 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel APSM for Fast and Adaptive Digital SIC in Full-Duplex Transceivers with Nonlinearity
Jul 12, 2022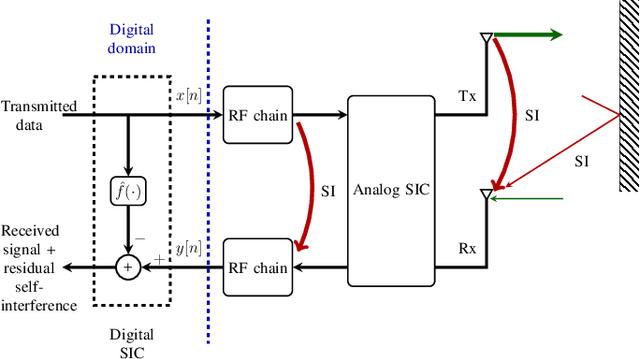
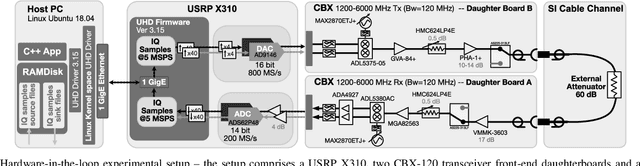
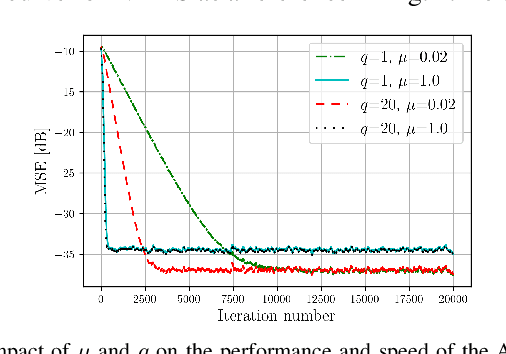
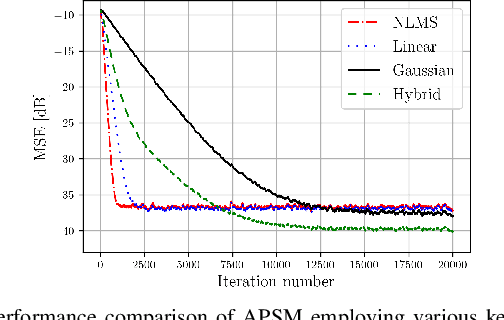
This paper presents a kernel-based adaptive filter that is applied for the digital domain self-interference cancellation (SIC) in a transceiver operating in full-duplex (FD) mode. In FD, the benefit of simultaneous transmission and receiving of signals comes at the price of strong self-interference (SI). In this work, we are primarily interested in suppressing the SI using an adaptive filter namely adaptive projected subgradient method (APSM) in a reproducing kernel Hilbert space (RKHS) of functions. Using the projection concept as a powerful tool, APSM is used to model and consequently remove the SI. A low-complexity and fast-tracking algorithm is provided taking advantage of parallel projections as well as the kernel trick in RKHS. The performance of the proposed method is evaluated on real measurement data. The method illustrates the good performance of the proposed adaptive filter, compared to the known popular benchmarks. They demonstrate that the kernel-based algorithm achieves a favorable level of digital SIC while enabling parallel computation-based implementation within a rich and nonlinear function space, thanks to the employed adaptive filtering method.
A Learning-Based Approach to Approximate Coded Computation
May 19, 2022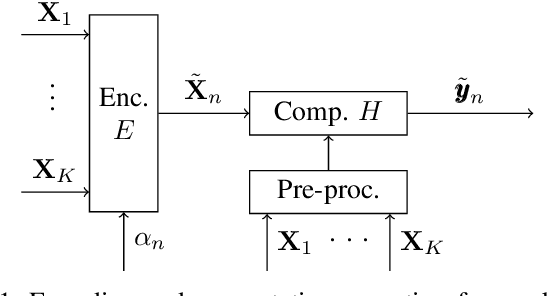
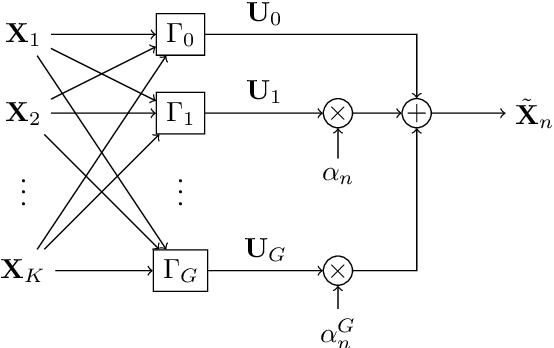
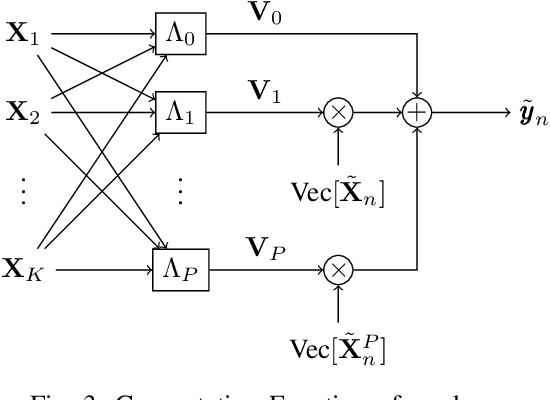
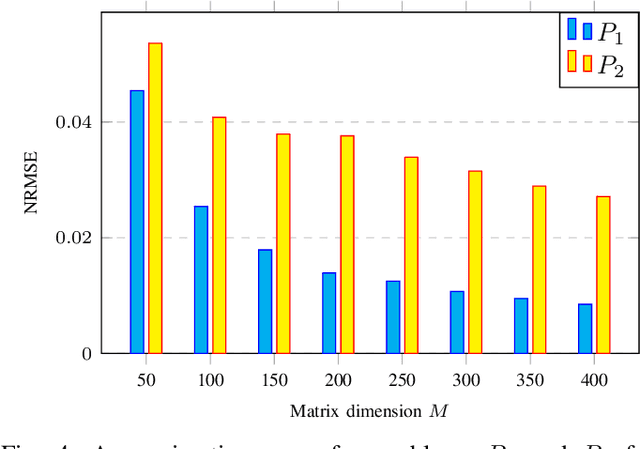
Lagrange coded computation (LCC) is essential to solving problems about matrix polynomials in a coded distributed fashion; nevertheless, it can only solve the problems that are representable as matrix polynomials. In this paper, we propose AICC, an AI-aided learning approach that is inspired by LCC but also uses deep neural networks (DNNs). It is appropriate for coded computation of more general functions. Numerical simulations demonstrate the suitability of the proposed approach for the coded computation of different matrix functions that are often utilized in digital signal processing.
Closed-form max-min power control for some cellular and cell-free massive MIMO networks
May 03, 2022
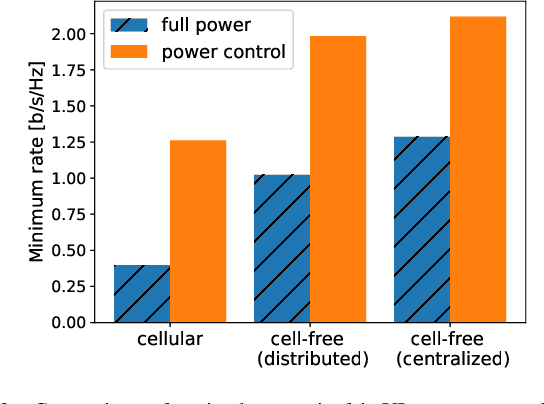
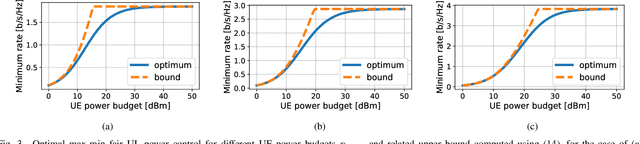
Many common instances of power control problems for cellular and cell-free massive MIMO networks can be interpreted as max-min utility optimization problems involving affine interference mappings and polyhedral constraints. We show that these problems admit a closed-form solution which depends on the spectral radius of known matrices. In contrast, previous solutions in the literature have been indirectly obtained using iterative algorithms based on the bisection method, or on fixed-point iterations. Furthermore, we also show an asymptotically tight bound for the optimal utility, which in turn provides a simple rule of thumb for evaluating whether the network is operating in the noise or interference limited regime. We finally illustrate our results by focusing on classical max-min fair power control for cell-free massive MIMO networks.
Superiorized Adaptive Projected Subgradient Method with Application to MIMO Detection
Mar 09, 2022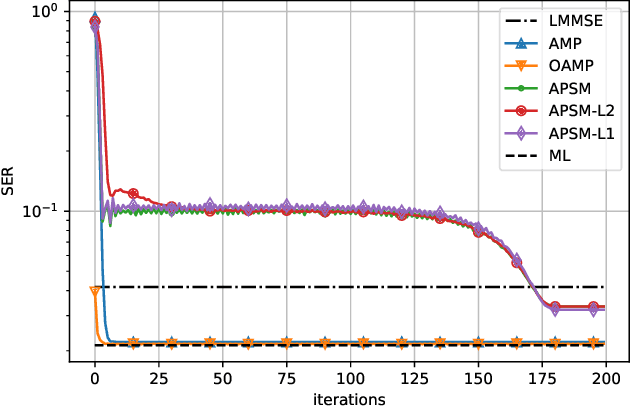
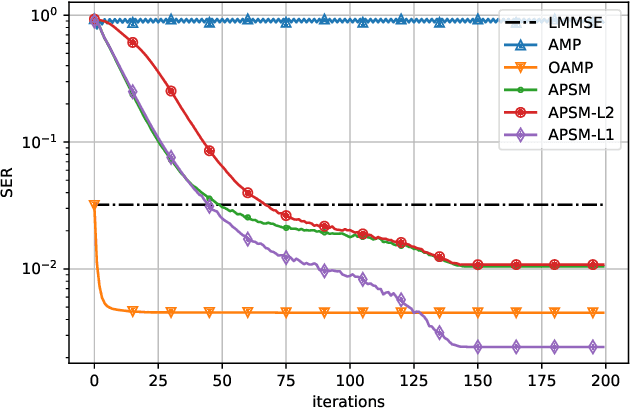
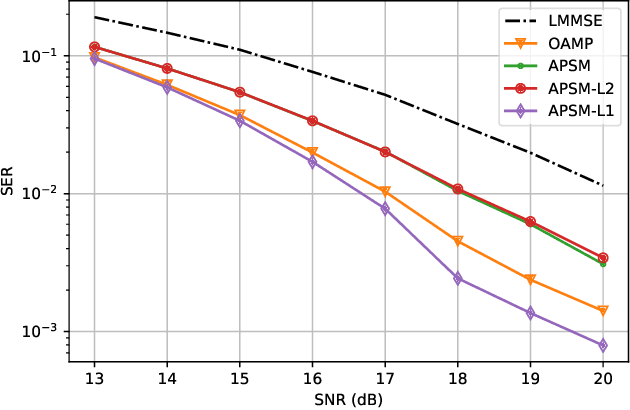
In this paper, we show that the adaptive projected subgradient method (APSM) is bounded perturbation resilient. To illustrate a potential application of this result, we propose a set-theoretic framework for MIMO detection, and we devise algorithms based on a superiorized APSM. Various low-complexity MIMO detection algorithms achieve excellent performance on i.i.d. Gaussian channels, but they typically incur high performance loss if realistic channel models are considered. Compared to existing low-complexity iterative detectors such as approximate message passing (AMP), the proposed algorithms can achieve considerably lower symbol error ratios over correlated channels. At the same time, the proposed methods do not require matrix inverses, and their complexity is similar to AMP.
Unsupervised Domain Adaptation across FMCW Radar Configurations Using Margin Disparity Discrepancy
Mar 09, 2022
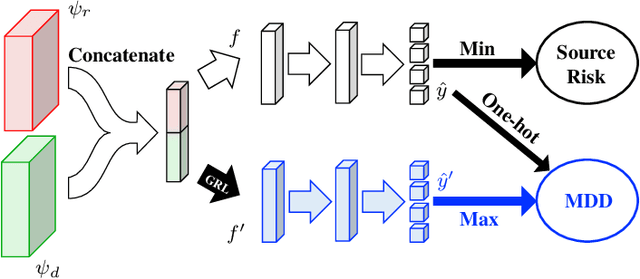
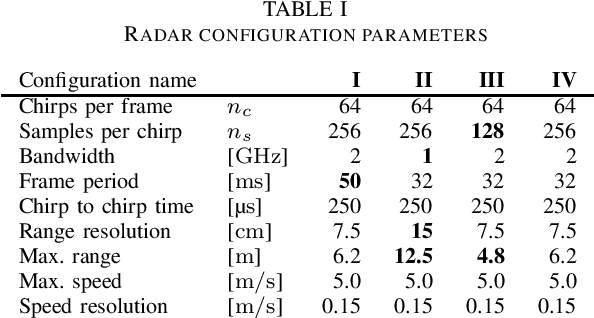
Commercial radar sensing is gaining relevance and machine learning algorithms constitute one of the key components that are enabling the spread of this radio technology into areas like surveillance or healthcare. However, radar datasets are still scarce and generalization cannot be yet achieved for all radar systems, environment conditions or design parameters. A certain degree of fine tuning is, therefore, usually required to deploy machine-learning-enabled radar applications. In this work, we consider the problem of unsupervised domain adaptation across radar configurations in the context of deep-learning human activity classification using frequency-modulated continuous-wave. For that, we focus on the theory-inspired technique of Margin Disparity Discrepancy, which has already been proved successful in the area of computer vision. Our experiments extend this technique to radar data, achieving a comparable accuracy to fewshot supervised approaches for the same classification problem.
Enabling sub-THz Cloud RANs: Distributed Machine-Learning for Early HARQ Feedback Prediction
Feb 18, 2022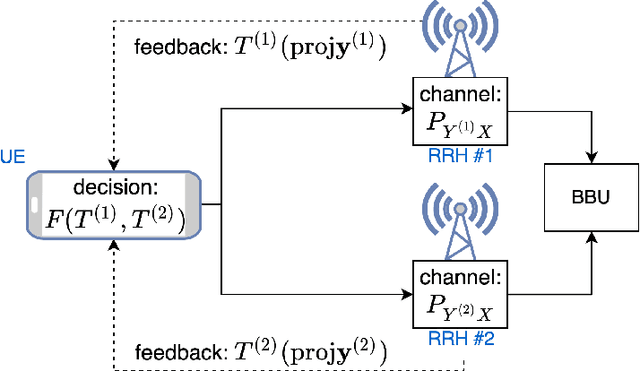
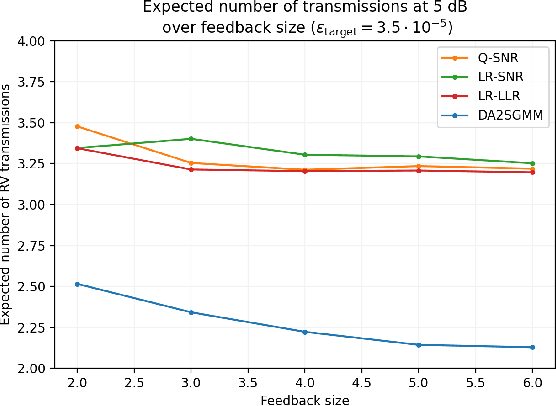
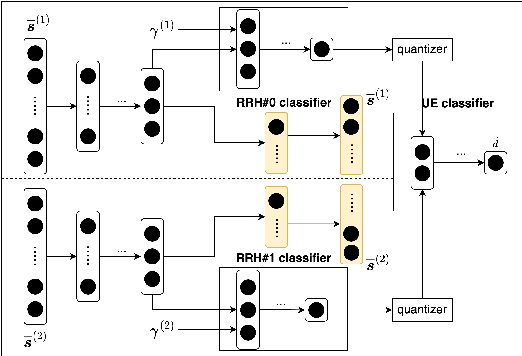
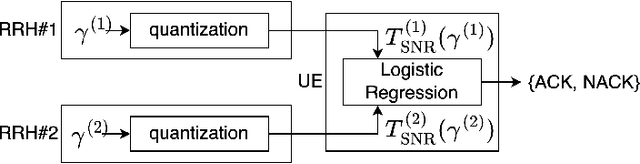
We propose novel HARQ prediction schemes for Cloud RANs (C-RANs) that use feedback over a rate-limited feedback channel (4 and 8 bits) from the Remote Radio Heads (RRHs) to predict at the User Equipment (UE) the decoding outcome at the BaseBand Unit (BBU) ahead of actual decoding. In particular, we propose a novel dual-input denoising autoencoder that is trained in a joint end-to-end fashion over the whole C-RAN setup. In realistic link-level simulations at 100 GHz in the sub-THz band, we show that a combination of the novel dual-input denoising autoencoder and state-of-the-art SNR-based HARQ feedback prediction achieves the overall best performance in all scenarios compared to other proposed and state-of-the-art single prediction schemes. At very low target error rates down to $1.6 \cdot 10^{-5}$, this combined approach reduces the number of required transmission rounds by up to 50\% compared to always transmitting all redundancy.
Transfer Learning in Multi-Agent Reinforcement Learning with Double Q-Networks for Distributed Resource Sharing in V2X Communication
Jul 13, 2021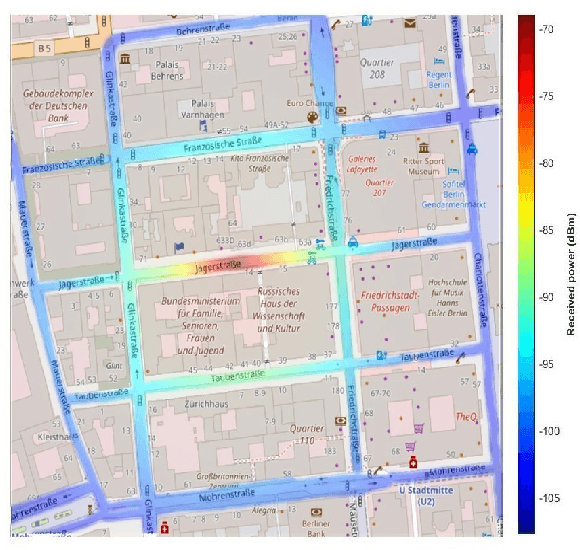
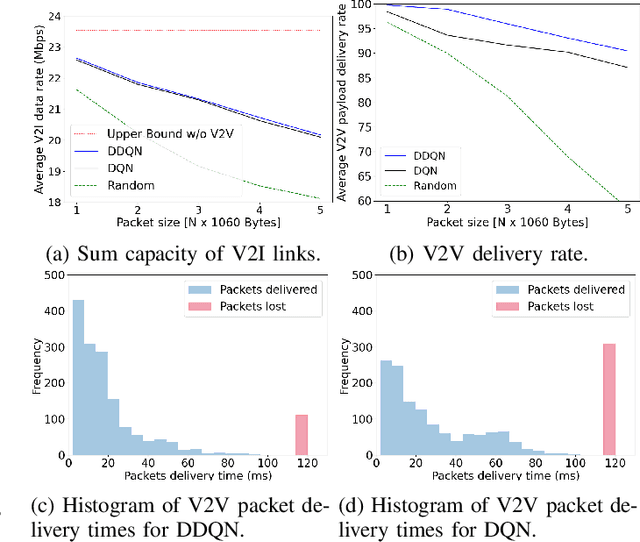
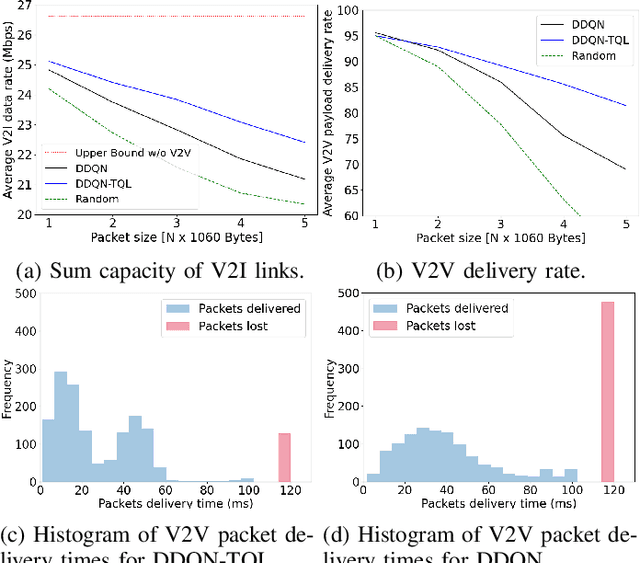
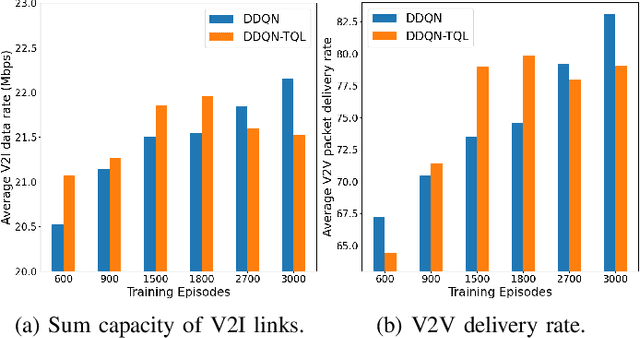
This paper addresses the problem of decentralized spectrum sharing in vehicle-to-everything (V2X) communication networks. The aim is to provide resource-efficient coexistence of vehicle-to-infrastructure(V2I) and vehicle-to-vehicle(V2V) links. A recent work on the topic proposes a multi-agent reinforcement learning (MARL) approach based on deep Q-learning, which leverages a fingerprint-based deep Q-network (DQN) architecture. This work considers an extension of this framework by combining Double Q-learning (via Double DQN) and transfer learning. The motivation behind is that Double Q-learning can alleviate the problem of overestimation of the action values present in conventional Q-learning, while transfer learning can leverage knowledge acquired by an expert model to accelerate learning in the MARL setting. The proposed algorithm is evaluated in a realistic V2X setting, with synthetic data generated based on a geometry-based propagation model that incorporates location-specific geographical descriptors of the simulated environment(outlines of buildings, foliage, and vehicles). The advantages of the proposed approach are demonstrated via numerical simulations.
Leveraging Machine Learning for Industrial Wireless Communications
May 05, 2021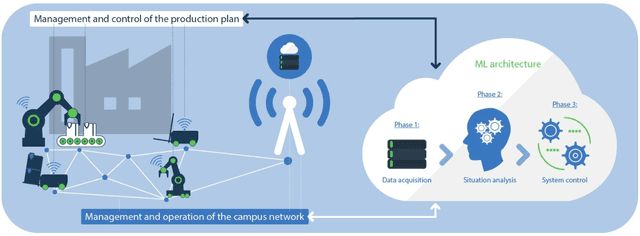
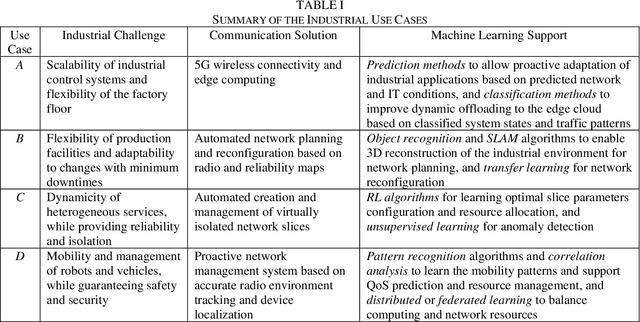
Two main trends characterize today's communication landscape and are finding their way into industrial facilities: the rollout of 5G with its distinct support for vertical industries and the increasing success of machine learning (ML). The combination of those two technologies open the doors to many exciting industrial applications and its impact is expected to rapidly increase in the coming years, given the abundant data growth and the availability of powerful edge computers in production facilities. Unlike most previous work that has considered the application of 5G and ML in industrial environment separately, this paper highlights the potential and synergies that result from combining them. The overall vision presented here generates from the KICK project, a collaboration of several partners from the manufacturing and communication industry as well as research institutes. This unprecedented blend of 5G and ML expertise creates a unique perspective on ML-supported industrial communications and their role in facilitating industrial automation. The paper identifies key open industrial challenges that are grouped into four use cases: wireless connectivity and edge-cloud integration, flexibility in network reconfiguration, dynamicity of heterogeneous network services, and mobility of robots and vehicles. Moreover, the paper provides insights into the advantages of ML-based industrial communications and discusses current challenges of data acquisition in real systems.
Robust Cell-Load Learning with a Small Sample Set
Mar 21, 2021
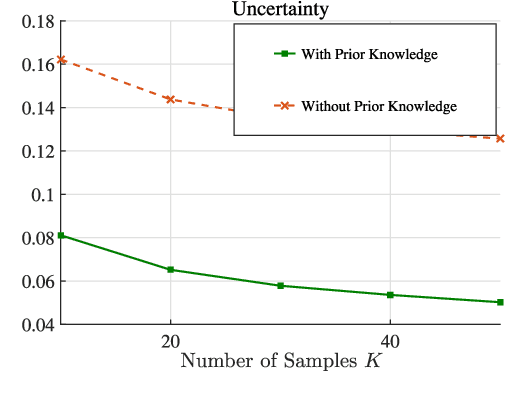
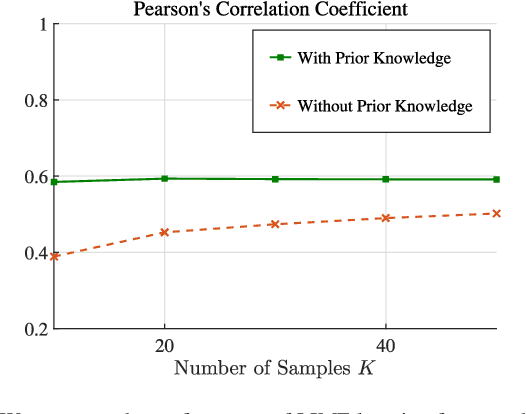
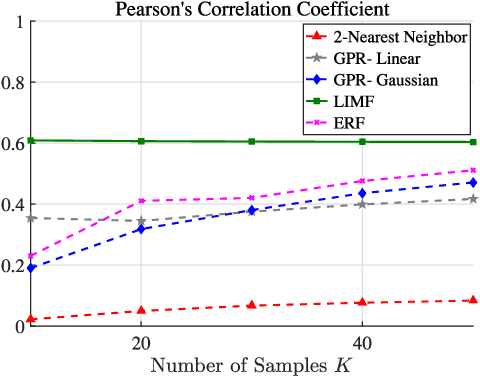
Learning of the cell-load in radio access networks (RANs) has to be performed within a short time period. Therefore, we propose a learning framework that is robust against uncertainties resulting from the need for learning based on a relatively small training sample set. To this end, we incorporate prior knowledge about the cell-load in the learning framework. For example, an inherent property of the cell-load is that it is monotonic in downlink (data) rates. To obtain additional prior knowledge we first study the feasible rate region, i.e., the set of all vectors of user rates that can be supported by the network. We prove that the feasible rate region is compact. Moreover, we show the existence of a Lipschitz function that maps feasible rate vectors to cell-load vectors. With these results in hand, we present a learning technique that guarantees a minimum approximation error in the worst-case scenario by using prior knowledge and a small training sample set. Simulations in the network simulator NS3 demonstrate that the proposed method exhibits better robustness and accuracy than standard multivariate learning techniques, especially for small training sample sets.
* Published in IEEE Transactions on Signal Processing ( Volume: 68)
Set-Theoretic Learning for Detection in Cell-Less C-RAN Systems
Mar 21, 2021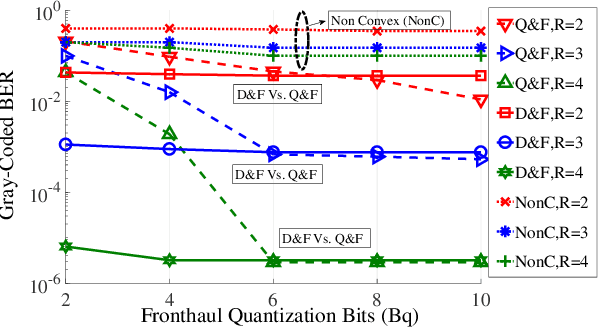
Cloud-radio access network (C-RAN) can enable cell-less operation by connecting distributed remote radio heads (RRHs) via fronthaul links to a powerful central unit. In conventional C-RAN, baseband signals are forwarded after quantization/ compression to the central unit for centralized processing to keep the complexity of the RRHs low. However, the limited capacity of the fronthaul is thought to be a significant bottleneck in the ability of C-RAN to support large systems (e.g. massive machine-type communications (mMTC)). Therefore, in contrast to the conventional C-RAN, we propose a learning-based system in which the detection is performed locally at each RRH and only the likelihood information is conveyed to the CU. To this end, we develop a general set-theoretic learningmethod to estimate likelihood functions. The method can be used to extend existing detection methods to the C-RAN setting.