 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Pixel-Unshuffled Network for Lightweight Image Super-Resolution
Mar 16, 2022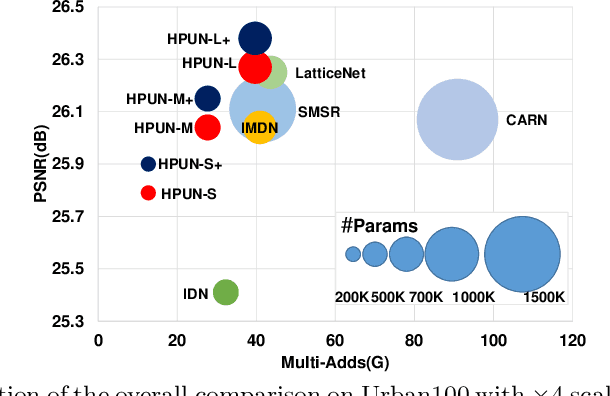
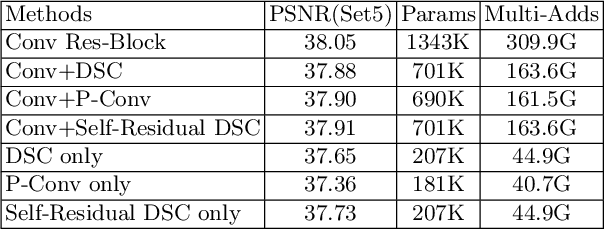

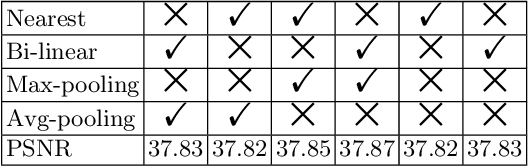
Convolutional neural network (CNN) has achieved great success on image super-resolution (SR). However, most deep CNN-based SR models take massive computations to obtain high performance. Downsampling features for multi-resolution fusion is an efficient and effective way to improve the performance of visual recognition. Still, it is counter-intuitive in the SR task, which needs to project a low-resolution input to high-resolution. In this paper, we propose a novel Hybrid Pixel-Unshuffled Network (HPUN) by introducing an efficient and effective downsampling module into the SR task. The network contains pixel-unshuffled downsampling and Self-Residual Depthwise Separable Convolutions. Specifically, we utilize pixel-unshuffle operation to downsample the input features and use grouped convolution to reduce the channels. Besides, we enhance the depthwise convolution's performance by adding the input feature to its output. Experiments on benchmark datasets show that our HPUN achieves and surpasses the state-of-the-art reconstruction performance with fewer parameters and computation costs.
Sign Language Recognition via Skeleton-Aware Multi-Model Ensemble
Oct 12, 2021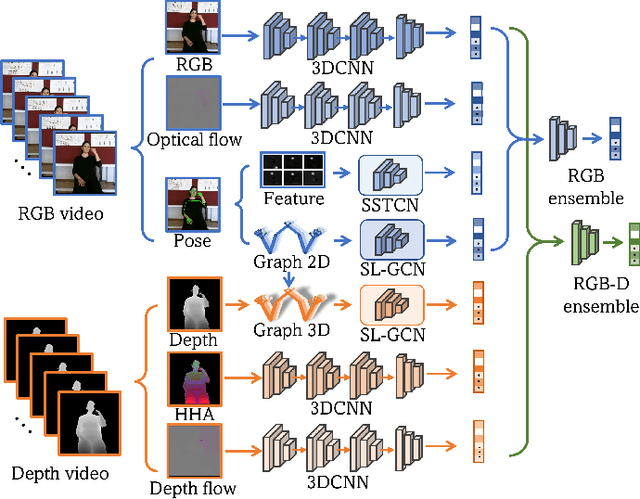
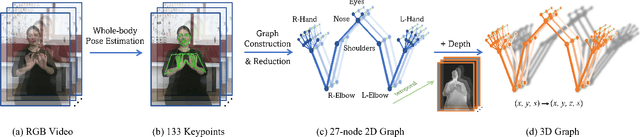
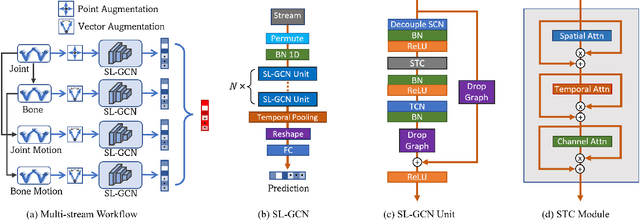
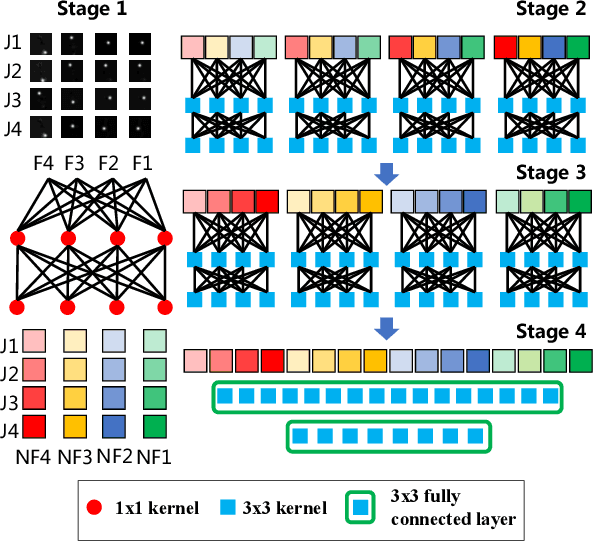
Sign language is commonly used by deaf or mute people to communicate but requires extensive effort to master. It is usually performed with the fast yet delicate movement of hand gestures, body posture, and even facial expressions. Current Sign Language Recognition (SLR) methods usually extract features via deep neural networks and suffer overfitting due to limited and noisy data. Recently, skeleton-based action recognition has attracted increasing attention due to its subject-invariant and background-invariant nature, whereas skeleton-based SLR is still under exploration due to the lack of hand annotations. Some researchers have tried to use off-line hand pose trackers to obtain hand keypoints and aid in recognizing sign language via recurrent neural networks. Nevertheless, none of them outperforms RGB-based approaches yet. To this end, we propose a novel Skeleton Aware Multi-modal Framework with a Global Ensemble Model (GEM) for isolated SLR (SAM-SLR-v2) to learn and fuse multi-modal feature representations towards a higher recognition rate. Specifically, we propose a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics of skeleton keypoints and a Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. The skeleton-based predictions are fused with other RGB and depth based modalities by the proposed late-fusion GEM to provide global information and make a faithful SLR prediction. Experiments on three isolated SLR datasets demonstrate that our proposed SAM-SLR-v2 framework is exceedingly effective and achieves state-of-the-art performance with significant margins. Our code will be available at https://github.com/jackyjsy/SAM-SLR-v2
Skeleton Aware Multi-modal Sign Language Recognition
Mar 26, 2021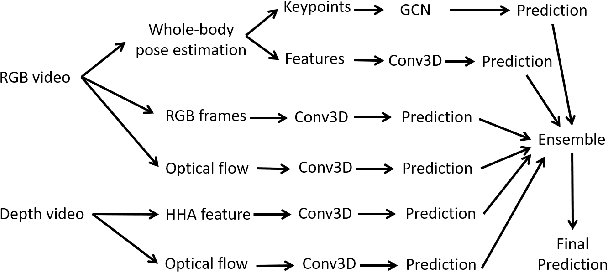
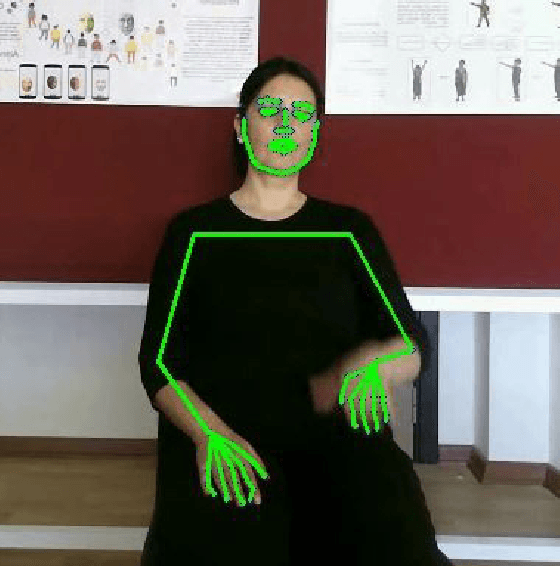
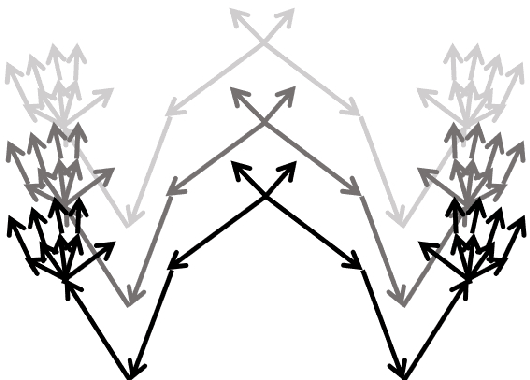
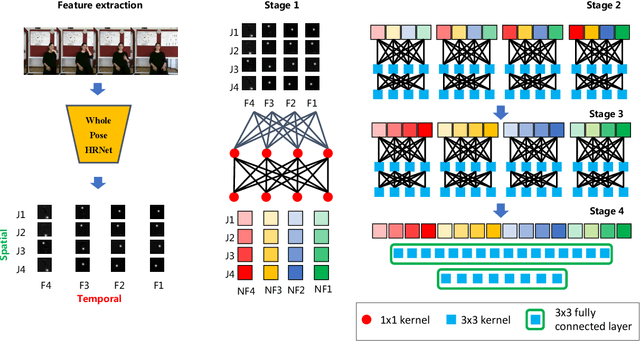
Sign language is used by deaf or speech impaired people to communicate and requires great effort to master. Sign Language Recognition (SLR) aims to bridge between sign language users and others by recognizing words from given videos. It is an important yet challenging task since sign language is performed with fast and complex movement of hand gestures, body posture, and even facial expressions. Recently, skeleton-based action recognition attracts increasing attention due to the independence on subject and background variation. Furthermore, it can be a strong complement to RGB/D modalities to boost the overall recognition rate. However, skeleton-based SLR is still under exploration due to the lack of annotations on hand keypoints. Some efforts have been made to use hand detectors with pose estimators to extract hand key points and learn to recognize sign language via a Recurrent Neural Network, but none of them outperforms RGB-based methods. To this end, we propose a novel Skeleton Aware Multi-modal SLR framework (SAM-SLR) to further improve the recognition rate. Specifically, we propose a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics and propose a novel Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. Our skeleton-based method achieves a higher recognition rate compared with all other single modalities. Moreover, our proposed SAM-SLR framework can further enhance the performance by assembling our skeleton-based method with other RGB and depth modalities. As a result, SAM-SLR achieves the highest performance in both RGB (98.42%) and RGB-D (98.53%) tracks in 2021 Looking at People Large Scale Signer Independent Isolated SLR Challenge. Our code is available at https://github.com/jackyjsy/CVPR21Chal-SLR
SuperFront: From Low-resolution to High-resolution Frontal Face Synthesis
Dec 07, 2020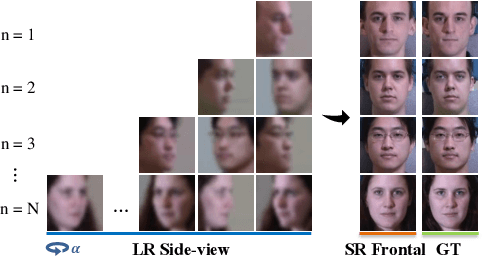
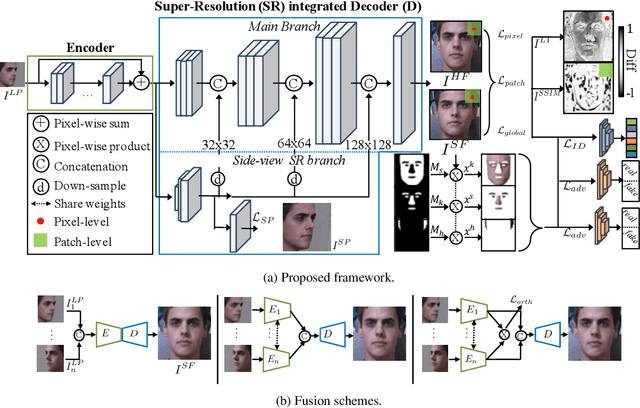
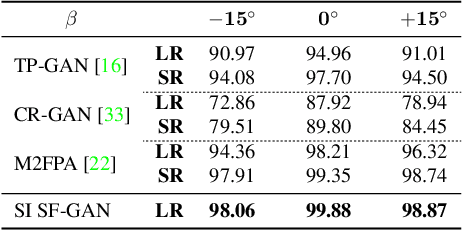
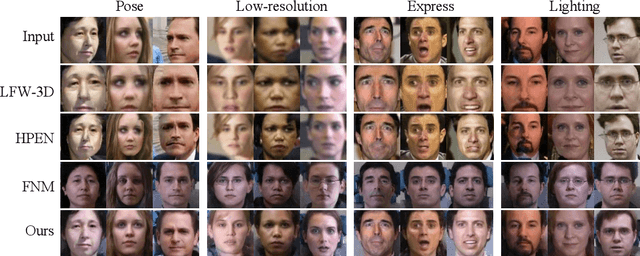
Advances in face rotation, along with other face-based generative tasks, are more frequent as we advance further in topics of deep learning. Even as impressive milestones are achieved in synthesizing faces, the importance of preserving identity is needed in practice and should not be overlooked. Also, the difficulty should not be more for data with obscured faces, heavier poses, and lower quality. Existing methods tend to focus on samples with variation in pose, but with the assumption data is high in quality. We propose a generative adversarial network (GAN) -based model to generate high-quality, identity preserving frontal faces from one or multiple low-resolution (LR) faces with extreme poses. Specifically, we propose SuperFront-GAN (SF-GAN) to synthesize a high-resolution (HR), frontal face from one-to-many LR faces with various poses and with the identity-preserved. We integrate a super-resolution (SR) side-view module into SF-GAN to preserve identity information and fine details of the side-views in HR space, which helps model reconstruct high-frequency information of faces (i.e., periocular, nose, and mouth regions). Moreover, SF-GAN accepts multiple LR faces as input, and improves each added sample. We squeeze additional gain in performance with an orthogonal constraint in the generator to penalize redundant latent representations and, hence, diversify the learned features space. Quantitative and qualitative results demonstrate the superiority of SF-GAN over others.
Dual-Attention GAN for Large-Pose Face Frontalization
Feb 17, 2020
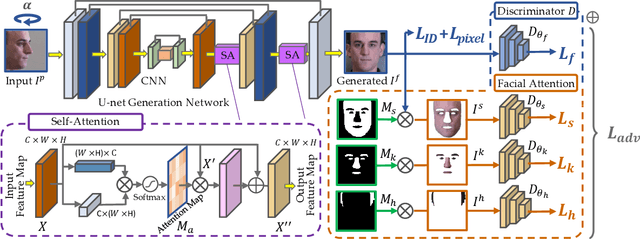


Face frontalization provides an effective and efficient way for face data augmentation and further improves the face recognition performance in extreme pose scenario. Despite recent advances in deep learning-based face synthesis approaches, this problem is still challenging due to significant pose and illumination discrepancy. In this paper, we present a novel Dual-Attention Generative Adversarial Network (DA-GAN) for photo-realistic face frontalization by capturing both contextual dependencies and local consistency during GAN training. Specifically, a self-attention-based generator is introduced to integrate local features with their long-range dependencies yielding better feature representations, and hence generate faces that preserve identities better, especially for larger pose angles. Moreover, a novel face-attention-based discriminator is applied to emphasize local features of face regions, and hence reinforce the realism of synthetic frontal faces. Guided by semantic segmentation, four independent discriminators are used to distinguish between different aspects of a face (\ie skin, keypoints, hairline, and frontalized face). By introducing these two complementary attention mechanisms in generator and discriminator separately, we can learn a richer feature representation and generate identity preserving inference of frontal views with much finer details (i.e., more accurate facial appearance and textures) comparing to the state-of-the-art. Quantitative and qualitative experimental results demonstrate the effectiveness and efficiency of our DA-GAN approach.
Spatially Constrained Generative Adversarial Networks for Conditional Image Generation
May 07, 2019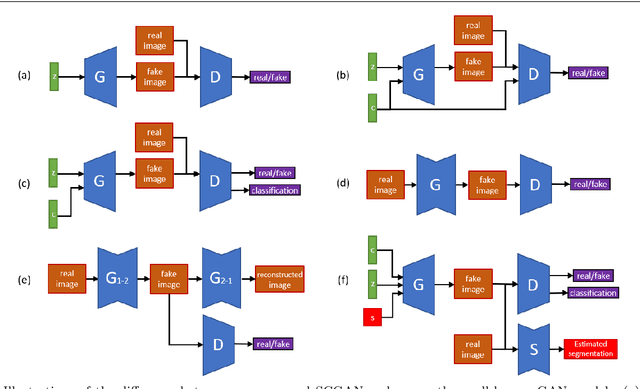
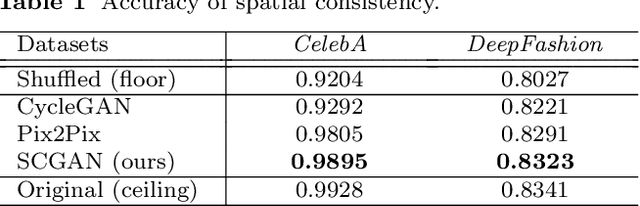
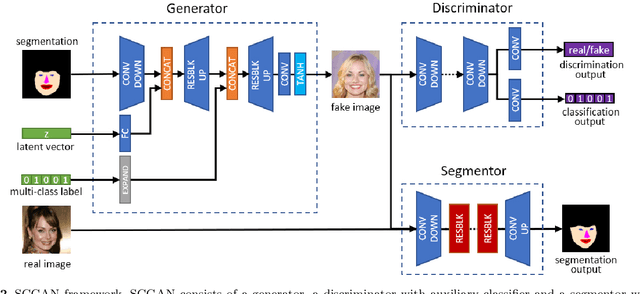
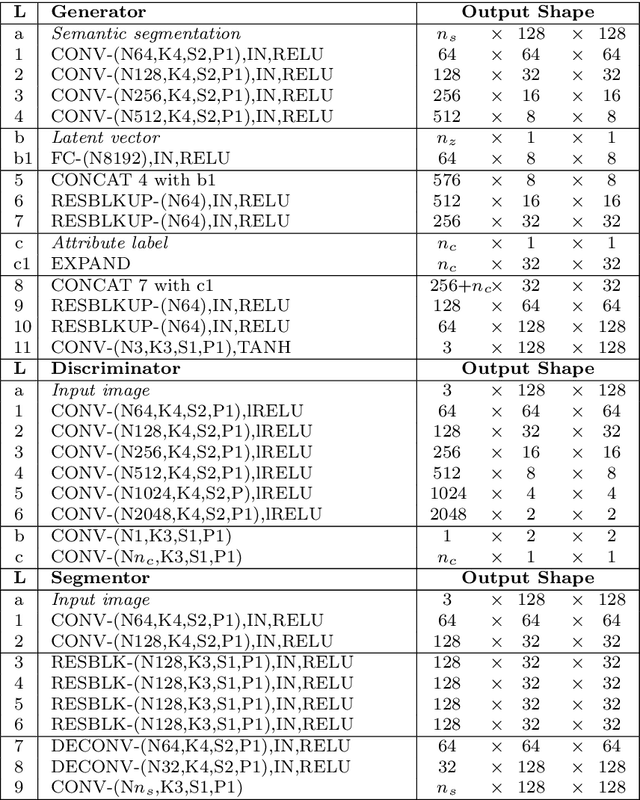
Image generation has raised tremendous attention in both academic and industrial areas, especially for the conditional and target-oriented image generation, such as criminal portrait and fashion design. Although the current studies have achieved preliminary results along this direction, they always focus on class labels as the condition where spatial contents are randomly generated from latent vectors. Edge details are usually blurred since spatial information is difficult to preserve. In light of this, we propose a novel Spatially Constrained Generative Adversarial Network (SCGAN), which decouples the spatial constraints from the latent vector and makes these constraints feasible as additional controllable signals. To enhance the spatial controllability, a generator network is specially designed to take a semantic segmentation, a latent vector and an attribute-level label as inputs step by step. Besides, a segmentor network is constructed to impose spatial constraints on the generator. Experimentally, we provide both visual and quantitative results on CelebA and DeepFashion datasets, and demonstrate that the proposed SCGAN is very effective in controlling the spatial contents as well as generating high-quality images.
Segmentation Guided Image-to-Image Translation with Adversarial Networks
Jan 06, 2019


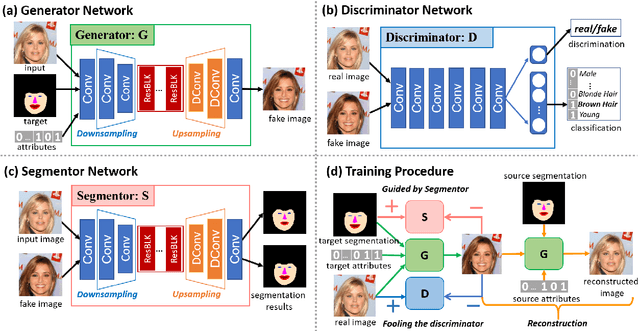
Recently image-to-image translation has received increasing attention, which aims to map images in one domain to another specific one. Existing methods mainly solve this task via a deep generative model, and focus on exploring the relationship between different domains. However, these methods neglect to utilize higher-level and instance-specific information to guide the training process, leading to a great deal of unrealistic generated images of low quality. Existing methods also lack of spatial controllability during translation. To address these challenge, we propose a novel Segmentation Guided Generative Adversarial Networks (SGGAN), which leverages semantic segmentation to further boost the generation performance and provide spatial mapping. In particular, a segmentor network is designed to impose semantic information on the generated images. Experimental results on multi-domain face image translation task empirically demonstrate our ability of the spatial modification and our superiority in image quality over several state-of-the-art methods.