 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Tabular Denoising Diffusion Probabilistic Models for Time-Series Data Generation
Apr 06, 2026Diffusion models are increasingly being utilised to create synthetic tabular and time series data for privacy-preserving augmentation. Tabular Denoising Diffusion Probabilistic Models (TabDDPM) generate high-quality synthetic data from heterogeneous tabular datasets but assume independence between samples, limiting their applicability to time-series domains where temporal dependencies are critical. To address this, we propose a temporal extension of TabDDPM, introducing sequence awareness through the use of lightweight temporal adapters and context-aware embedding modules. By reformulating sensor data into windowed sequences and explicitly modeling temporal context via timestep embeddings, conditional activity labels, and observed/missing masks, our approach enables the generation of temporally coherent synthetic sequences. Compared to baseline and interpolation techniques, validation using bigram transition matrices and autocorrelation analysis shows enhanced temporal realism, diversity, and coherence. On the WISDM accelerometer dataset, the suggested system produces synthetic time-series that closely resemble real world sensor patterns and achieves comparable classification performance (macro F1-score 0.64, accuracy 0.71). This is especially advantageous for minority class representation and preserving statistical alignment with real distributions. These developments demonstrate that diffusion based models provide effective and adaptable solutions for sequential data synthesis when they are equipped for temporal reasoning. Future work will explore scaling to longer sequences and integrating stronger temporal architectures.
Summary of the Unusual Activity Recognition Challenge for Developmental Disability Support
Jan 21, 2026This paper presents an overview of the Recognize the Unseen: Unusual Behavior Recognition from Pose Data Challenge, hosted at ISAS 2025. The challenge aims to address the critical need for automated recognition of unusual behaviors in facilities for individuals with developmental disabilities using non-invasive pose estimation data. Participating teams were tasked with distinguishing between normal and unusual activities based on skeleton keypoints extracted from video recordings of simulated scenarios. The dataset reflects real-world imbalance and temporal irregularities in behavior, and the evaluation adopted a Leave-One-Subject-Out (LOSO) strategy to ensure subject-agnostic generalization. The challenge attracted broad participation from 40 teams applying diverse approaches ranging from classical machine learning to deep learning architectures. Submissions were assessed primarily using macro-averaged F1 scores to account for class imbalance. The results highlight the difficulty of modeling rare, abrupt actions in noisy, low-dimensional data, and emphasize the importance of capturing both temporal and contextual nuances in behavior modeling. Insights from this challenge may contribute to future developments in socially responsible AI applications for healthcare and behavior monitoring.
LLM-Guided Exemplar Selection for Few-Shot Wearable-Sensor Human Activity Recognition
Dec 26, 2025In this paper, we propose an LLM-Guided Exemplar Selection framework to address a key limitation in state-of-the-art Human Activity Recognition (HAR) methods: their reliance on large labeled datasets and purely geometric exemplar selection, which often fail to distinguish similar weara-ble sensor activities such as walking, walking upstairs, and walking downstairs. Our method incorporates semantic reasoning via an LLM-generated knowledge prior that captures feature importance, inter-class confusability, and exemplar budget multipliers, and uses it to guide exemplar scoring and selection. These priors are combined with margin-based validation cues, PageRank centrality, hubness penalization, and facility-location optimization to obtain a compact and informative set of exemplars. Evaluated on the UCI-HAR dataset under strict few-shot conditions, the framework achieves a macro F1-score of 88.78%, outperforming classical approaches such as random sampling, herding, and $k$-center. The results show that LLM-derived semantic priors, when integrated with structural and geometric cues, provide a stronger foundation for selecting representative sensor exemplars in few-shot wearable-sensor HAR.
Few-Shot Optimization for Sensor Data Using Large Language Models: A Case Study on Fatigue Detection
May 24, 2025In this paper, we propose a novel few-shot optimization with HED-LM (Hybrid Euclidean Distance with Large Language Models) to improve example selection for sensor-based classification tasks. While few-shot prompting enables efficient inference with limited labeled data, its performance largely depends on the quality of selected examples. HED-LM addresses this challenge through a hybrid selection pipeline that filters candidate examples based on Euclidean distance and re-ranks them using contextual relevance scored by large language models (LLMs). To validate its effectiveness, we apply HED-LM to a fatigue detection task using accelerometer data characterized by overlapping patterns and high inter-subject variability. Unlike simpler tasks such as activity recognition, fatigue detection demands more nuanced example selection due to subtle differences in physiological signals. Our experiments show that HED-LM achieves a mean macro F1-score of 69.13$\pm$10.71%, outperforming both random selection (59.30$\pm$10.13%) and distance-only filtering (67.61$\pm$11.39%). These represent relative improvements of 16.6% and 2.3%, respectively. The results confirm that combining numerical similarity with contextual relevance improves the robustness of few-shot prompting. Overall, HED-LM offers a practical solution to improve performance in real-world sensor-based learning tasks and shows potential for broader applications in healthcare monitoring, human activity recognition, and industrial safety scenarios.
Translation Between Waves, wave2wave
Jul 20, 2020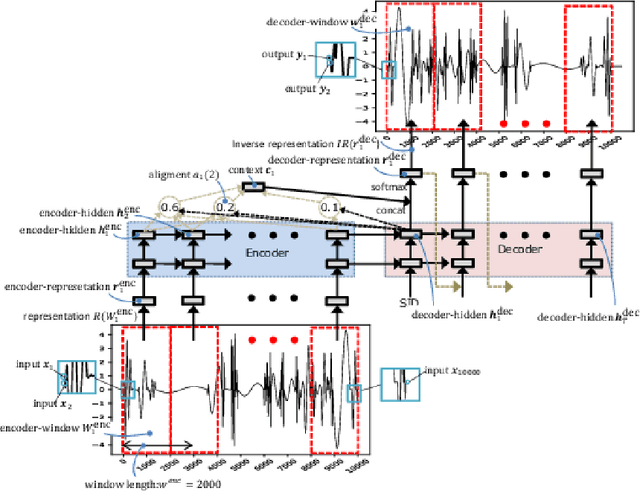
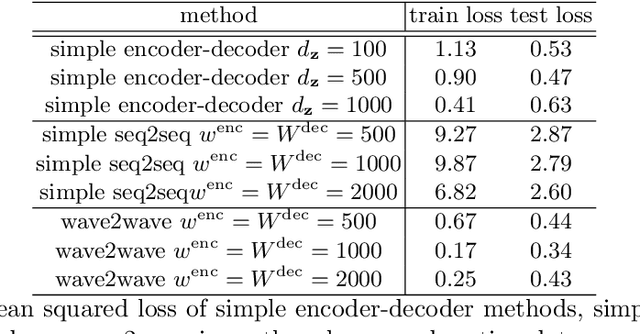
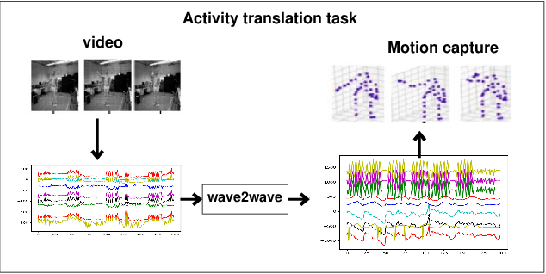
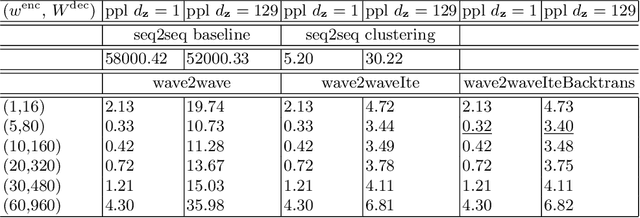
The understanding of sensor data has been greatly improved by advanced deep learning methods with big data. However, available sensor data in the real world are still limited, which is called the opportunistic sensor problem. This paper proposes a new variant of neural machine translation seq2seq to deal with continuous signal waves by introducing the window-based (inverse-) representation to adaptively represent partial shapes of waves and the iterative back-translation model for high-dimensional data. Experimental results are shown for two real-life data: earthquake and activity translation. The performance improvements of one-dimensional data was about 46% in test loss and that of high-dimensional data was about 1625% in perplexity with regard to the original seq2seq.
A dataset for complex activity recognition withmicro and macro activities in a cooking scenario
Jun 18, 2020
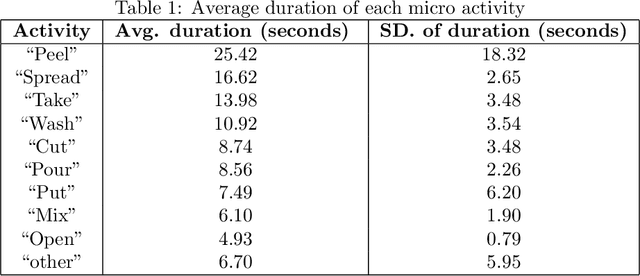
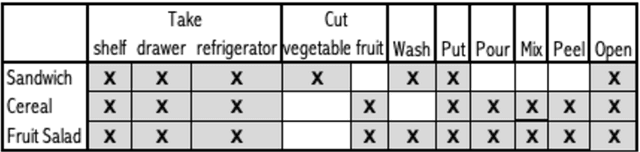
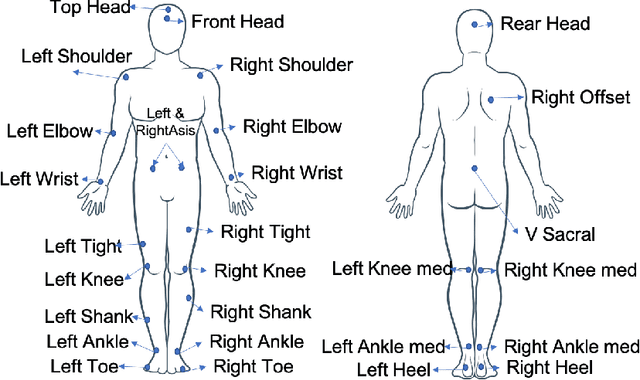
Complex activity recognition can benefit from understanding the steps that compose them. Current datasets, however, are annotated with one label only, hindering research in this direction. In this paper, we describe a new dataset for sensor-based activity recognition featuring macro and micro activities in a cooking scenario. Three sensing systems measured simultaneously, namely a motion capture system, tracking 25 points on the body; two smartphone accelerometers, one on the hip and the other one on the forearm; and two smartwatches one on each wrist. The dataset is labeled for both the recipes (macro activities) and the steps (micro activities). We summarize the results of a baseline classification using traditional activity recognition pipelines. The dataset is designed to be easily used to test and develop activity recognition approaches.
Deep Recurrent Neural Network for Mobile Human Activity Recognition with High Throughput
Nov 11, 2016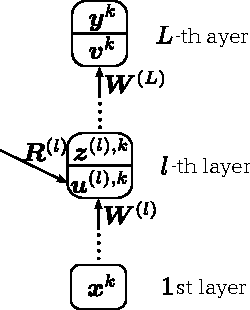
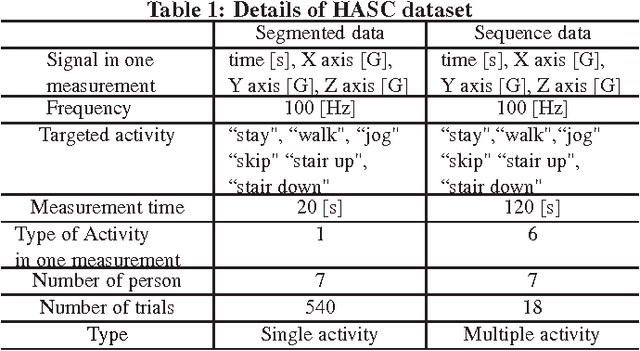
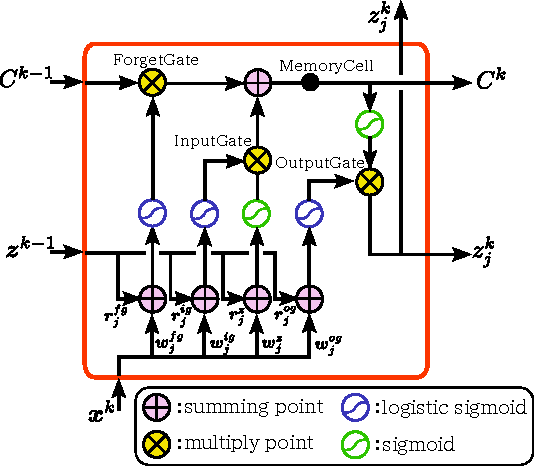
In this paper, we propose a method of human activity recognition with high throughput from raw accelerometer data applying a deep recurrent neural network (DRNN), and investigate various architectures and its combination to find the best parameter values. The "high throughput" refers to short time at a time of recognition. We investigated various parameters and architectures of the DRNN by using the training dataset of 432 trials with 6 activity classes from 7 people. The maximum recognition rate was 95.42% and 83.43% against the test data of 108 segmented trials each of which has single activity class and 18 multiple sequential trials, respectively. Here, the maximum recognition rates by traditional methods were 71.65% and 54.97% for each. In addition, the efficiency of the found parameters was evaluated by using additional dataset. Further, as for throughput of the recognition per unit time, the constructed DRNN was requiring only 1.347 [ms], while the best traditional method required 11.031 [ms] which includes 11.027 [ms] for feature calculation. These advantages are caused by the compact and small architecture of the constructed real time oriented DRNN.