 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudoClick: Interactive Image Segmentation with Click Imitation
Jul 12, 2022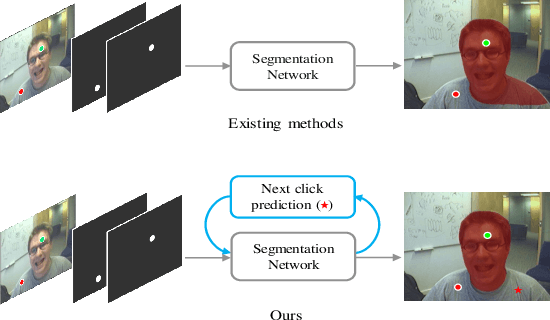
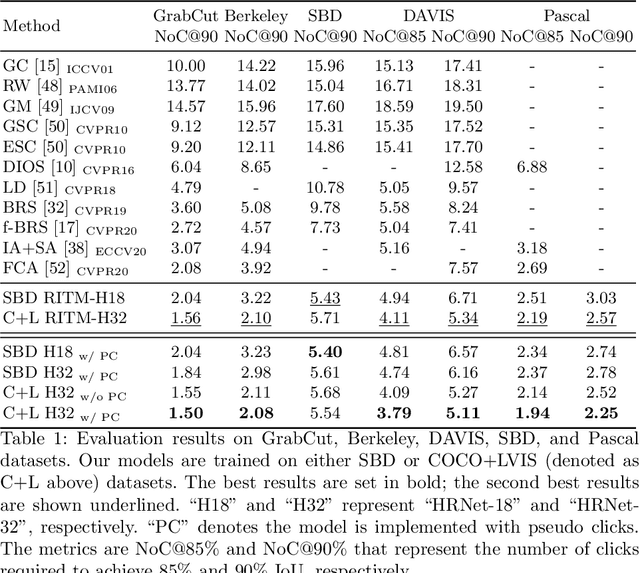
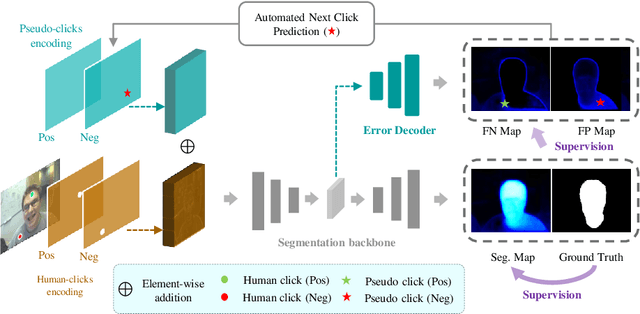

The goal of click-based interactive image segmentation is to obtain precise object segmentation masks with limited user interaction, i.e., by a minimal number of user clicks. Existing methods require users to provide all the clicks: by first inspecting the segmentation mask and then providing points on mislabeled regions, iteratively. We ask the question: can our model directly predict where to click, so as to further reduce the user interaction cost? To this end, we propose {\PseudoClick}, a generic framework that enables existing segmentation networks to propose candidate next clicks. These automatically generated clicks, termed pseudo clicks in this work, serve as an imitation of human clicks to refine the segmentation mask.
Learning Hierarchical Attention for Weakly-supervised Chest X-Ray Abnormality Localization and Diagnosis
Dec 23, 2021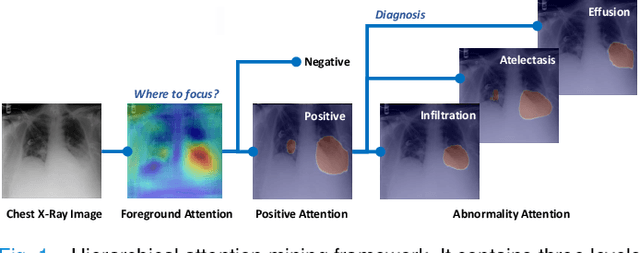
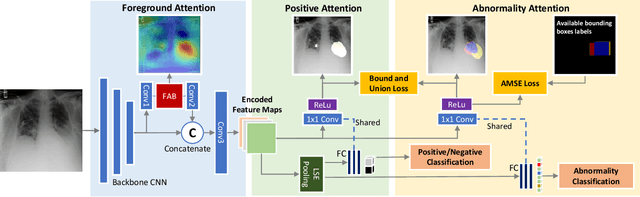
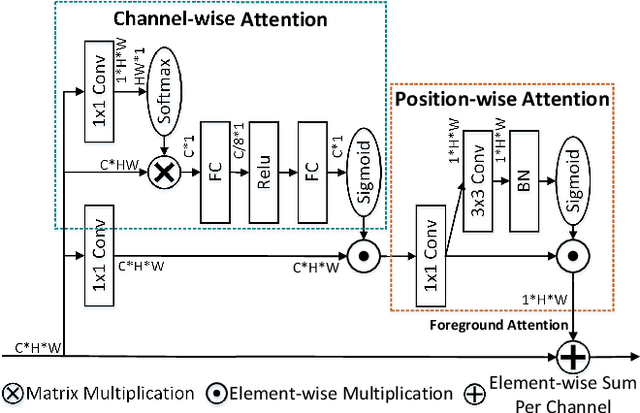
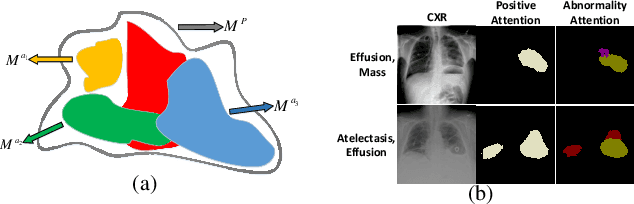
We consider the problem of abnormality localization for clinical applications. While deep learning has driven much recent progress in medical imaging, many clinical challenges are not fully addressed, limiting its broader usage. While recent methods report high diagnostic accuracies, physicians have concerns trusting these algorithm results for diagnostic decision-making purposes because of a general lack of algorithm decision reasoning and interpretability. One potential way to address this problem is to further train these models to localize abnormalities in addition to just classifying them. However, doing this accurately will require a large amount of disease localization annotations by clinical experts, a task that is prohibitively expensive to accomplish for most applications. In this work, we take a step towards addressing these issues by means of a new attention-driven weakly supervised algorithm comprising a hierarchical attention mining framework that unifies activation- and gradient-based visual attention in a holistic manner. Our key algorithmic innovations include the design of explicit ordinal attention constraints, enabling principled model training in a weakly-supervised fashion, while also facilitating the generation of visual-attention-driven model explanations by means of localization cues. On two large-scale chest X-ray datasets (NIH ChestX-ray14 and CheXpert), we demonstrate significant localization performance improvements over the current state of the art while also achieving competitive classification performance. Our code is available on https://github.com/oyxhust/HAM.
Spatio-Temporal Representation Factorization for Video-based Person Re-Identification
Aug 15, 2021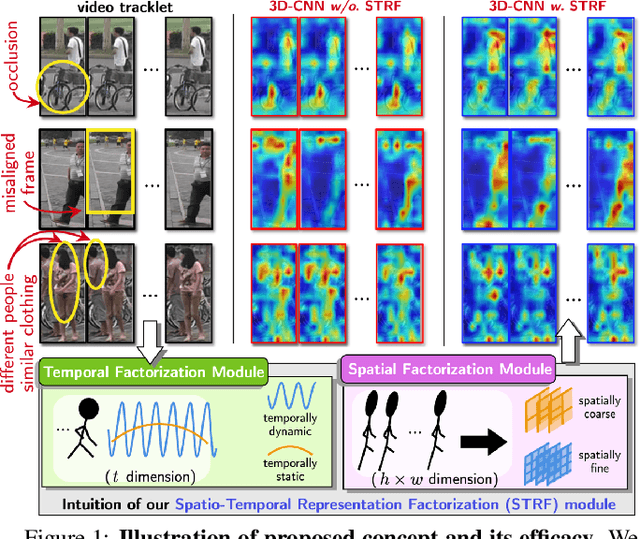
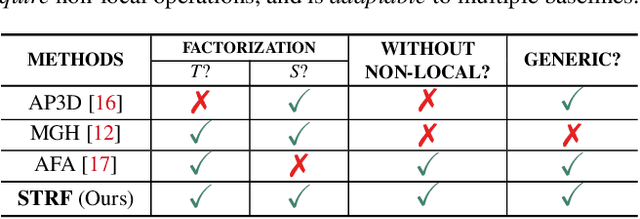

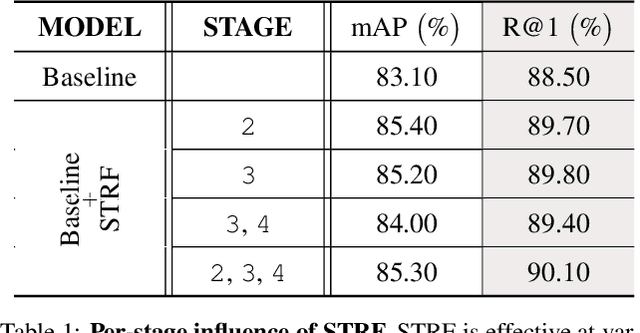
Despite much recent progress in video-based person re-identification (re-ID), the current state-of-the-art still suffers from common real-world challenges such as appearance similarity among various people, occlusions, and frame misalignment. To alleviate these problems, we propose Spatio-Temporal Representation Factorization (STRF), a flexible new computational unit that can be used in conjunction with most existing 3D convolutional neural network architectures for re-ID. The key innovations of STRF over prior work include explicit pathways for learning discriminative temporal and spatial features, with each component further factorized to capture complementary person-specific appearance and motion information. Specifically, temporal factorization comprises two branches, one each for static features (e.g., the color of clothes) that do not change much over time, and dynamic features (e.g., walking patterns) that change over time. Further, spatial factorization also comprises two branches to learn both global (coarse segments) as well as local (finer segments) appearance features, with the local features particularly useful in cases of occlusion or spatial misalignment. These two factorization operations taken together result in a modular architecture for our parameter-wise light STRF unit that can be plugged in between any two 3D convolutional layers, resulting in an end-to-end learning framework. We empirically show that STRF improves performance of various existing baseline architectures while demonstrating new state-of-the-art results using standard person re-ID evaluation protocols on three benchmarks.
Learning Local Recurrent Models for Human Mesh Recovery
Jul 27, 2021

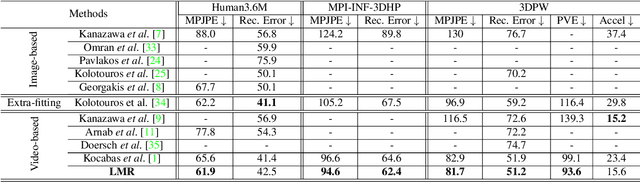
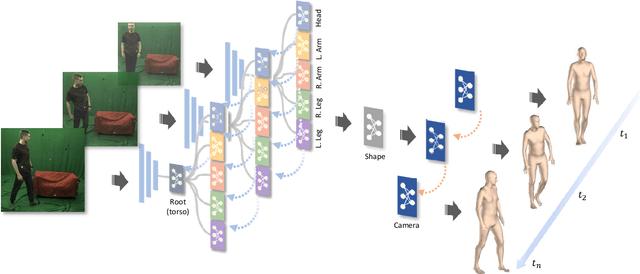
We consider the problem of estimating frame-level full human body meshes given a video of a person with natural motion dynamics. While much progress in this field has been in single image-based mesh estimation, there has been a recent uptick in efforts to infer mesh dynamics from video given its role in alleviating issues such as depth ambiguity and occlusions. However, a key limitation of existing work is the assumption that all the observed motion dynamics can be modeled using one dynamical/recurrent model. While this may work well in cases with relatively simplistic dynamics, inference with in-the-wild videos presents many challenges. In particular, it is typically the case that different body parts of a person undergo different dynamics in the video, e.g., legs may move in a way that may be dynamically different from hands (e.g., a person dancing). To address these issues, we present a new method for video mesh recovery that divides the human mesh into several local parts following the standard skeletal model. We then model the dynamics of each local part with separate recurrent models, with each model conditioned appropriately based on the known kinematic structure of the human body. This results in a structure-informed local recurrent learning architecture that can be trained in an end-to-end fashion with available annotations. We conduct a variety of experiments on standard video mesh recovery benchmark datasets such as Human3.6M, MPI-INF-3DHP, and 3DPW, demonstrating the efficacy of our design of modeling local dynamics as well as establishing state-of-the-art results based on standard evaluation metrics.
Everybody Is Unique: Towards Unbiased Human Mesh Recovery
Jul 13, 2021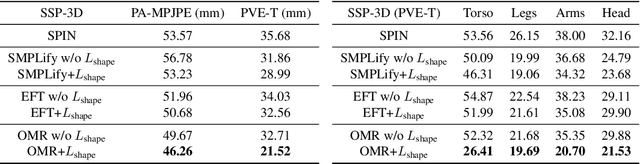
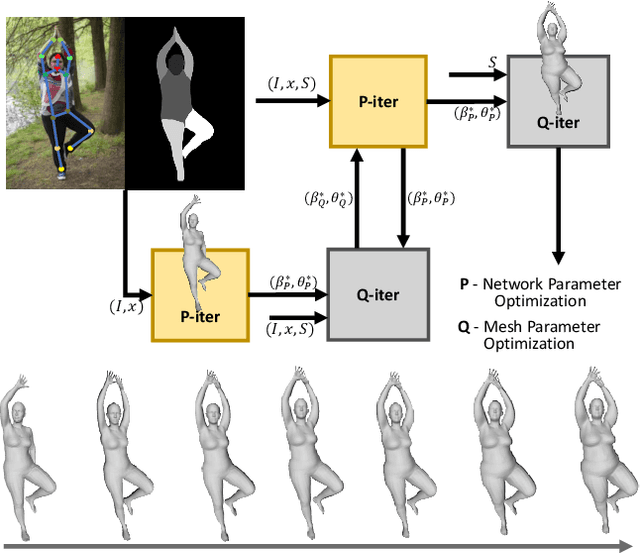
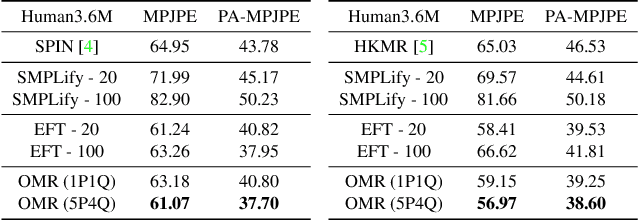
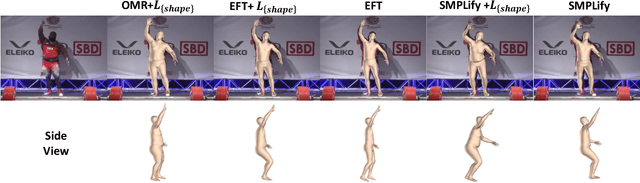
We consider the problem of obese human mesh recovery, i.e., fitting a parametric human mesh to images of obese people. Despite obese person mesh fitting being an important problem with numerous applications (e.g., healthcare), much recent progress in mesh recovery has been restricted to images of non-obese people. In this work, we identify this crucial gap in the current literature by presenting and discussing limitations of existing algorithms. Next, we present a simple baseline to address this problem that is scalable and can be easily used in conjunction with existing algorithms to improve their performance. Finally, we present a generalized human mesh optimization algorithm that substantially improves the performance of existing methods on both obese person images as well as community-standard benchmark datasets. A key innovation of this technique is that it does not rely on supervision from expensive-to-create mesh parameters. Instead, starting from widely and cheaply available 2D keypoints annotations, our method automatically generates mesh parameters that can in turn be used to re-train and fine-tune any existing mesh estimation algorithm. This way, we show our method acts as a drop-in to improve the performance of a wide variety of contemporary mesh estimation methods. We conduct extensive experiments on multiple datasets comprising both standard and obese person images and demonstrate the efficacy of our proposed techniques.
A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts
May 01, 2021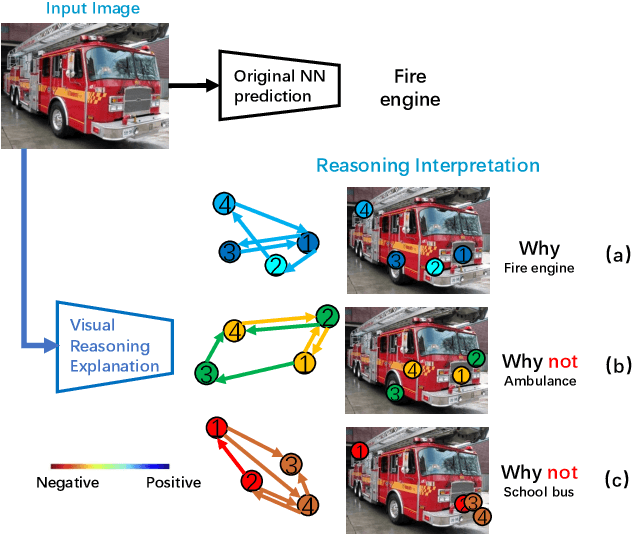
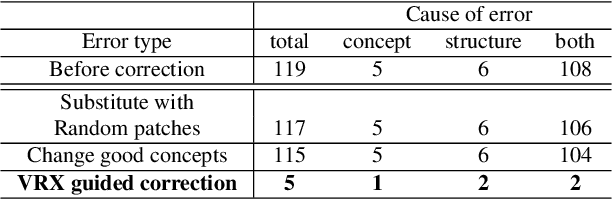
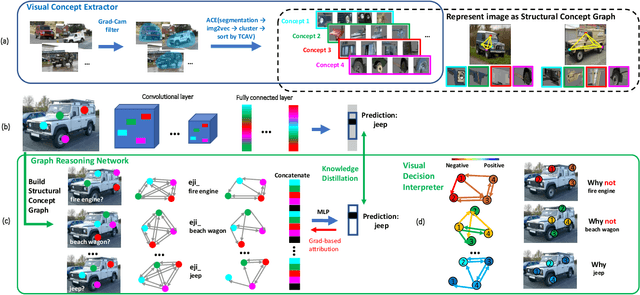

Despite substantial progress in applying neural networks (NN) to a wide variety of areas, they still largely suffer from a lack of transparency and interpretability. While recent developments in explainable artificial intelligence attempt to bridge this gap (e.g., by visualizing the correlation between input pixels and final outputs), these approaches are limited to explaining low-level relationships, and crucially, do not provide insights on error correction. In this work, we propose a framework (VRX) to interpret classification NNs with intuitive structural visual concepts. Given a trained classification model, the proposed VRX extracts relevant class-specific visual concepts and organizes them using structural concept graphs (SCG) based on pairwise concept relationships. By means of knowledge distillation, we show VRX can take a step towards mimicking the reasoning process of NNs and provide logical, concept-level explanations for final model decisions. With extensive experiments, we empirically show VRX can meaningfully answer "why" and "why not" questions about the prediction, providing easy-to-understand insights about the reasoning process. We also show that these insights can potentially provide guidance on improving NN's performance.
Towards Visually Explaining Similarity Models
Aug 13, 2020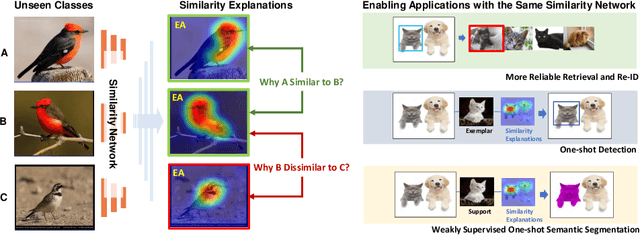
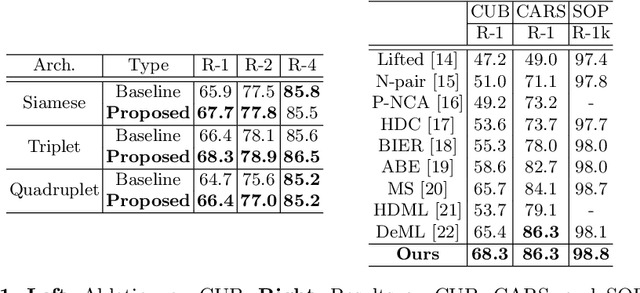


We consider the problem of visually explaining similarity models, i.e., explaining why a model predicts two images to be similar in addition to producing a scalar score. While much recent work in visual model interpretability has focused on gradient-based attention, these methods rely on a classification module to generate visual explanations. Consequently, they cannot readily explain other kinds of models that do not use or need classification-like loss functions (e.g., similarity models trained with a metric learning loss). In this work, we bridge this crucial gap, presenting the first method to generate gradient-based visual explanations for image similarity predictors. By relying solely on the learned feature embedding, we show that our approach can be applied to any kind of CNN-based similarity architecture, an important step towards generic visual explainability. We show that our resulting visual explanations serve more than just interpretability; they can be infused into the model learning process itself with new trainable constraints based on our similarity explanations. We show that the resulting similarity models perform, and can be visually explained, better than the corresponding baseline models trained without our explanation constraints. We demonstrate our approach using extensive experiments on three different kinds of tasks: generic image retrieval, person re-identification, and low-shot semantic segmentation.
Hierarchical Kinematic Human Mesh Recovery
Mar 09, 2020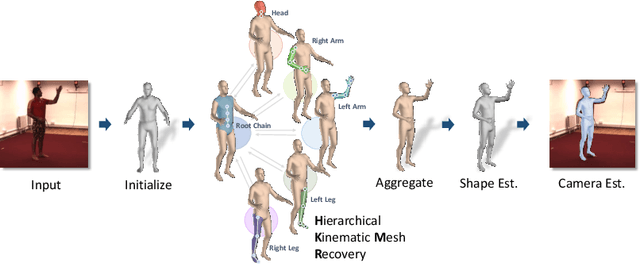
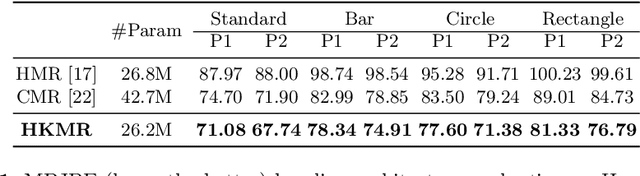
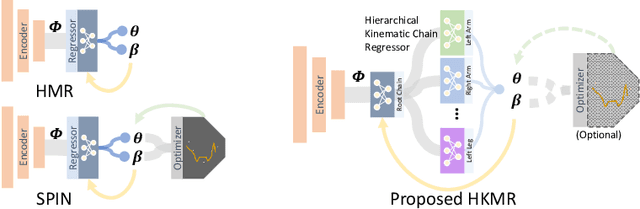

We consider the problem of estimating a parametric model of 3D human mesh from a single image. While there has been substantial recent progress in this area with direct regression of model parameters, these methods only implicitly exploit the human body kinematic structure, leading to sub-optimal use of the model prior. In this work, we address this gap by proposing a new technique for regression of human parametric model that is explicitly informed by the known hierarchical structure, including joint interdependencies of the model. This results in a strong prior-informed design of the regressor architecture and an associated hierarchical optimization that is flexible to be used in conjunction with the current standard frameworks for 3D human mesh recovery. We demonstrate these aspects by means of extensive experiments on standard benchmark datasets, showing how our proposed new design outperforms several existing and popular methods, establishing new state-of-the-art results. With our explicit consideration of joint interdependencies, our proposed method is equipped to infer joints even under data corruptions, which we demonstrate with experiments under varying degrees of occlusion.
Towards Visually Explaining Variational Autoencoders
Nov 18, 2019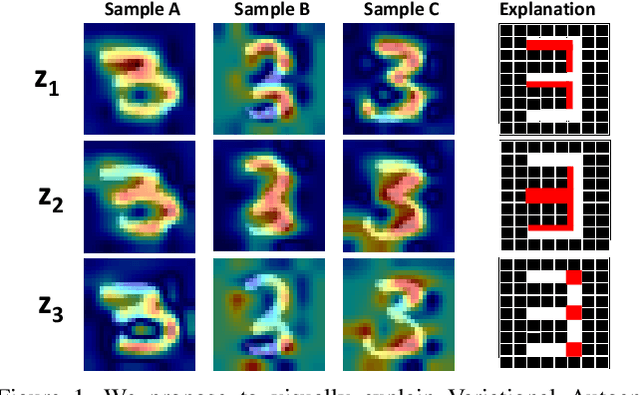
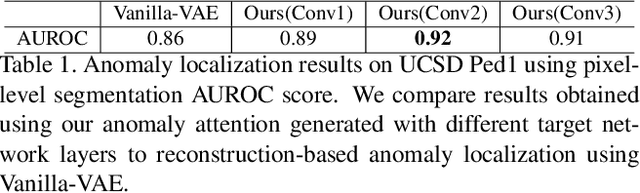
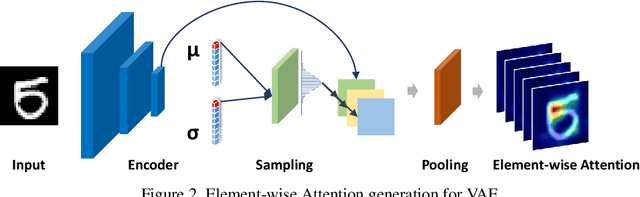
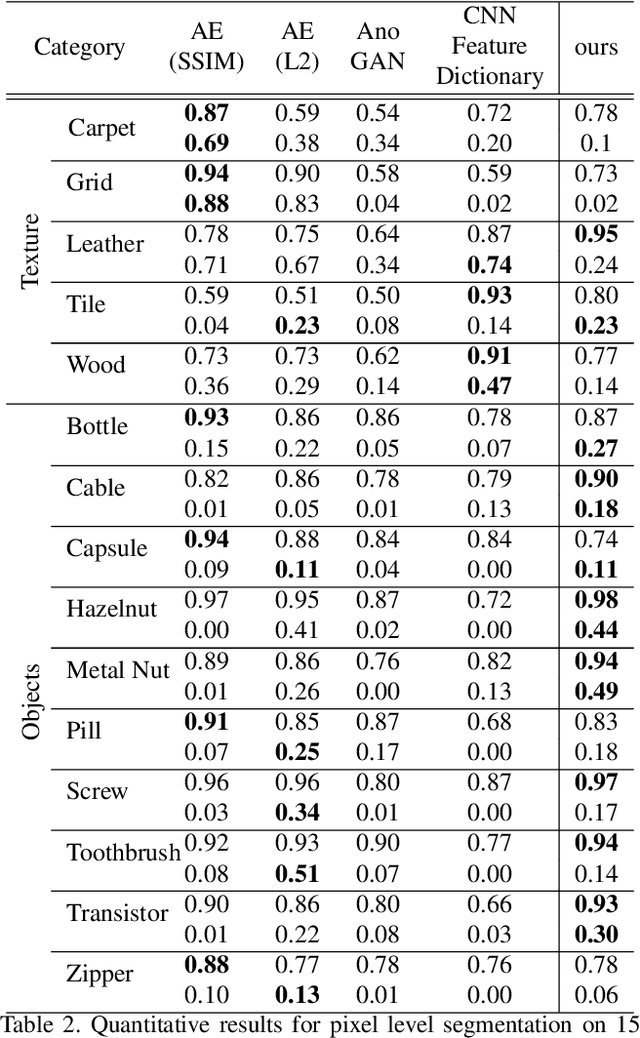
Recent advances in Convolutional Neural Network (CNN) model interpretability have led to impressive progress in visualizing and understanding model predictions. In particular, gradient-based visual attention methods have driven much recent effort in using visual attention maps as a means for visual explanations. A key problem, however, is these methods are designed for classification and categorization tasks, and their extension to explaining generative models, \eg, variational autoencoders (VAE) is not trivial. In this work, we take a step towards bridging this crucial gap, proposing the first technique to visually explain VAEs by means of gradient-based attention. We present methods to generate visual attention from the learned latent space, and also demonstrate such attention explanations serve more than just explaining VAE predictions. We show how these attention maps can be used to localize anomalies in images, demonstrating state-of-the-art performance on the MVTec-AD dataset. We also show how they can be infused into model training, helping bootstrap the VAE into learning improved latent space disentanglement, demonstrated on the Dsprites dataset.
Towards Robust RGB-D Human Mesh Recovery
Nov 18, 2019
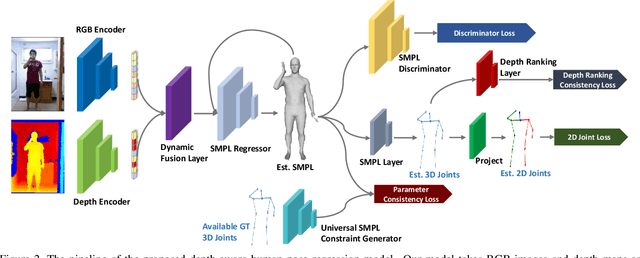
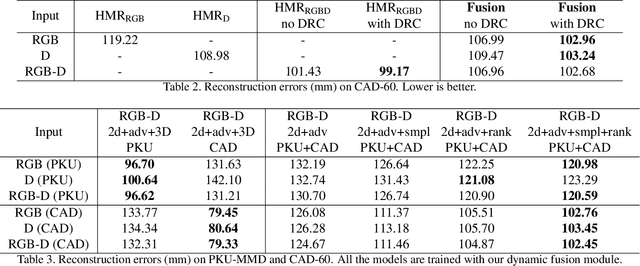
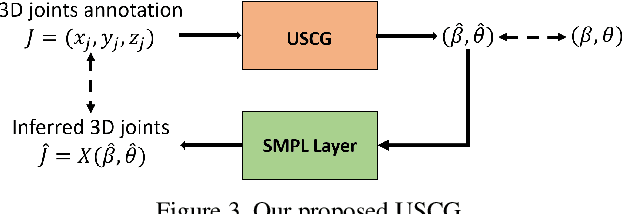
We consider the problem of human pose estimation. While much recent work has focused on the RGB domain, these techniques are inherently under-constrained since there can be many 3D configurations that explain the same 2D projection. To this end, we propose a new method that uses RGB-D data to estimate a parametric human mesh model. Our key innovations include (a) the design of a new dynamic data fusion module that facilitates learning with a combination of RGB-only and RGB-D datasets, (b) a new constraint generator module that provides SMPL supervisory signals when explicit SMPL annotations are not available, and (c) the design of a new depth ranking learning objective, all of which enable principled model training with RGB-D data. We conduct extensive experiments on a variety of RGB-D datasets to demonstrate efficacy.