 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Evidential Clustering
Jul 16, 2025Unsupervised classification is a fundamental machine learning problem. Real-world data often contain imperfections, characterized by uncertainty and imprecision, which are not well handled by traditional methods. Evidential clustering, based on Dempster-Shafer theory, addresses these challenges. This paper explores the underexplored problem of explaining evidential clustering results, which is crucial for high-stakes domains such as healthcare. Our analysis shows that, in the general case, representativity is a necessary and sufficient condition for decision trees to serve as abductive explainers. Building on the concept of representativity, we generalize this idea to accommodate partial labeling through utility functions. These functions enable the representation of "tolerable" mistakes, leading to the definition of evidential mistakeness as explanation cost and the construction of explainers tailored to evidential classifiers. Finally, we propose the Iterative Evidential Mistake Minimization (IEMM) algorithm, which provides interpretable and cautious decision tree explanations for evidential clustering functions. We validate the proposed algorithm on synthetic and real-world data. Taking into account the decision-maker's preferences, we were able to provide an explanation that was satisfactory up to 93% of the time.
A Deep Learning Framework for Recognizing both Static and Dynamic Gestures
Jun 11, 2020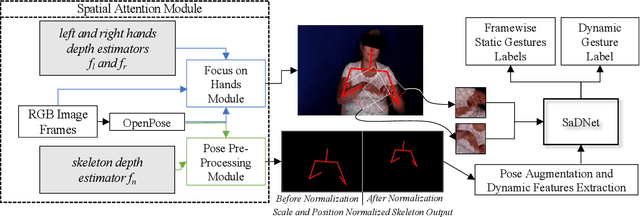
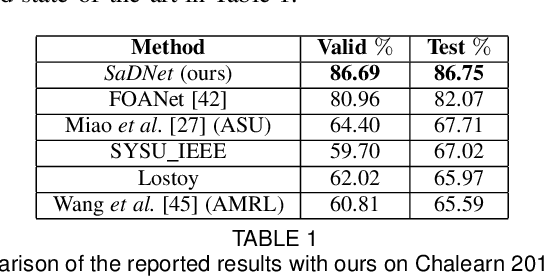


Intuitive user interfaces are indispensable to interact with human centric smart environments. In this paper, we propose a unified framework that recognizes both static and dynamic gestures, using simple RGB vision (without depth sensing). This feature makes it suitable for inexpensive human-machine interaction (HMI). We rely on a spatial attention-based strategy, which employs SaDNet, our proposed Static and Dynamic gestures Network. From the image of the human upper body, we estimate his/her depth, along with the region-of-interest around his/her hands. The Convolutional Neural Networks in SaDNet are fine-tuned on a background-substituted hand gestures dataset. They are utilized to detect 10 static gestures for each hand and to obtain hand image-embeddings from the last Fully Connected layer, which are subsequently fused with the augmented pose vector and then passed to stacked Long Short-Term Memory blocks. Thus, human-centered frame-wise information from the augmented pose vector and left/right hands image-embeddings are aggregated in time to predict the dynamic gestures of the performing person. In a number of experiments we show that the proposed approach surpasses the state-of-the-art results on large-scale Chalearn 2016 dataset. Moreover, we also transfer the knowledge learned through the proposed methodology to the Praxis gestures dataset, and the obtained results also outscore the state-of-the-art on this dataset.