 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Segmentation of Manipuri (Meiteilon) Word into Syllabic Units
Jul 17, 2012
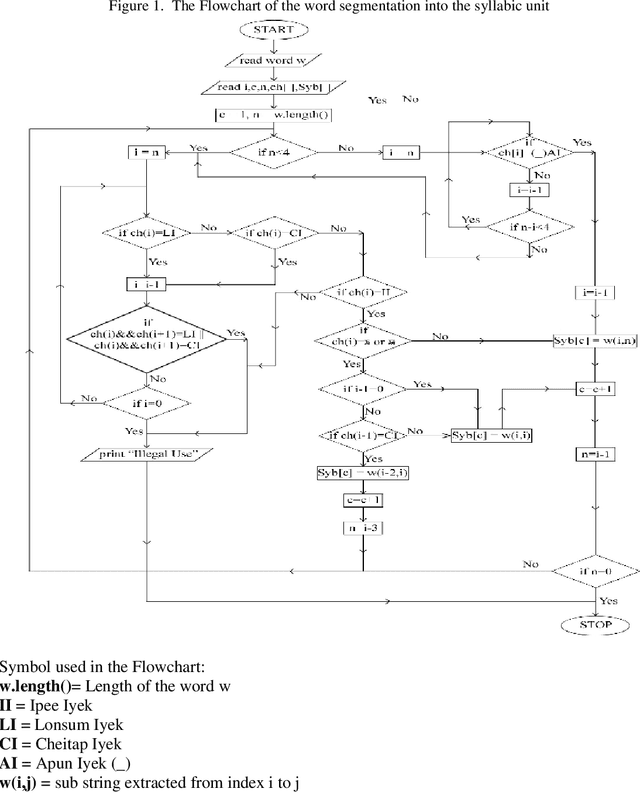


The work of automatic segmentation of a Manipuri language (or Meiteilon) word into syllabic units is demonstrated in this paper. This language is a scheduled Indian language of Tibeto-Burman origin, which is also a very highly agglutinative language. This language usages two script: a Bengali script and Meitei Mayek (Script). The present work is based on the second script. An algorithm is designed so as to identify mainly the syllables of Manipuri origin word. The result of the algorithm shows a Recall of 74.77, Precision of 91.21 and F-Score of 82.18 which is a reasonable score with the first attempt of such kind for this language.
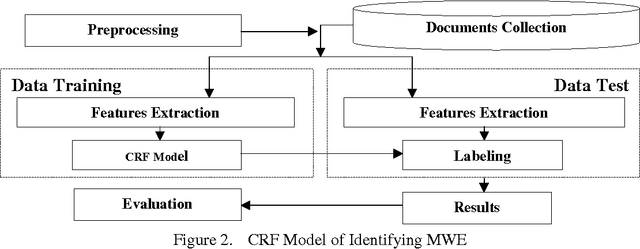
Reduplicated MWE helps in improving the CRF based Manipuri POS Tagger
Mar 22, 2012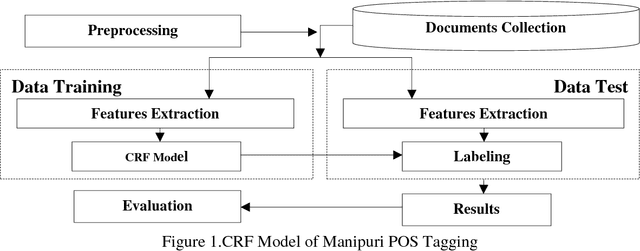

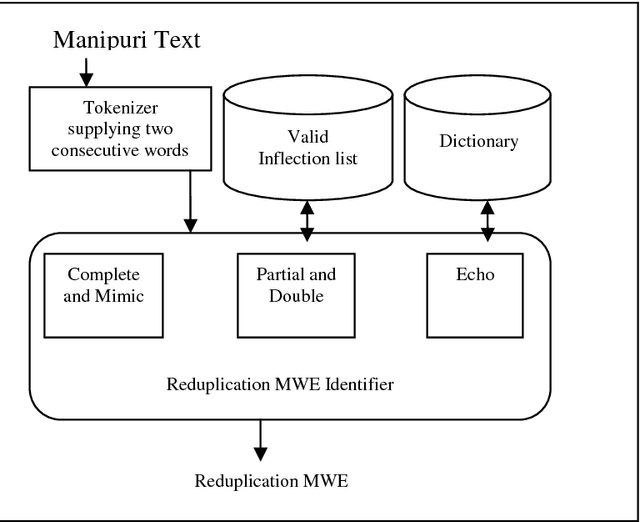
This paper gives a detail overview about the modified features selection in CRF (Conditional Random Field) based Manipuri POS (Part of Speech) tagging. Selection of features is so important in CRF that the better are the features then the better are the outputs. This work is an attempt or an experiment to make the previous work more efficient. Multiple new features are tried to run the CRF and again tried with the Reduplicated Multiword Expression (RMWE) as another feature. The CRF run with RMWE because Manipuri is rich of RMWE and identification of RMWE becomes one of the necessities to bring up the result of POS tagging. The new CRF system shows a Recall of 78.22%, Precision of 73.15% and F-measure of 75.60%. With the identification of RMWE and considering it as a feature makes an improvement to a Recall of 80.20%, Precision of 74.31% and F-measure of 77.14%.
Genetic Algorithm (GA) in Feature Selection for CRF Based Manipuri Multiword Expression (MWE) Identification
Nov 10, 2011
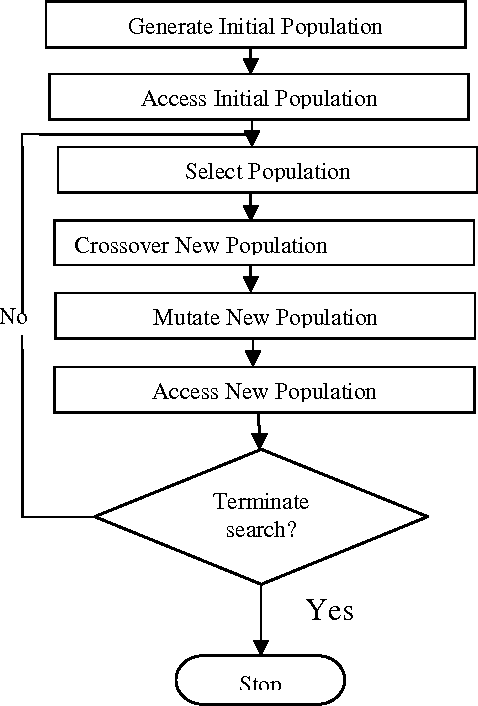
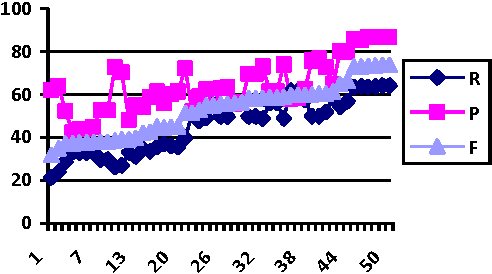
This paper deals with the identification of Multiword Expressions (MWEs) in Manipuri, a highly agglutinative Indian Language. Manipuri is listed in the Eight Schedule of Indian Constitution. MWE plays an important role in the applications of Natural Language Processing(NLP) like Machine Translation, Part of Speech tagging, Information Retrieval, Question Answering etc. Feature selection is an important factor in the recognition of Manipuri MWEs using Conditional Random Field (CRF). The disadvantage of manual selection and choosing of the appropriate features for running CRF motivates us to think of Genetic Algorithm (GA). Using GA we are able to find the optimal features to run the CRF. We have tried with fifty generations in feature selection along with three fold cross validation as fitness function. This model demonstrated the Recall (R) of 64.08%, Precision (P) of 86.84% and F-measure (F) of 73.74%, showing an improvement over the CRF based Manipuri MWE identification without GA application.
* 14 pages, 6 figures, see http://airccse.org/journal/jcsit/1011csit05.pdf