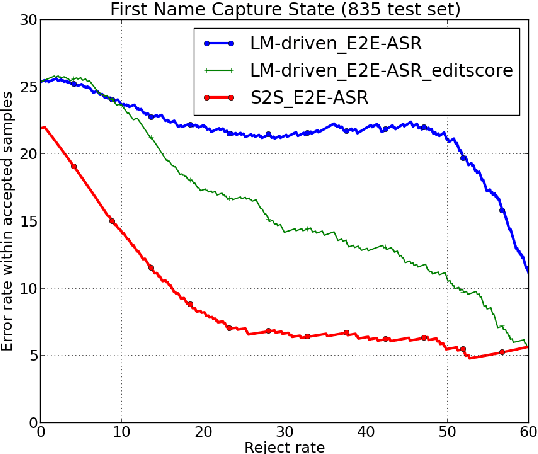
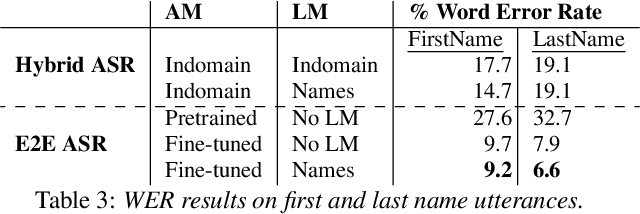
Person name capture from human speech is a difficult task in human-machine conversations. In this paper, we propose a novel approach to capture the person names from the caller utterances in response to the prompt "say and spell your first/last name". Inspired from work on spell correction, disfluency removal and text normalization, we propose a lightweight Seq-2-Seq system which generates a name spell from a varying user input. Our proposed method outperforms the strong baseline which is based on LM-driven rule-based approach.
Unsupervised Spoken Utterance Classification
Jul 02, 2021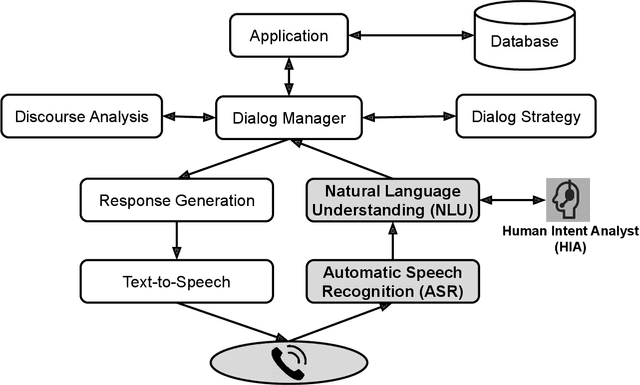
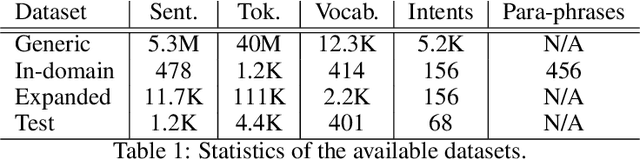
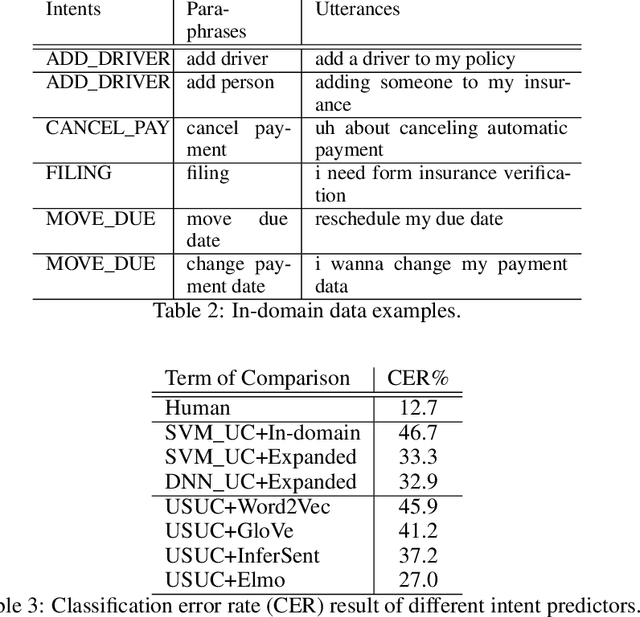

An intelligent virtual assistant (IVA) enables effortless conversations in call routing through spoken utterance classification (SUC) which is a special form of spoken language understanding (SLU). Building a SUC system requires a large amount of supervised in-domain data that is not always available. In this paper, we introduce an unsupervised spoken utterance classification approach (USUC) that does not require any in-domain data except for the intent labels and a few para-phrases per intent. USUC is consisting of a KNN classifier (K=1) and a complex embedding model trained on a large amount of unsupervised customer service corpus. Among all embedding models, we demonstrate that Elmo works best for USUC. However, an Elmo model is too slow to be used at run-time for call routing. To resolve this issue, first, we compute the uni- and bi-gram embedding vectors offline and we build a lookup table of n-grams and their corresponding embedding vector. Then we use this table to compute sentence embedding vectors at run-time, along with back-off techniques for unseen n-grams. Experiments show that USUC outperforms the traditional utterance classification methods by reducing the classification error rate from 32.9% to 27.0% without requiring supervised data. Moreover, our lookup and back-off technique increases the processing speed from 16 utterances per second to 118 utterances per second.
Intent Features for Rich Natural Language Understanding
Apr 21, 2021
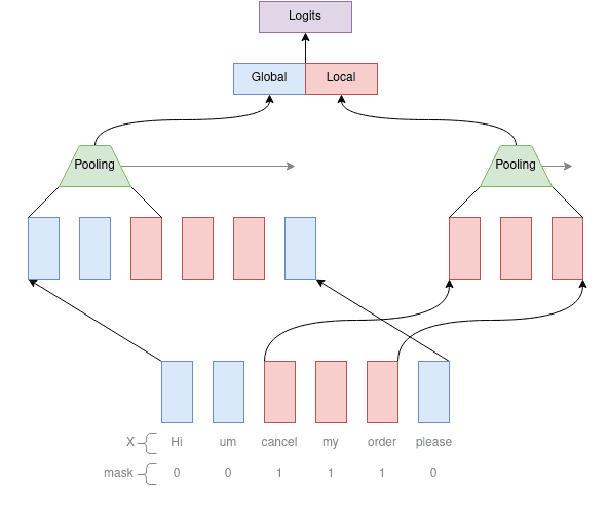

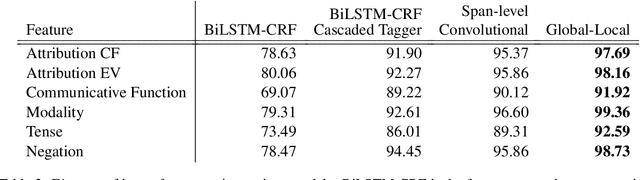
Complex natural language understanding modules in dialog systems have a richer understanding of user utterances, and thus are critical in providing a better user experience. However, these models are often created from scratch, for specific clients and use cases, and require the annotation of large datasets. This encourages the sharing of annotated data across multiple clients. To facilitate this we introduce the idea of intent features: domain and topic agnostic properties of intents that can be learned from the syntactic cues only, and hence can be shared. We introduce a new neural network architecture, the Global-Local model, that shows significant improvement over strong baselines for identifying these features in a deployed, multi-intent natural language understanding module, and, more generally, in a classification setting where a part of an utterance has to be classified utilizing the whole context.
Multiple Word Embeddings for Increased Diversity of Representation
Oct 09, 2020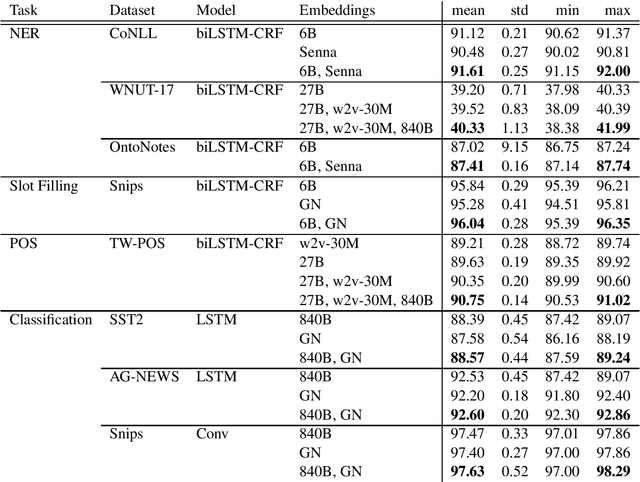

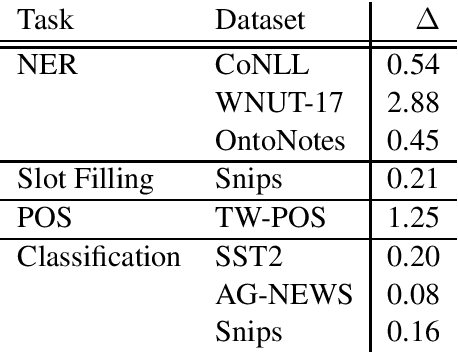
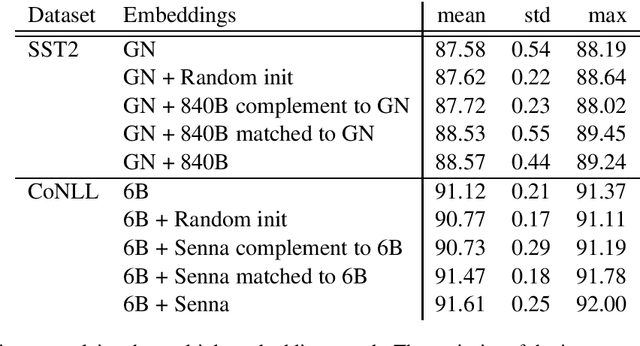
Most state-of-the-art models in natural language processing (NLP) are neural models built on top of large, pre-trained, contextual language models that generate representations of words in context and are fine-tuned for the task at hand. The improvements afforded by these "contextual embeddings" come with a high computational cost. In this work, we explore a simple technique that substantially and consistently improves performance over a strong baseline with negligible increase in run time. We concatenate multiple pre-trained embeddings to strengthen our representation of words. We show that this concatenation technique works across many tasks, datasets, and model types. We analyze aspects of pre-trained embedding similarity and vocabulary coverage and find that the representational diversity between different pre-trained embeddings is the driving force of why this technique works. We provide open source implementations of our models in both TensorFlow and PyTorch.
Constrained Decoding for Computationally Efficient Named Entity Recognition Taggers
Oct 09, 2020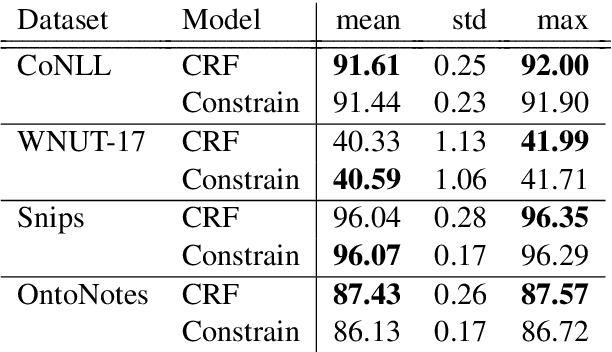
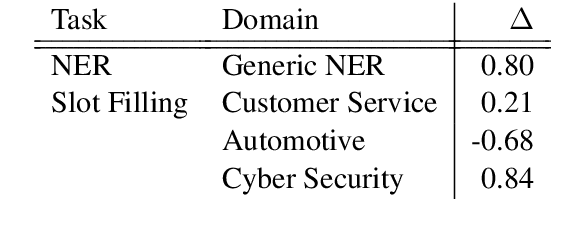

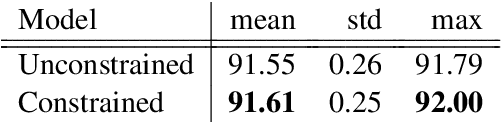
Current state-of-the-art models for named entity recognition (NER) are neural models with a conditional random field (CRF) as the final layer. Entities are represented as per-token labels with a special structure in order to decode them into spans. Current work eschews prior knowledge of how the span encoding scheme works and relies on the CRF learning which transitions are illegal and which are not to facilitate global coherence. We find that by constraining the output to suppress illegal transitions we can train a tagger with a cross-entropy loss twice as fast as a CRF with differences in F1 that are statistically insignificant, effectively eliminating the need for a CRF. We analyze the dynamics of tag co-occurrence to explain when these constraints are most effective and provide open source implementations of our tagger in both PyTorch and TensorFlow.
Automatic Data Expansion for Customer-care Spoken Language Understanding
Sep 27, 2018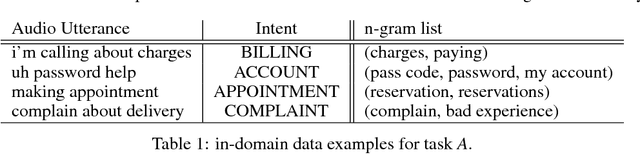
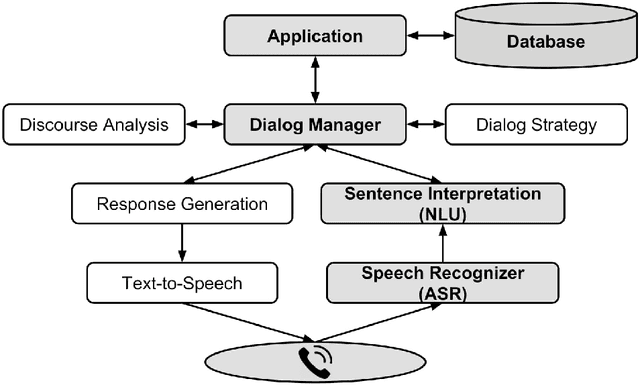
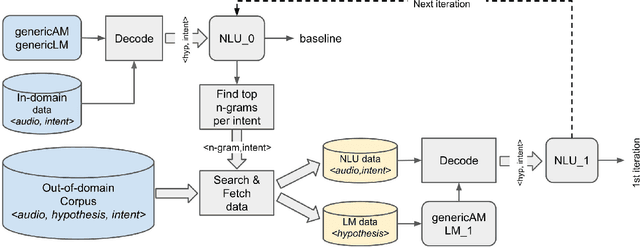
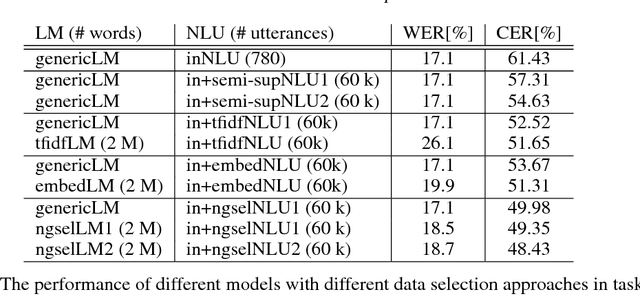
Spoken language understanding (SLU) systems are widely used in handling of customer-care calls.A traditional SLU system consists of an acoustic model (AM) and a language model (LM) that areused to decode the utterance and a natural language understanding (NLU) model that predicts theintent. While AM can be shared across different domains, LM and NLU models need to be trainedspecifically for every new task. However, preparing enough data to train these models is prohibitivelyexpensive. In this paper, we introduce an efficient method to expand the limited in-domain data. Theprocess starts with training a preliminary NLU model based on logistic regression on the in-domaindata. Since the features are based onn= 1,2-grams, we can detect the most informative n-gramsfor each intent class. Using these n-grams, we find the samples in the out-of-domain corpus that1) contain the desired n-gram and/or 2) have similar intent label. The ones which meet the firstconstraint are used to train a new LM model and the ones that meet both constraints are used to train anew NLU model. Our results on two divergent experimental setups show that the proposed approachreduces by 30% the absolute classification error rate (CER) comparing to the preliminary modelsand it significantly outperforms the traditional data expansion algorithms such as the ones based onsemi-supervised learning, TF-IDF and embedding vectors.