 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMT vs NMT: A Comparison over Hindi & Bengali Simple Sentences
Dec 12, 2018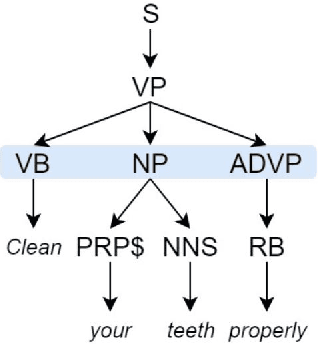
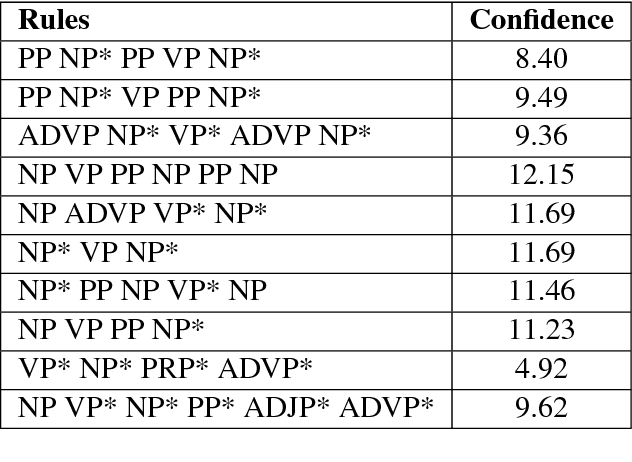
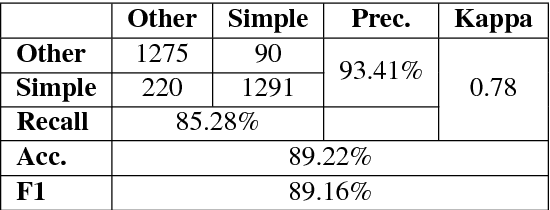
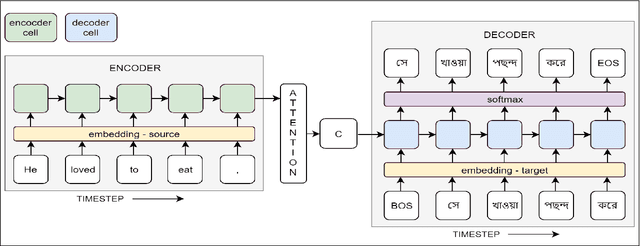
In the present article, we identified the qualitative differences between Statistical Machine Translation (SMT) and Neural Machine Translation (NMT) outputs. We have tried to answer two important questions: 1. Does NMT perform equivalently well with respect to SMT and 2. Does it add extra flavor in improving the quality of MT output by employing simple sentences as training units. In order to obtain insights, we have developed three core models viz., SMT model based on Moses toolkit, followed by character and word level NMT models. All of the systems use English-Hindi and English-Bengali language pairs containing simple sentences as well as sentences of other complexity. In order to preserve the translations semantics with respect to the target words of a sentence, we have employed soft-attention into our word level NMT model. We have further evaluated all the systems with respect to the scenarios where they succeed and fail. Finally, the quality of translation has been validated using BLEU and TER metrics along with manual parameters like fluency, adequacy etc. We observed that NMT outperforms SMT in case of simple sentences whereas SMT outperforms in case of all types of sentence.
Identifying Bengali Multiword Expressions using Semantic Clustering
Jan 23, 2014


One of the key issues in both natural language understanding and generation is the appropriate processing of Multiword Expressions (MWEs). MWEs pose a huge problem to the precise language processing due to their idiosyncratic nature and diversity in lexical, syntactical and semantic properties. The semantics of a MWE cannot be expressed after combining the semantics of its constituents. Therefore, the formalism of semantic clustering is often viewed as an instrument for extracting MWEs especially for resource constraint languages like Bengali. The present semantic clustering approach contributes to locate clusters of the synonymous noun tokens present in the document. These clusters in turn help measure the similarity between the constituent words of a potentially candidate phrase using a vector space model and judge the suitability of this phrase to be a MWE. In this experiment, we apply the semantic clustering approach for noun-noun bigram MWEs, though it can be extended to any types of MWEs. In parallel, the well known statistical models, namely Point-wise Mutual Information (PMI), Log Likelihood Ratio (LLR), Significance function are also employed to extract MWEs from the Bengali corpus. The comparative evaluation shows that the semantic clustering approach outperforms all other competing statistical models. As a by-product of this experiment, we have started developing a standard lexicon in Bengali that serves as a productive Bengali linguistic thesaurus.
Inference of Fine-grained Attributes of Bengali Corpus for Stylometry Detection
Oct 13, 2012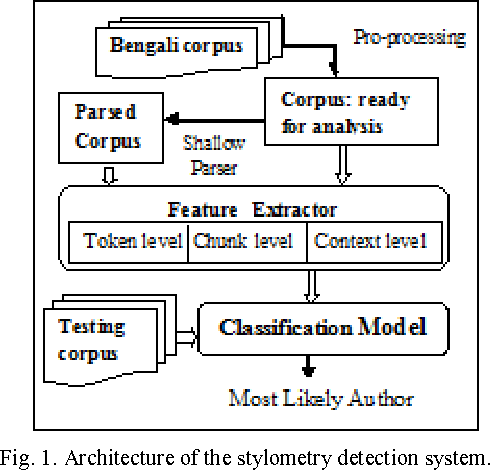
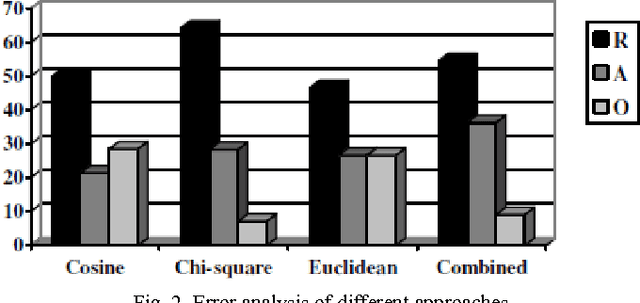
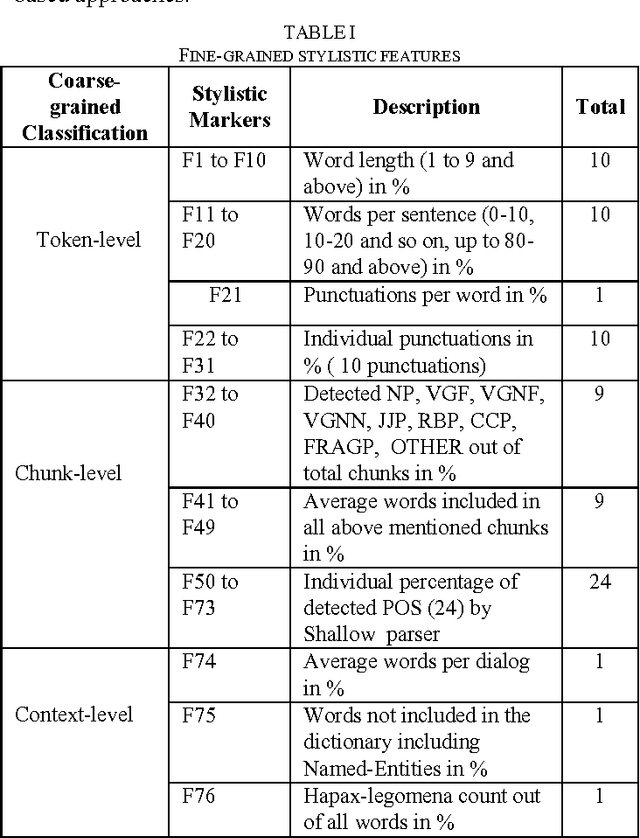
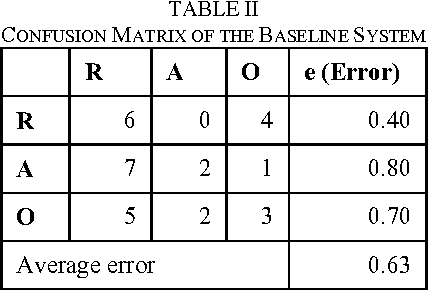
Stylometry, the science of inferring characteristics of the author from the characteristics of documents written by that author, is a problem with a long history and belongs to the core task of Text categorization that involves authorship identification, plagiarism detection, forensic investigation, computer security, copyright and estate disputes etc. In this work, we present a strategy for stylometry detection of documents written in Bengali. We adopt a set of fine-grained attribute features with a set of lexical markers for the analysis of the text and use three semi-supervised measures for making decisions. Finally, a majority voting approach has been taken for final classification. The system is fully automatic and language-independent. Evaluation results of our attempt for Bengali author's stylometry detection show reasonably promising accuracy in comparison to the baseline model.
* 5 pages, 2 figures, 4 tables. arXiv admin note: substantial text overlap with arXiv:1208.6268
Automatic Segmentation of Manipuri (Meiteilon) Word into Syllabic Units
Jul 17, 2012
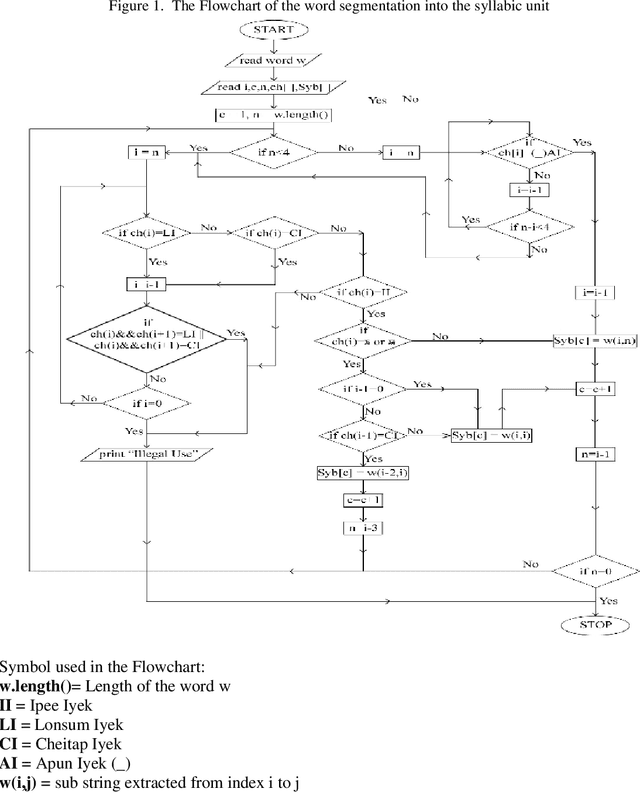


The work of automatic segmentation of a Manipuri language (or Meiteilon) word into syllabic units is demonstrated in this paper. This language is a scheduled Indian language of Tibeto-Burman origin, which is also a very highly agglutinative language. This language usages two script: a Bengali script and Meitei Mayek (Script). The present work is based on the second script. An algorithm is designed so as to identify mainly the syllables of Manipuri origin word. The result of the algorithm shows a Recall of 74.77, Precision of 91.21 and F-Score of 82.18 which is a reasonable score with the first attempt of such kind for this language.
Reduplicated MWE helps in improving the CRF based Manipuri POS Tagger
Mar 22, 2012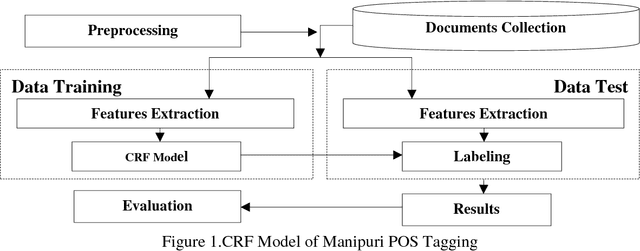

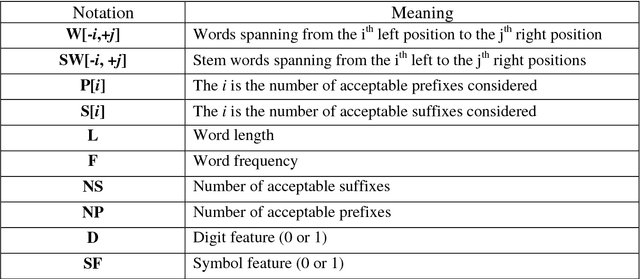
This paper gives a detail overview about the modified features selection in CRF (Conditional Random Field) based Manipuri POS (Part of Speech) tagging. Selection of features is so important in CRF that the better are the features then the better are the outputs. This work is an attempt or an experiment to make the previous work more efficient. Multiple new features are tried to run the CRF and again tried with the Reduplicated Multiword Expression (RMWE) as another feature. The CRF run with RMWE because Manipuri is rich of RMWE and identification of RMWE becomes one of the necessities to bring up the result of POS tagging. The new CRF system shows a Recall of 78.22%, Precision of 73.15% and F-measure of 75.60%. With the identification of RMWE and considering it as a feature makes an improvement to a Recall of 80.20%, Precision of 74.31% and F-measure of 77.14%.
Genetic Algorithm (GA) in Feature Selection for CRF Based Manipuri Multiword Expression (MWE) Identification
Nov 10, 2011
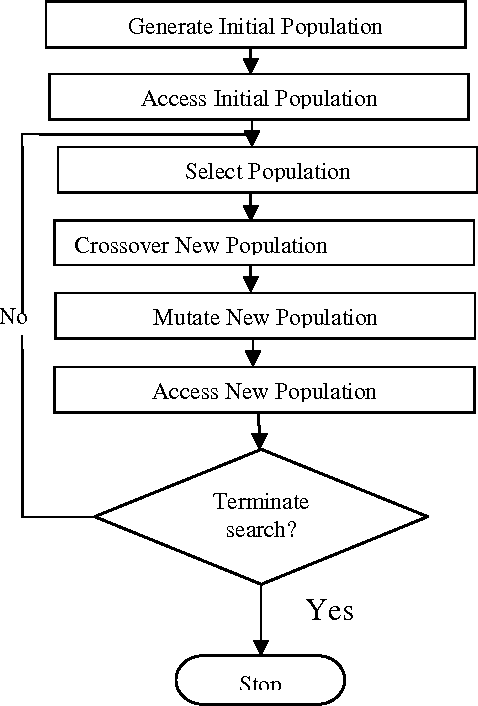
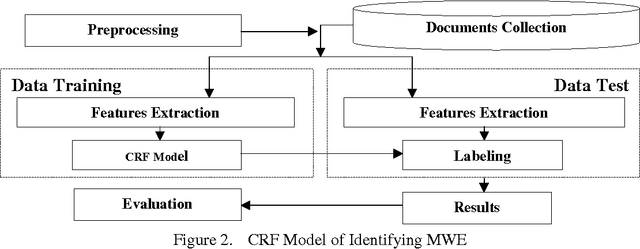
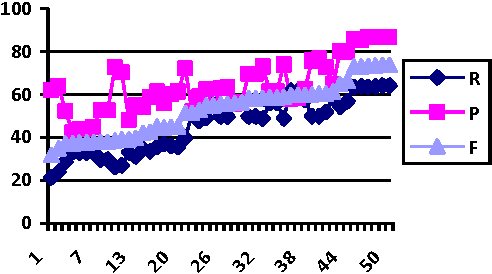
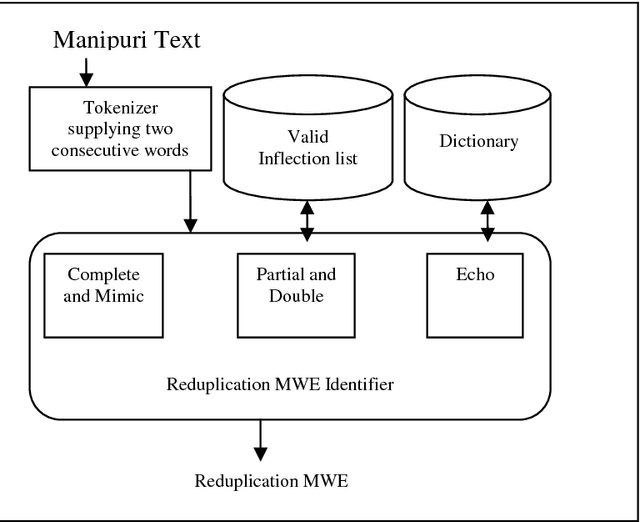
This paper deals with the identification of Multiword Expressions (MWEs) in Manipuri, a highly agglutinative Indian Language. Manipuri is listed in the Eight Schedule of Indian Constitution. MWE plays an important role in the applications of Natural Language Processing(NLP) like Machine Translation, Part of Speech tagging, Information Retrieval, Question Answering etc. Feature selection is an important factor in the recognition of Manipuri MWEs using Conditional Random Field (CRF). The disadvantage of manual selection and choosing of the appropriate features for running CRF motivates us to think of Genetic Algorithm (GA). Using GA we are able to find the optimal features to run the CRF. We have tried with fifty generations in feature selection along with three fold cross validation as fitness function. This model demonstrated the Recall (R) of 64.08%, Precision (P) of 86.84% and F-measure (F) of 73.74%, showing an improvement over the CRF based Manipuri MWE identification without GA application.
* 14 pages, 6 figures, see http://airccse.org/journal/jcsit/1011csit05.pdf