 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMCD: Semantic-Statistical Framework for Causal Discovery
Feb 23, 2026We present DMCD (DataMap Causal Discovery), a two-phase causal discovery framework that integrates LLM-based semantic drafting from variable metadata with statistical validation on observational data. In Phase I, a large language model proposes a sparse draft DAG, serving as a semantically informed prior over the space of possible causal structures. In Phase II, this draft is audited and refined via conditional independence testing, with detected discrepancies guiding targeted edge revisions. We evaluate our approach on three metadata-rich real-world benchmarks spanning industrial engineering, environmental monitoring, and IT systems analysis. Across these datasets, DMCD achieves competitive or leading performance against diverse causal discovery baselines, with particularly large gains in recall and F1 score. Probing and ablation experiments suggest that these improvements arise from semantic reasoning over metadata rather than memorization of benchmark graphs. Overall, our results demonstrate that combining semantic priors with principled statistical verification yields a high-performing and practically effective approach to causal structure learning.
Beyond Accuracy: A Stability-Aware Metric for Multi-Horizon Forecasting
Jan 15, 2026Traditional time series forecasting methods optimize for accuracy alone. This objective neglects temporal consistency, in other words, how consistently a model predicts the same future event as the forecast origin changes. We introduce the forecast accuracy and coherence score (forecast AC score for short) for measuring the quality of probabilistic multi-horizon forecasts in a way that accounts for both multi-horizon accuracy and stability. Our score additionally provides for user-specified weights to balance accuracy and consistency requirements. As an example application, we implement the score as a differentiable objective function for training seasonal ARIMA models and evaluate it on the M4 Hourly benchmark dataset. Results demonstrate substantial improvements over traditional maximum likelihood estimation. Our AC-optimized models achieve a 75\% reduction in forecast volatility for the same target timestamps while maintaining comparable or improved point forecast accuracy.
Causify DataFlow: A Framework For High-performance Machine Learning Stream Computing
Dec 30, 2025We present DataFlow, a computational framework for building, testing, and deploying high-performance machine learning systems on unbounded time-series data. Traditional data science workflows assume finite datasets and require substantial reimplementation when moving from batch prototypes to streaming production systems. This gap introduces causality violations, batch boundary artifacts, and poor reproducibility of real-time failures. DataFlow resolves these issues through a unified execution model based on directed acyclic graphs (DAGs) with point-in-time idempotency: outputs at any time t depend only on a fixed-length context window preceding t. This guarantee ensures that models developed in batch mode execute identically in streaming production without code changes. The framework enforces strict causality by automatically tracking knowledge time across all transformations, eliminating future-peeking bugs. DataFlow supports flexible tiling across temporal and feature dimensions, allowing the same model to operate at different frequencies and memory profiles via configuration alone. It integrates natively with the Python data science stack and provides fit/predict semantics for online learning, caching and incremental computation, and automatic parallelization through DAG-based scheduling. We demonstrate its effectiveness across domains including financial trading, IoT, fraud detection, and real-time analytics.
Causal Inference in Energy Demand Prediction
Dec 17, 2025Energy demand prediction is critical for grid operators, industrial energy consumers, and service providers. Energy demand is influenced by multiple factors, including weather conditions (e.g. temperature, humidity, wind speed, solar radiation), and calendar information (e.g. hour of day and month of year), which further affect daily work and life schedules. These factors are causally interdependent, making the problem more complex than simple correlation-based learning techniques satisfactorily allow for. We propose a structural causal model that explains the causal relationship between these variables. A full analysis is performed to validate our causal beliefs, also revealing important insights consistent with prior studies. For example, our causal model reveals that energy demand responds to temperature fluctuations with season-dependent sensitivity. Additionally, we find that energy demand exhibits lower variance in winter due to the decoupling effect between temperature changes and daily activity patterns. We then build a Bayesian model, which takes advantage of the causal insights we learned as prior knowledge. The model is trained and tested on unseen data and yields state-of-the-art performance in the form of a 3.84 percent MAPE on the test set. The model also demonstrates strong robustness, as the cross-validation across two years of data yields an average MAPE of 3.88 percent.
On the Estimation of Entropy in the FastICA Algorithm
Jul 19, 2018
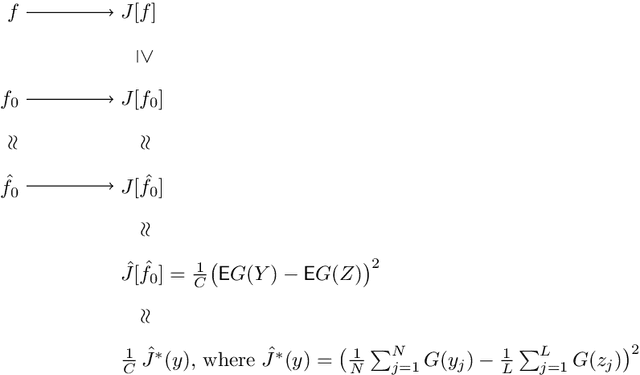
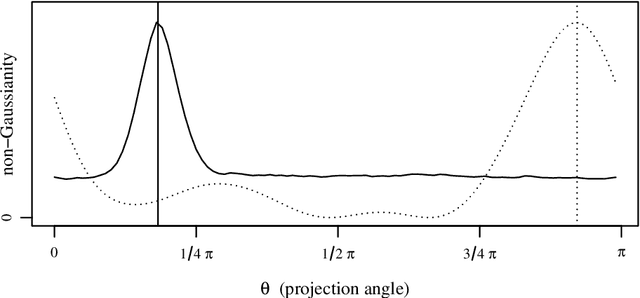
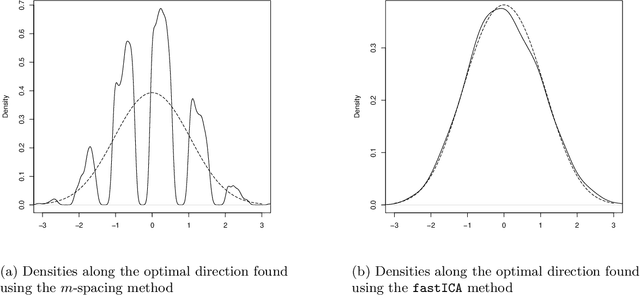
The fastICA algorithm is a popular dimension reduction technique used to reveal patterns in data. Here we show that the approximations used in fastICA can result in patterns not being successfully recognised. We demonstrate this problem using a two-dimensional example where a clear structure is immediately visible to the naked eye, but where the projection chosen by fastICA fails to reveal this structure. This implies that care is needed when applying fastICA. We discuss how the problem arises and how it is intrinsically connected to the approximations that form the basis of the computational efficiency of fastICA.