 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Composite Quantization for High-Dimensional Similarity Search
Dec 19, 2019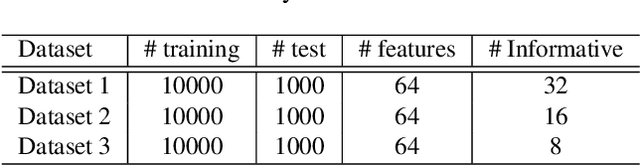
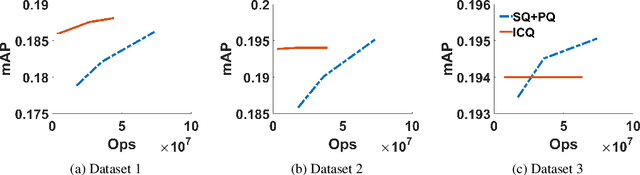
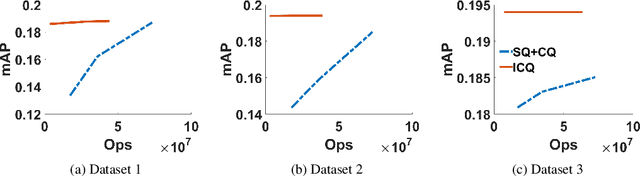
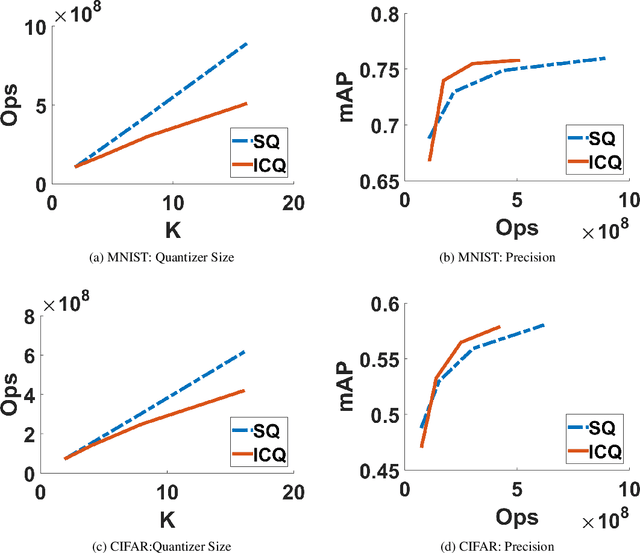
Similarity search retrieves the nearest neighbors of a query vector from a dataset of high-dimensional vectors. As the size of the dataset grows, the cost of performing the distance computations needed to implement a query can become prohibitive. A method often used to reduce this computational cost is quantization of the vector space and location-based encoding of the dataset vectors. These encodings can be used during query processing to find approximate nearest neighbors of the query point quickly. Search speed can be improved by using shorter codes, but shorter codes have higher quantization error, leading to degraded precision. In this work, we propose the Interleaved Composite Quantization (ICQ) which achieves fast similarity search without using shorter codes. In ICQ, a small subset of the code is used to approximate the distances, with complete codes being used only when necessary. Our method effectively reduces both code length and quantization error. Furthermore, ICQ is compatible with several recently proposed techniques for reducing quantization error and can be used in conjunction with these other techniques to improve results. We confirm these claims and show strong empirical performance of ICQ using several synthetic and real-word datasets.
TOCO: A Framework for Compressing Neural Network Models Based on Tolerance Analysis
Dec 19, 2019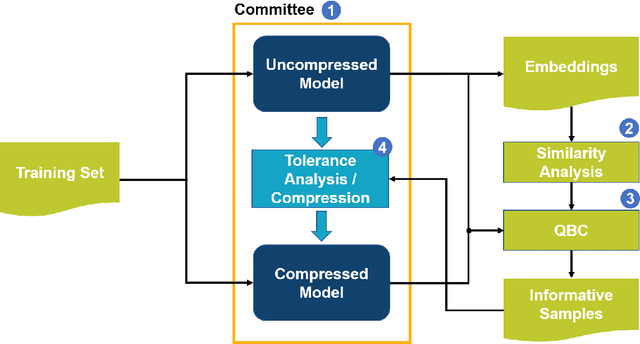

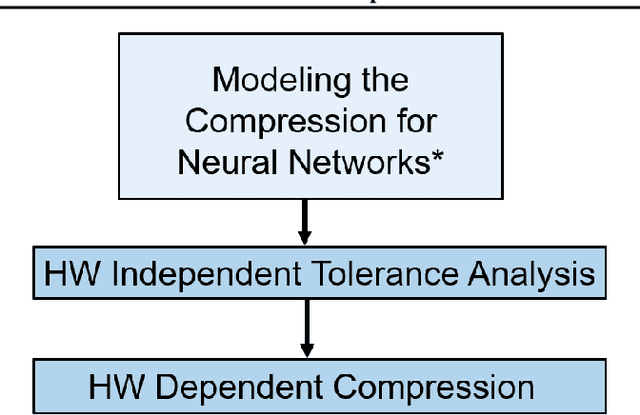
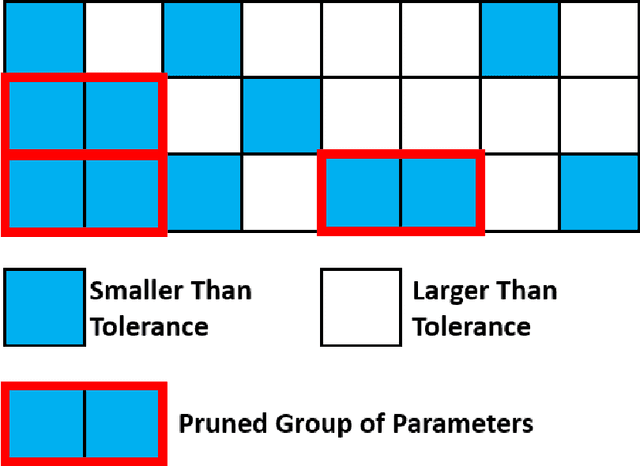
Neural network compression methods have enabled deploying large models on emerging edge devices with little cost, by adapting already-trained models to the constraints of these devices. The rapid development of AI-capable edge devices with limited computation and storage requires streamlined methodologies that can efficiently satisfy the constraints of different devices. In contrast, existing methods often rely on heuristic and manual adjustments to maintain accuracy, support only coarse compression policies, or target specific device constraints that limit their applicability. We address these limitations by proposing the TOlerance-based COmpression (TOCO) framework. TOCO uses an in-depth analysis of the model, to maintain the accuracy, in an active learning system. The results of the analysis are tolerances that can be used to perform compression in a fine-grained manner. Finally, by decoupling compression from the tolerance analysis, TOCO allows flexibility to changes in the hardware.