 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegation is Not Semantic: Diagnosing Dense Retrieval Failure Modes for Trade-offs in Contradiction-Aware Biomedical QA
Mar 18, 2026Large Language Models (LLMs) have demonstrated strong capabilities in biomedical question answering, yet their tendency to generate plausible but unverified claims poses serious risks in clinical settings. To mitigate these risks, the TREC 2025 BioGen track mandates grounded answers that explicitly surface contradictory evidence (Task A) and the generation of narrative driven, fully attributed responses (Task B). Addressing the absence of target ground truth, we present a proxy-based development framework using the SciFact dataset to systematically optimize retrieval architectures. Our iterative evaluation revealed a "Simplicity Paradox": complex adversarial dense retrieval strategies failed catastrophically at contradiction detection (MRR 0.023) due to Semantic Collapse, where negation signals become indistinguishable in vector space. We further identify a Retrieval Asymmetry: filtering dense embeddings improves contradiction detection but degrades support recall, compromising reliability. We resolve this via a Decoupled Lexical Architecture built on a unified BM25 backbone, balancing semantic support recall (0.810) with precise contradiction surfacing (0.750). This approach achieves the highest Weighted MRR (0.790) on the proxy benchmark while remaining the only viable strategy for scaling to the 30 million document PubMed corpus. For answer generation, we introduce Narrative Aware Reranking and One-Shot In-Context Learning, improving citation coverage from 50% (zero-shot) to 100%. Official TREC results confirm our findings: our system ranks 2nd on Task A contradiction F1 and 3rd out of 50 runs on Task B citation coverage (98.77%), achieving zero citation contradict rate. Our work transforms LLMs from stochastic generators into honest evidence synthesizers, showing that epistemic integrity in biomedical AI requires precision and architectural scalability isolated metric optimization.
ILLUMINER: Instruction-tuned Large Language Models as Few-shot Intent Classifier and Slot Filler
Mar 26, 2024State-of-the-art intent classification (IC) and slot filling (SF) methods often rely on data-intensive deep learning models, limiting their practicality for industry applications. Large language models on the other hand, particularly instruction-tuned models (Instruct-LLMs), exhibit remarkable zero-shot performance across various natural language tasks. This study evaluates Instruct-LLMs on popular benchmark datasets for IC and SF, emphasizing their capacity to learn from fewer examples. We introduce ILLUMINER, an approach framing IC and SF as language generation tasks for Instruct-LLMs, with a more efficient SF-prompting method compared to prior work. A comprehensive comparison with multiple baselines shows that our approach, using the FLAN-T5 11B model, outperforms the state-of-the-art joint IC+SF method and in-context learning with GPT3.5 (175B), particularly in slot filling by 11.1--32.2 percentage points. Additionally, our in-depth ablation study demonstrates that parameter-efficient fine-tuning requires less than 6% of training data to yield comparable performance with traditional full-weight fine-tuning.
InCA: Rethinking In-Car Conversational System Assessment Leveraging Large Language Models
Nov 15, 2023



The assessment of advanced generative large language models (LLMs) poses a significant challenge, given their heightened complexity in recent developments. Furthermore, evaluating the performance of LLM-based applications in various industries, as indicated by Key Performance Indicators (KPIs), is a complex undertaking. This task necessitates a profound understanding of industry use cases and the anticipated system behavior. Within the context of the automotive industry, existing evaluation metrics prove inadequate for assessing in-car conversational question answering (ConvQA) systems. The unique demands of these systems, where answers may relate to driver or car safety and are confined within the car domain, highlight the limitations of current metrics. To address these challenges, this paper introduces a set of KPIs tailored for evaluating the performance of in-car ConvQA systems, along with datasets specifically designed for these KPIs. A preliminary and comprehensive empirical evaluation substantiates the efficacy of our proposed approach. Furthermore, we investigate the impact of employing varied personas in prompts and found that it enhances the model's capacity to simulate diverse viewpoints in assessments, mirroring how individuals with different backgrounds perceive a topic.
Data Augmentation using Feature Generation for Volumetric Medical Images
Sep 28, 2022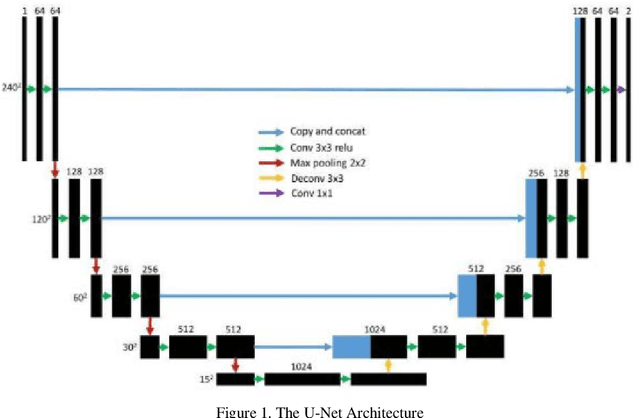
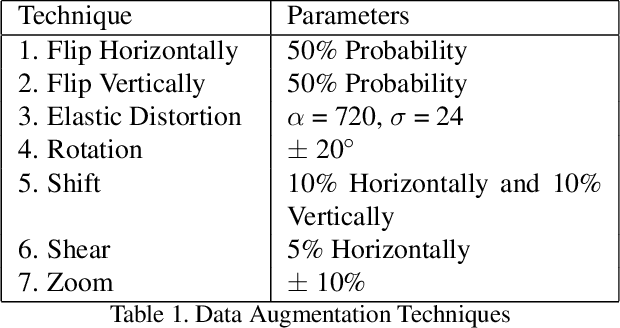
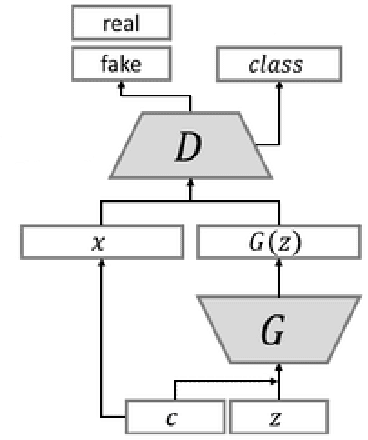
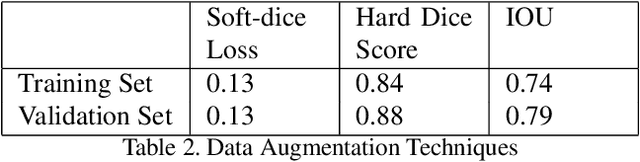
Medical image classification is one of the most critical problems in the image recognition area. One of the major challenges in this field is the scarcity of labelled training data. Additionally, there is often class imbalance in datasets as some cases are very rare to happen. As a result, accuracy in classification task is normally low. Deep Learning models, in particular, show promising results on image segmentation and classification problems, but they require very large datasets for training. Therefore, there is a need to generate more of synthetic samples from the same distribution. Previous work has shown that feature generation is more efficient and leads to better performance than corresponding image generation. We apply this idea in the Medical Imaging domain. We use transfer learning to train a segmentation model for the small dataset for which gold-standard class annotations are available. We extracted the learnt features and use them to generate synthetic features conditioned on class labels, using Auxiliary Classifier GAN (ACGAN). We test the quality of the generated features in a downstream classification task for brain tumors according to their severity level. Experimental results show a promising result regarding the validity of these generated features and their overall contribution to balancing the data and improving the classification class-wise accuracy.