 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Visual Exemplars of Unseen Classes for Zero-Shot Learning
Aug 20, 2017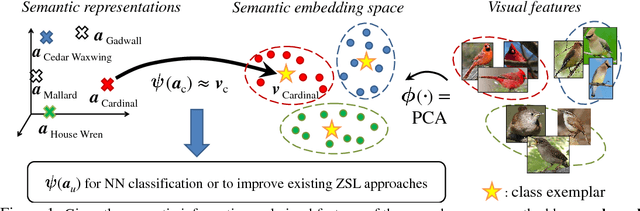
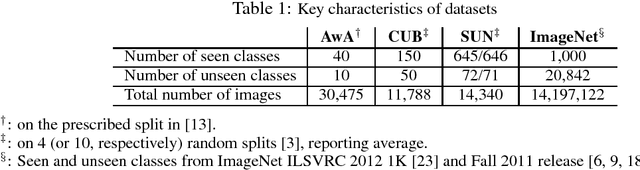

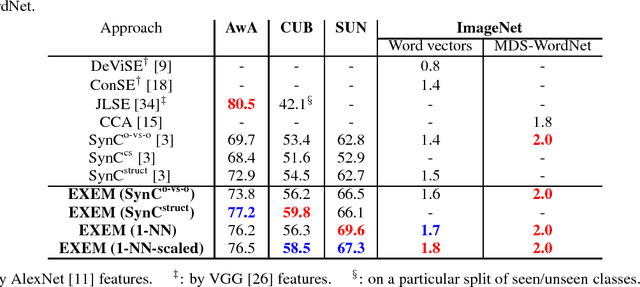
Leveraging class semantic descriptions and examples of known objects, zero-shot learning makes it possible to train a recognition model for an object class whose examples are not available. In this paper, we propose a novel zero-shot learning model that takes advantage of clustering structures in the semantic embedding space. The key idea is to impose the structural constraint that semantic representations must be predictive of the locations of their corresponding visual exemplars. To this end, this reduces to training multiple kernel-based regressors from semantic representation-exemplar pairs from labeled data of the seen object categories. Despite its simplicity, our approach significantly outperforms existing zero-shot learning methods on standard benchmark datasets, including the ImageNet dataset with more than 20,000 unseen categories.
The Power of Sparsity in Convolutional Neural Networks
Feb 21, 2017
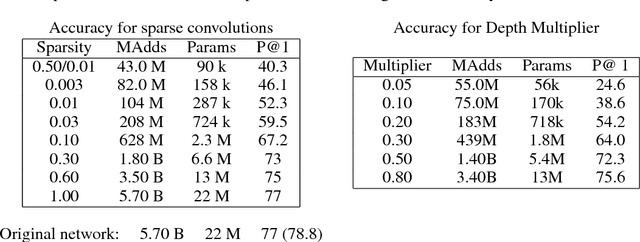
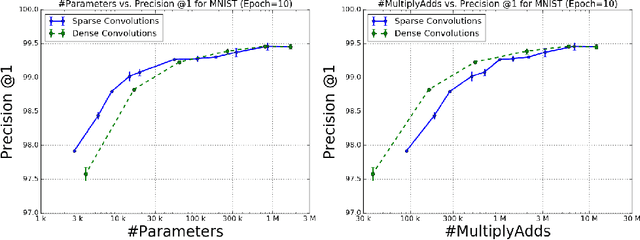
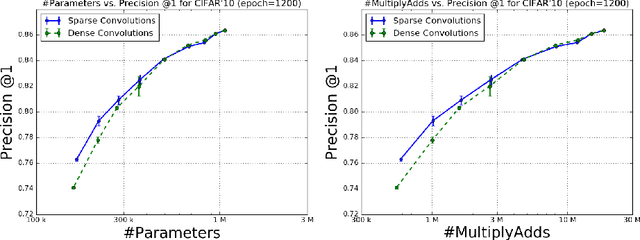
Deep convolutional networks are well-known for their high computational and memory demands. Given limited resources, how does one design a network that balances its size, training time, and prediction accuracy? A surprisingly effective approach to trade accuracy for size and speed is to simply reduce the number of channels in each convolutional layer by a fixed fraction and retrain the network. In many cases this leads to significantly smaller networks with only minimal changes to accuracy. In this paper, we take a step further by empirically examining a strategy for deactivating connections between filters in convolutional layers in a way that allows us to harvest savings both in run-time and memory for many network architectures. More specifically, we generalize 2D convolution to use a channel-wise sparse connection structure and show that this leads to significantly better results than the baseline approach for large networks including VGG and Inception V3.
An Empirical Study and Analysis of Generalized Zero-Shot Learning for Object Recognition in the Wild
Jan 11, 2017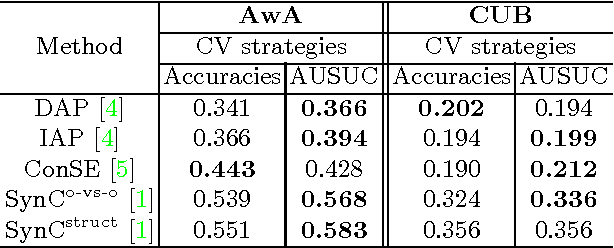
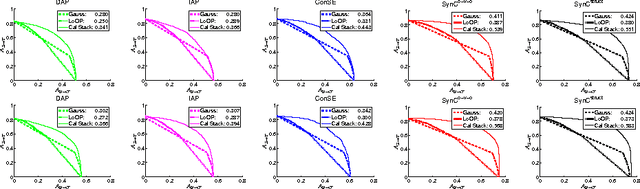
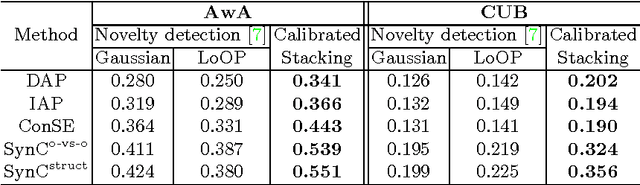
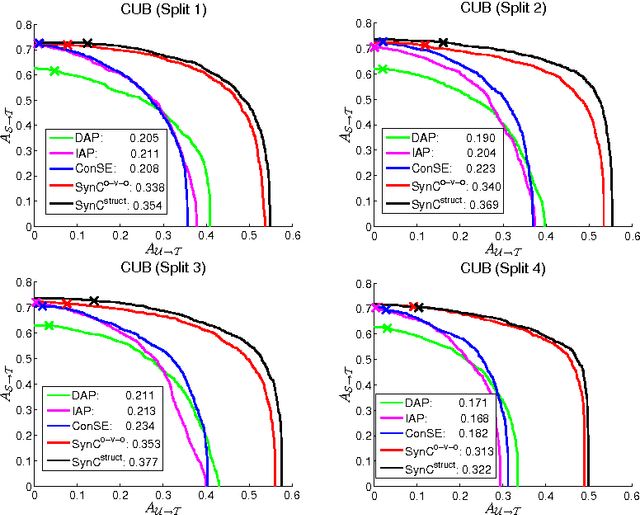
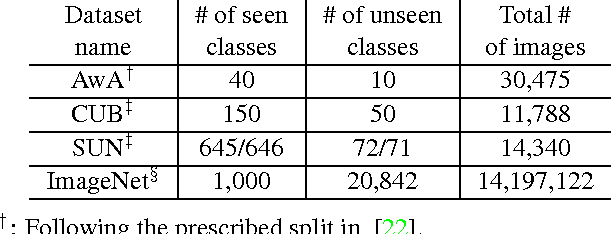
Zero-shot learning (ZSL) methods have been studied in the unrealistic setting where test data are assumed to come from unseen classes only. In this paper, we advocate studying the problem of generalized zero-shot learning (GZSL) where the test data's class memberships are unconstrained. We show empirically that naively using the classifiers constructed by ZSL approaches does not perform well in the generalized setting. Motivated by this, we propose a simple but effective calibration method that can be used to balance two conflicting forces: recognizing data from seen classes versus those from unseen ones. We develop a performance metric to characterize such a trade-off and examine the utility of this metric in evaluating various ZSL approaches. Our analysis further shows that there is a large gap between the performance of existing approaches and an upper bound established via idealized semantic embeddings, suggesting that improving class semantic embeddings is vital to GZSL.
Synthesized Classifiers for Zero-Shot Learning
May 27, 2016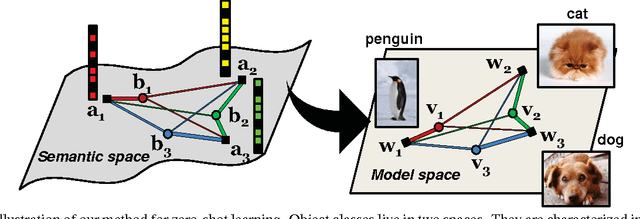
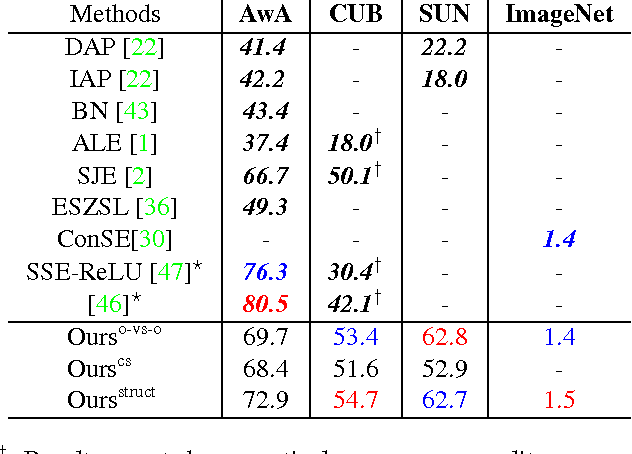
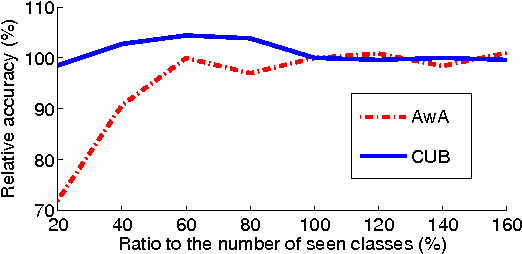
Given semantic descriptions of object classes, zero-shot learning aims to accurately recognize objects of the unseen classes, from which no examples are available at the training stage, by associating them to the seen classes, from which labeled examples are provided. We propose to tackle this problem from the perspective of manifold learning. Our main idea is to align the semantic space that is derived from external information to the model space that concerns itself with recognizing visual features. To this end, we introduce a set of "phantom" object classes whose coordinates live in both the semantic space and the model space. Serving as bases in a dictionary, they can be optimized from labeled data such that the synthesized real object classifiers achieve optimal discriminative performance. We demonstrate superior accuracy of our approach over the state of the art on four benchmark datasets for zero-shot learning, including the full ImageNet Fall 2011 dataset with more than 20,000 unseen classes.