 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMCD: Semantic-Statistical Framework for Causal Discovery
Feb 23, 2026We present DMCD (DataMap Causal Discovery), a two-phase causal discovery framework that integrates LLM-based semantic drafting from variable metadata with statistical validation on observational data. In Phase I, a large language model proposes a sparse draft DAG, serving as a semantically informed prior over the space of possible causal structures. In Phase II, this draft is audited and refined via conditional independence testing, with detected discrepancies guiding targeted edge revisions. We evaluate our approach on three metadata-rich real-world benchmarks spanning industrial engineering, environmental monitoring, and IT systems analysis. Across these datasets, DMCD achieves competitive or leading performance against diverse causal discovery baselines, with particularly large gains in recall and F1 score. Probing and ablation experiments suggest that these improvements arise from semantic reasoning over metadata rather than memorization of benchmark graphs. Overall, our results demonstrate that combining semantic priors with principled statistical verification yields a high-performing and practically effective approach to causal structure learning.
Generating image captions with external encyclopedic knowledge
Oct 10, 2022

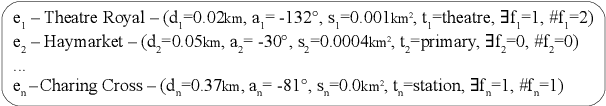

Accurately reporting what objects are depicted in an image is largely a solved problem in automatic caption generation. The next big challenge on the way to truly humanlike captioning is being able to incorporate the context of the image and related real world knowledge. We tackle this challenge by creating an end-to-end caption generation system that makes extensive use of image-specific encyclopedic data. Our approach includes a novel way of using image location to identify relevant open-domain facts in an external knowledge base, with their subsequent integration into the captioning pipeline at both the encoding and decoding stages. Our system is trained and tested on a new dataset with naturally produced knowledge-rich captions, and achieves significant improvements over multiple baselines. We empirically demonstrate that our approach is effective for generating contextualized captions with encyclopedic knowledge that is both factually accurate and relevant to the image.