 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhrase Pair Mappings for Hindi-English Statistical Machine Translation
Nov 10, 2017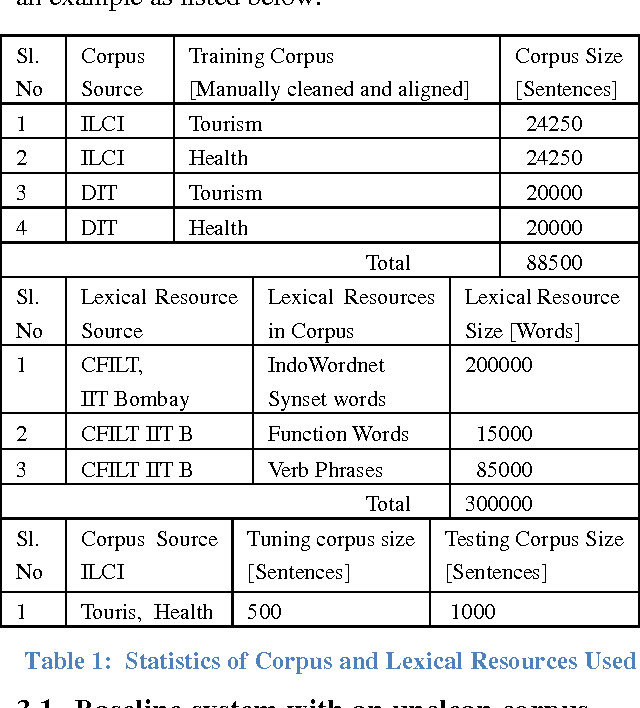
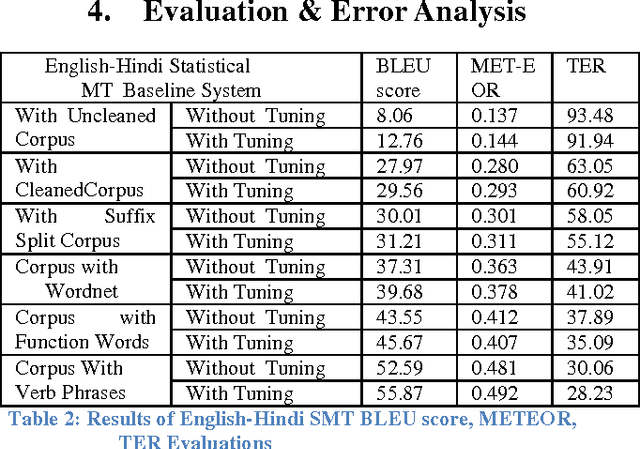
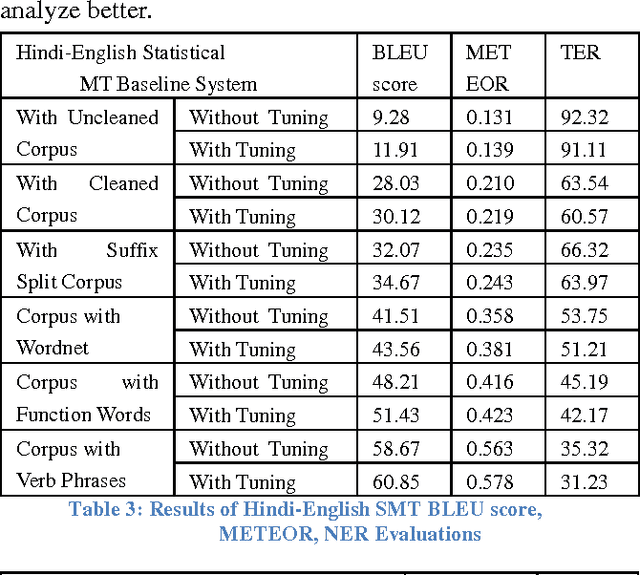
In this paper, we present our work on the creation of lexical resources for the Machine Translation between English and Hindi. We describes the development of phrase pair mappings for our experiments and the comparative performance evaluation between different trained models on top of the baseline Statistical Machine Translation system. We focused on augmenting the parallel corpus with more vocabulary as well as with various inflected forms by exploring different ways. We have augmented the training corpus with various lexical resources such as lexical words, synset words, function words and verb phrases. We have described the case studies, automatic and subjective evaluations, detailed error analysis for both the English to Hindi and Hindi to English machine translation systems. We further analyzed that, there is an incremental growth in the quality of machine translation with the usage of various lexical resources. Thus lexical resources do help uplift the translation quality of resource poor langugaes.
Bilingual Words and Phrase Mappings for Marathi and Hindi SMT
Nov 10, 2017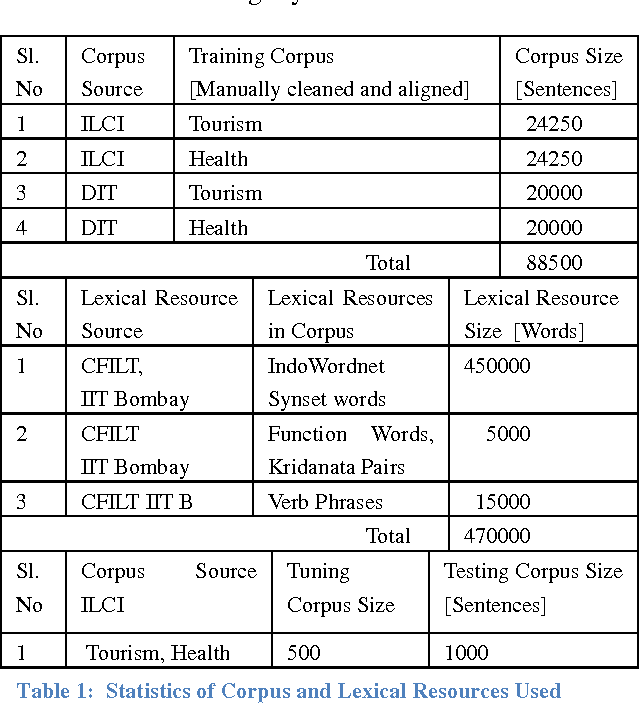
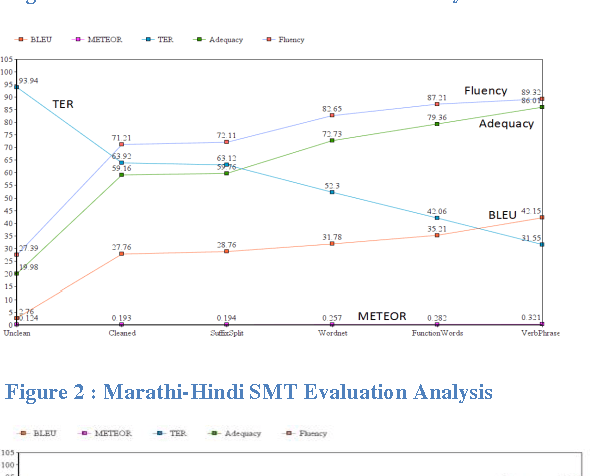
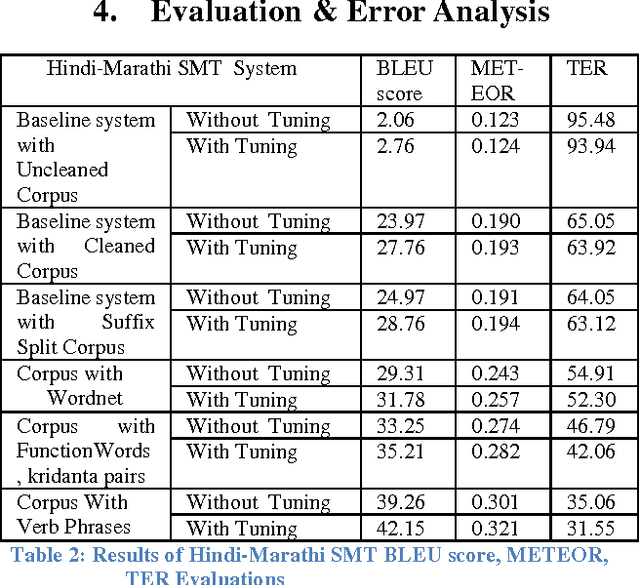
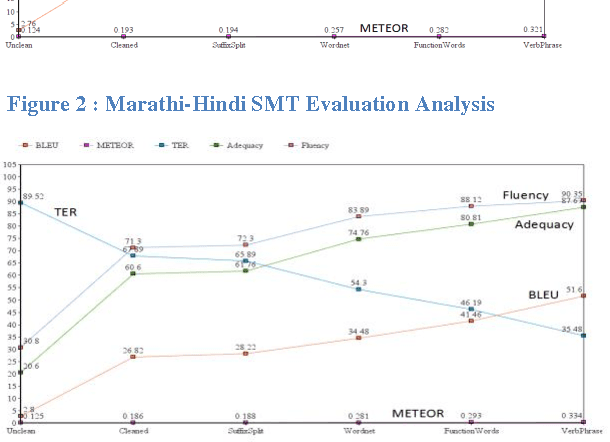
Lack of proper linguistic resources is the major challenges faced by the Machine Translation system developments when dealing with the resource poor languages. In this paper, we describe effective ways to utilize the lexical resources to improve the quality of statistical machine translation. Our research on the usage of lexical resources mainly focused on two ways, such as; augmenting the parallel corpus with more vocabulary and to provide various word forms. We have augmented the training corpus with various lexical resources such as lexical words, function words, kridanta pairs and verb phrases. We have described the case studies, evaluations and detailed error analysis for both Marathi to Hindi and Hindi to Marathi machine translation systems. From the evaluations we observed that, there is an incremental growth in the quality of machine translation as the usage of various lexical resources increases. Moreover, usage of various lexical resources helps to improve the coverage and quality of machine translation where limited parallel corpus is available.
Morphology Generation for Statistical Machine Translation
Nov 10, 2017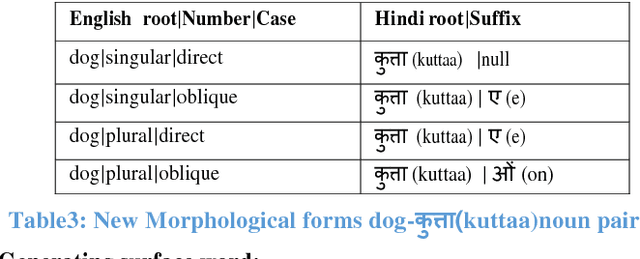
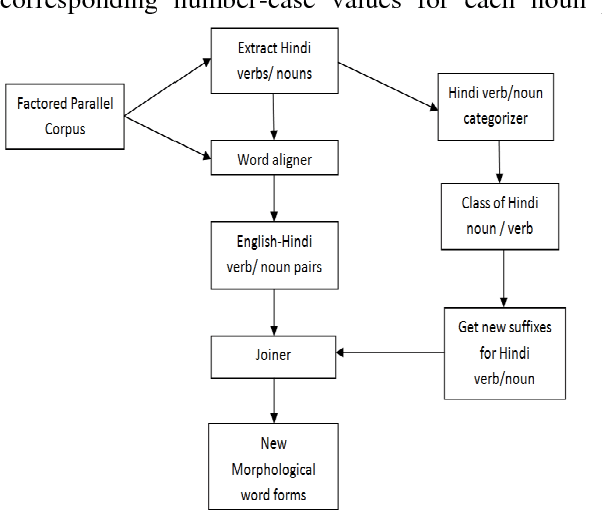
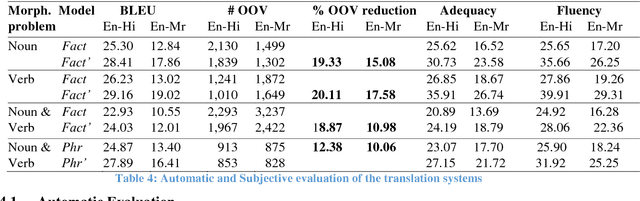
When translating into morphologically rich languages, Statistical MT approaches face the problem of data sparsity. The severity of the sparseness problem will be high when the corpus size of morphologically richer language is less. Even though we can use factored models to correctly generate morphological forms of words, the problem of data sparseness limits their performance. In this paper, we describe a simple and effective solution which is based on enriching the input corpora with various morphological forms of words. We use this method with the phrase-based and factor-based experiments on two morphologically rich languages: Hindi and Marathi when translating from English. We evaluate the performance of our experiments both in terms automatic evaluation and subjective evaluation such as adequacy and fluency. We observe that the morphology injection method helps in improving the quality of translation. We further analyze that the morph injection method helps in handling the data sparseness problem to a great level.
Indowordnets help in Indian Language Machine Translation
Oct 06, 2017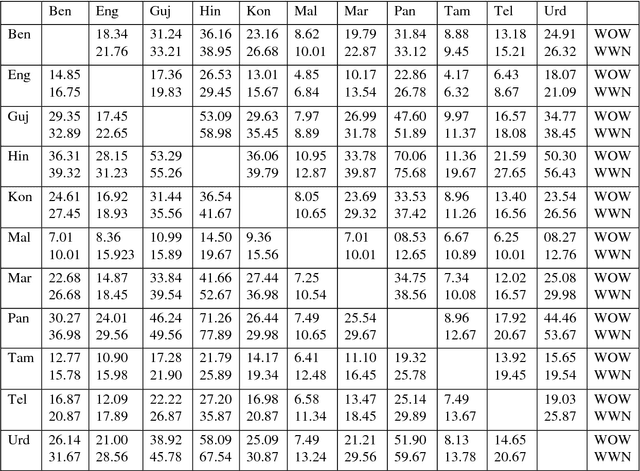
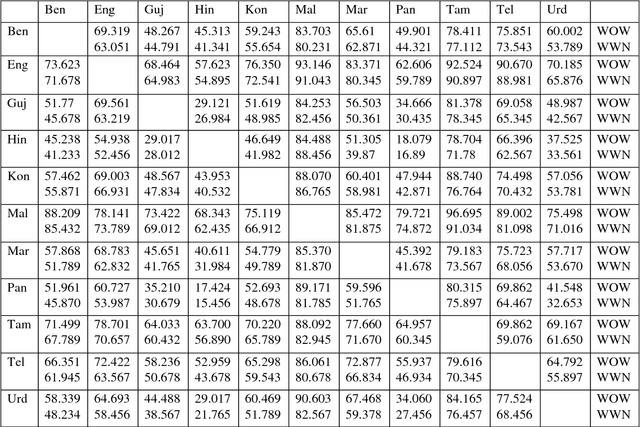
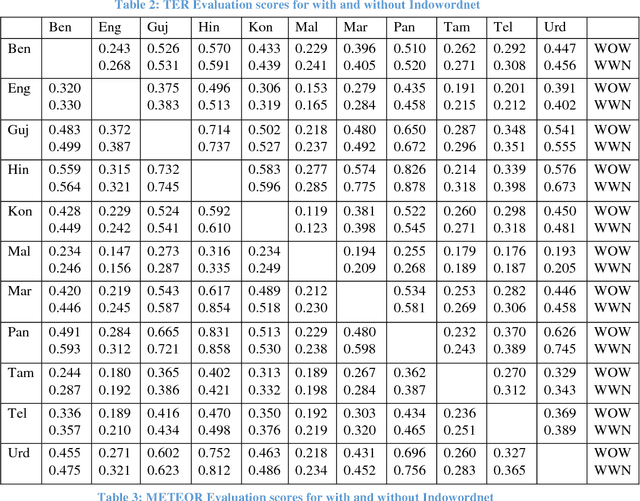
Being less resource languages, Indian-Indian and English-Indian language MT system developments faces the difficulty to translate various lexical phenomena. In this paper, we present our work on a comparative study of 440 phrase-based statistical trained models for 110 language pairs across 11 Indian languages. We have developed 110 baseline Statistical Machine Translation systems. Then we have augmented the training corpus with Indowordnet synset word entries of lexical database and further trained 110 models on top of the baseline system. We have done a detailed performance comparison using various evaluation metrics such as BLEU score, METEOR and TER. We observed significant improvement in evaluations of translation quality across all the 440 models after using the Indowordnet. These experiments give a detailed insight in two ways : (1) usage of lexical database with synset mapping for resource poor languages (2) efficient usage of Indowordnet sysnset mapping. More over, synset mapped lexical entries helped the SMT system to handle the ambiguity to a great extent during the translation.
Role of Morphology Injection in Statistical Machine Translation
Sep 16, 2017
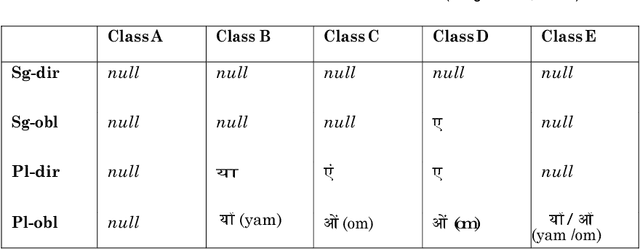
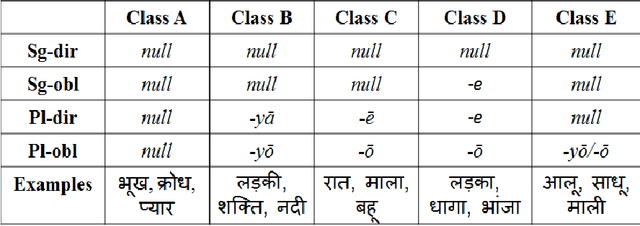
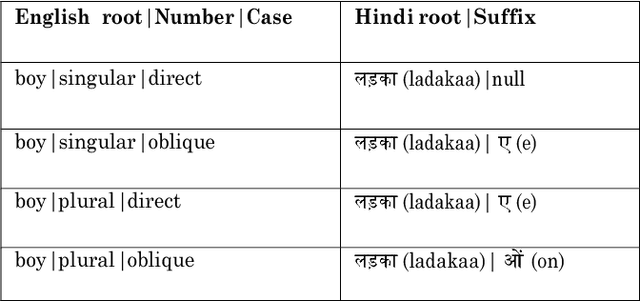
Phrase-based Statistical models are more commonly used as they perform optimally in terms of both, translation quality and complexity of the system. Hindi and in general all Indian languages are morphologically richer than English. Hence, even though Phrase-based systems perform very well for the less divergent language pairs, for English to Indian language translation, we need more linguistic information (such as morphology, parse tree, parts of speech tags, etc.) on the source side. Factored models seem to be useful in this case, as Factored models consider word as a vector of factors. These factors can contain any information about the surface word and use it while translating. Hence, the objective of this work is to handle morphological inflections in Hindi and Marathi using Factored translation models while translating from English. SMT approaches face the problem of data sparsity while translating into a morphologically rich language. It is very unlikely for a parallel corpus to contain all morphological forms of words. We propose a solution to generate these unseen morphological forms and inject them into original training corpora. In this paper, we study factored models and the problem of sparseness in context of translation to morphologically rich languages. We propose a simple and effective solution which is based on enriching the input with various morphological forms of words. We observe that morphology injection improves the quality of translation in terms of both adequacy and fluency. We verify this with the experiments on two morphologically rich languages: Hindi and Marathi, while translating from English.
* 36 pages, 12 figures, 15 tables, Modified version Published in: ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP) TALLIP Homepage archive Volume 17 Issue 1, September 2017 Issue-in-Progress,Article No. 1
Statistical Vs Rule Based Machine Translation; A Case Study on Indian Language Perspective
Aug 12, 2017
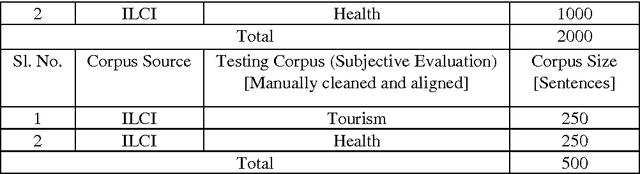

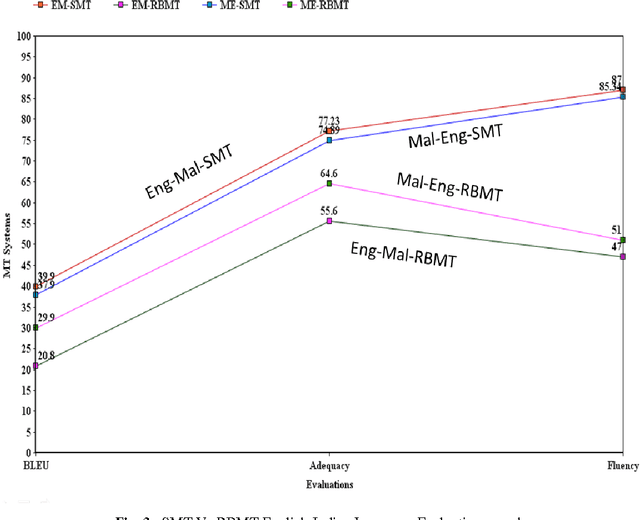
In this paper we present our work on a case study between Statistical Machien Transaltion (SMT) and Rule-Based Machine Translation (RBMT) systems on English-Indian langugae and Indian to Indian langugae perspective. Main objective of our study is to make a five way performance compariosn; such as, a) SMT and RBMT b) SMT on English-Indian langugae c) RBMT on English-Indian langugae d) SMT on Indian to Indian langugae perspective e) RBMT on Indian to Indian langugae perspective. Through a detailed analysis we describe the Rule Based and the Statistical Machine Translation system developments and its evaluations. Through a detailed error analysis, we point out the relative strengths and weaknesses of both systems. The observations based on our study are: a) SMT systems outperforms RBMT b) In the case of SMT, English to Indian language MT systmes performs better than Indian to English langugae MT systems c) In the case of RBMT, English to Indian langugae MT systems perofrms better than Indian to Englsih Language MT systems d) SMT systems performs better for Indian to Indian language MT systems compared to RBMT. Effectively, we shall see that even with a small amount of training corpus a statistical machine translation system has many advantages for high quality domain specific machine translation over that of a rule-based counterpart.
Lexical Resources for Hindi Marathi MT
Mar 04, 2017
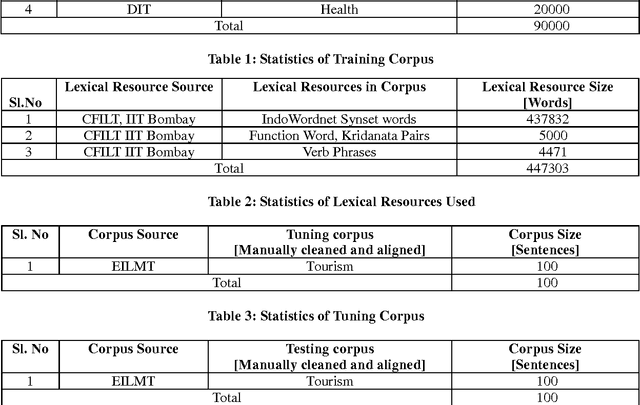
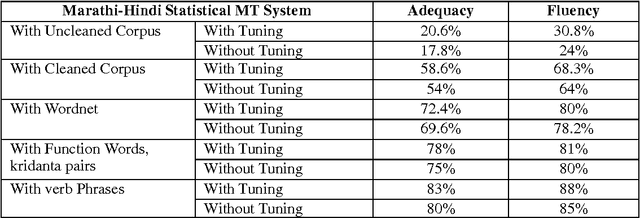
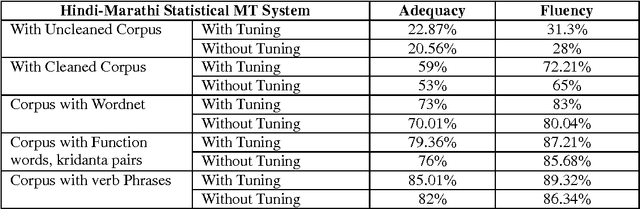
In this paper we describe some ways to utilize various lexical resources to improve the quality of statistical machine translation system. We have augmented the training corpus with various lexical resources such as IndoWordnet semantic relation set, function words, kridanta pairs and verb phrases etc. Our research on the usage of lexical resources mainly focused on two ways such as augmenting parallel corpus with more vocabulary and augmenting with various word forms. We have described case studies, evaluations and detailed error analysis for both Marathi to Hindi and Hindi to Marathi machine translation systems. From the evaluations we observed that, there is an incremental growth in the quality of machine translation as the usage of various lexical resources increases. Moreover usage of various lexical resources helps to improve the coverage and quality of machine translation where limited parallel corpus is available.
A case study on English-Malayalam Machine Translation
Feb 27, 2017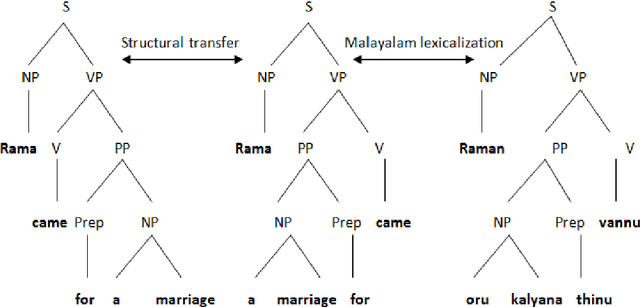

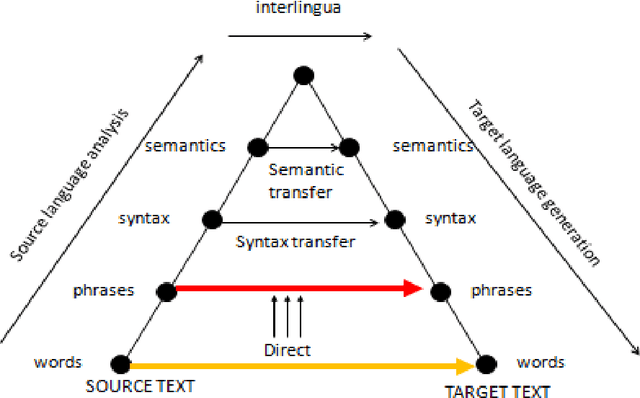
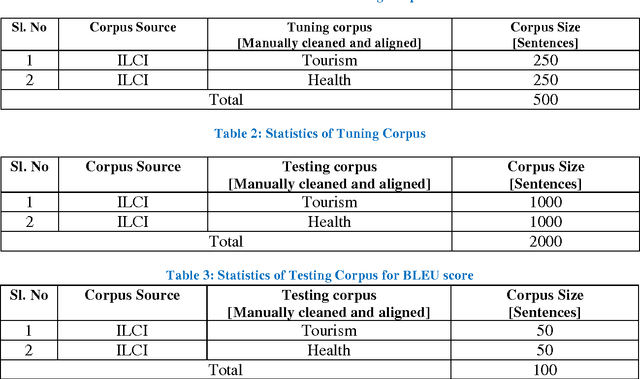
In this paper we present our work on a case study on Statistical Machine Translation (SMT) and Rule based machine translation (RBMT) for translation from English to Malayalam and Malayalam to English. One of the motivations of our study is to make a three way performance comparison, such as, a) SMT and RBMT b) English to Malayalam SMT and Malayalam to English SMT c) English to Malayalam RBMT and Malayalam to English RBMT. We describe the development of English to Malayalam and Malayalam to English baseline phrase based SMT system and the evaluation of its performance compared against the RBMT system. Based on our study the observations are: a) SMT systems outperform RBMT systems, b) In the case of SMT, English - Malayalam systems perform better than that of Malayalam - English systems, c) In the case RBMT, Malayalam to English systems are performing better than English to Malayalam systems. Based on our evaluations and detailed error analysis, we describe the requirements of incorporating morphological processing into the SMT to improve the accuracy of translation.