 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring model variability using robust non-parametric testing
Jun 12, 2024



Training a deep neural network often involves stochastic optimization, meaning each run will produce a different model. The seed used to initialize random elements of the optimization procedure heavily influences the quality of a trained model, which may be obscure from many commonly reported summary statistics, like accuracy. However, random seed is often not included in hyper-parameter optimization, perhaps because the relationship between seed and model quality is hard to describe. This work attempts to describe the relationship between deep net models trained with different random seeds and the behavior of the expected model. We adopt robust hypothesis testing to propose a novel summary statistic for network similarity, referred to as the $\alpha$-trimming level. We use the $\alpha$-trimming level to show that the empirical cumulative distribution function of an ensemble model created from a collection of trained models with different random seeds approximates the average of these functions as the number of models in the collection grows large. This insight provides guidance for how many random seeds should be sampled to ensure that an ensemble of these trained models is a reliable representative. We also show that the $\alpha$-trimming level is more expressive than different performance metrics like validation accuracy, churn, or expected calibration error when taken alone and may help with random seed selection in a more principled fashion. We demonstrate the value of the proposed statistic in real experiments and illustrate the advantage of fine-tuning over random seed with an experiment in transfer learning.
Robust Nonparametric Hypothesis Testing to Understand Variability in Training Neural Networks
Oct 01, 2023



Training a deep neural network (DNN) often involves stochastic optimization, which means each run will produce a different model. Several works suggest this variability is negligible when models have the same performance, which in the case of classification is test accuracy. However, models with similar test accuracy may not be computing the same function. We propose a new measure of closeness between classification models based on the output of the network before thresholding. Our measure is based on a robust hypothesis-testing framework and can be adapted to other quantities derived from trained models.
Robust Hierarchical-Optimization RLS Against Sparse Outliers
Oct 11, 2019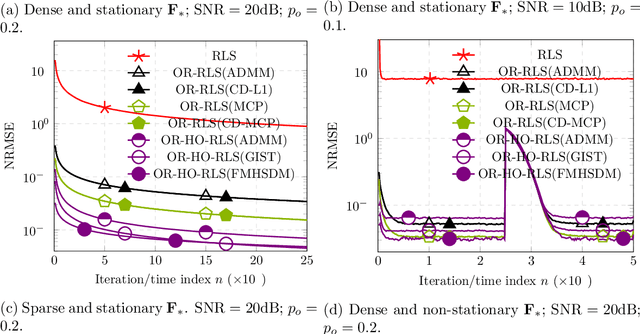
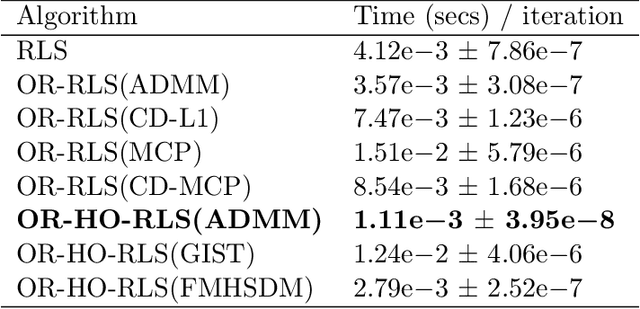
This paper fortifies the recently introduced hierarchical-optimization recursive least squares (HO-RLS) against outliers which contaminate infrequently linear-regression models. Outliers are modeled as nuisance variables and are estimated together with the linear filter/system variables via a sparsity-inducing (non-)convexly regularized least-squares task. The proposed outlier-robust HO-RLS builds on steepest-descent directions with a constant step size (learning rate), needs no matrix inversion (lemma), accommodates colored nominal noise of known correlation matrix, exhibits small computational footprint, and offers theoretical guarantees, in a probabilistic sense, for the convergence of the system estimates to the solutions of a hierarchical-optimization problem: Minimize a convex loss, which models a-priori knowledge about the unknown system, over the minimizers of the classical ensemble LS loss. Extensive numerical tests on synthetically generated data in both stationary and non-stationary scenarios showcase notable improvements of the proposed scheme over state-of-the-art techniques.