 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensely connected normalizing flows
Jun 08, 2021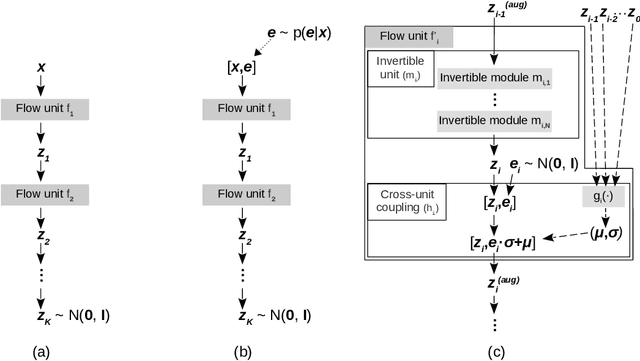
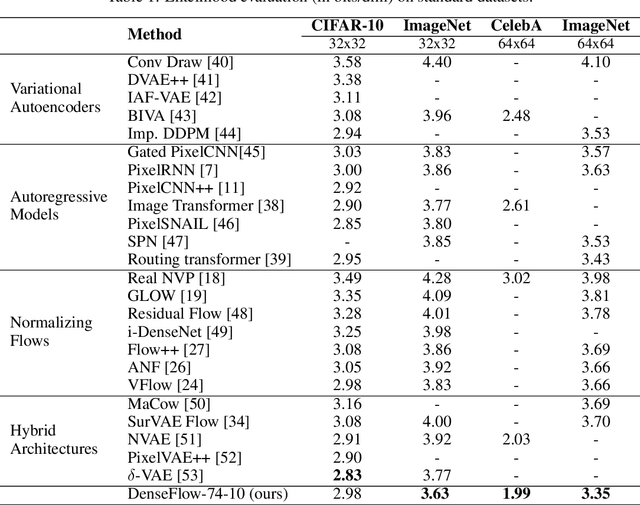
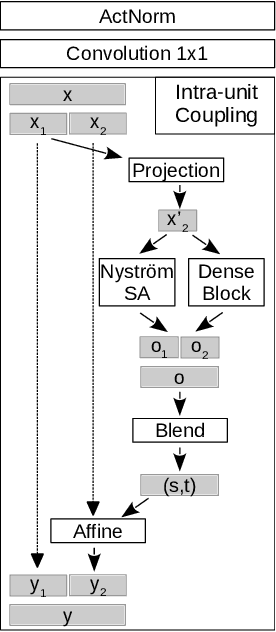
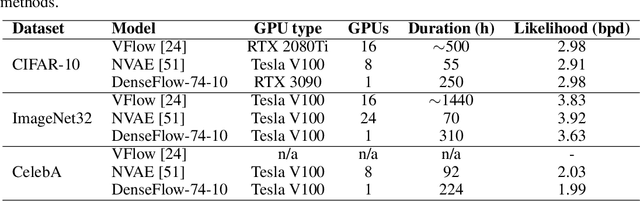
Normalizing flows are bijective mappings between inputs and latent representations with a fully factorized distribution. They are very attractive due to exact likelihood evaluation and efficient sampling. However, their effective capacity is often insufficient since the bijectivity constraint limits the model width. We address this issue by incrementally padding intermediate representations with noise. We precondition the noise in accordance with previous invertible units, which we describe as cross-unit coupling. Our invertible glow-like modules express intra-unit affine coupling as a fusion of a densely connected block and Nystr\"om self-attention. We refer to our architecture as DenseFlow since both cross-unit and intra-unit couplings rely on dense connectivity. Experiments show significant improvements due to the proposed contributions, and reveal state-of-the-art density estimation among all generative models under moderate computing budgets.
Joint Forecasting of Features and Feature Motion for Dense Semantic Future Prediction
Jan 26, 2021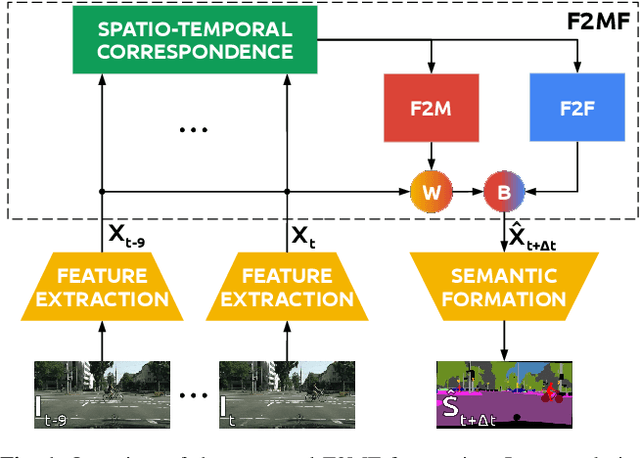
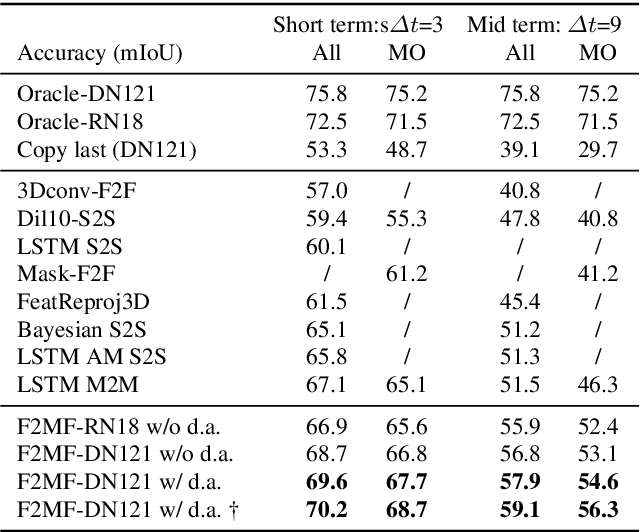
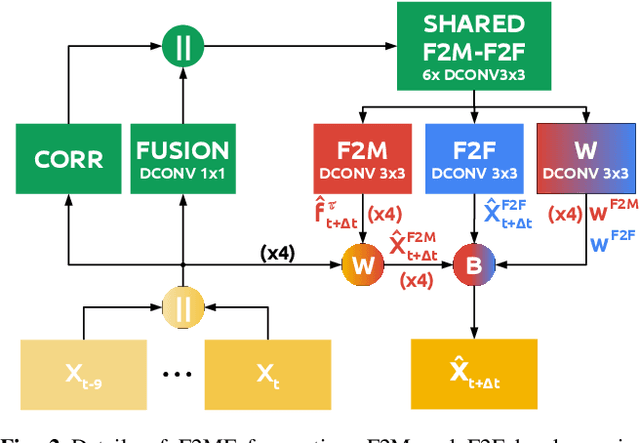
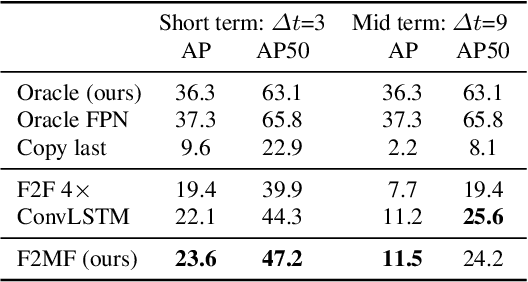
We present a novel dense semantic forecasting approach which is applicable to a variety of architectures and tasks. The approach consists of two modules. Feature-to-motion (F2M) module forecasts a dense deformation field which warps past features into their future positions. Feature-to-feature (F2F) module regresses the future features directly and is therefore able to account for emergent scenery. The compound F2MF approach decouples effects of motion from the effects of novelty in a task-agnostic manner. We aim to apply F2MF forecasting to the most subsampled and the most abstract representation of a desired single-frame model. Our implementations take advantage of deformable convolutions and pairwise correlation coefficients across neighbouring time instants. We perform experiments on three dense prediction tasks: semantic segmentation, instance-level segmentation, and panoptic segmentation. The results reveal state-of-the-art forecasting accuracy across all three modalities on the Cityscapes dataset.
Dense outlier detection and open-set recognition based on training with noisy negative images
Jan 22, 2021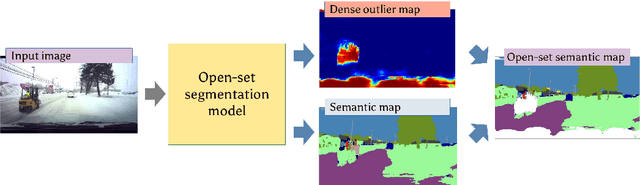
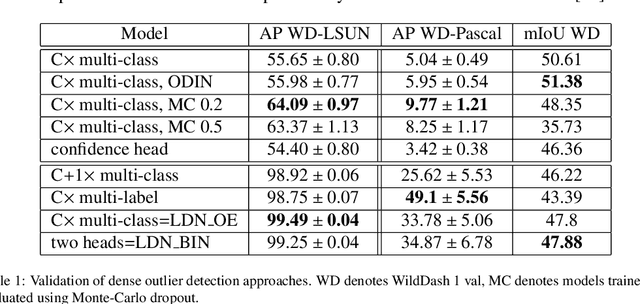
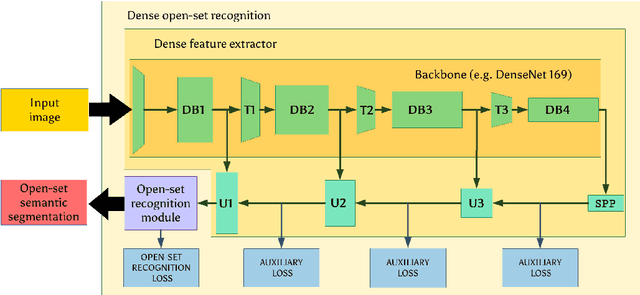
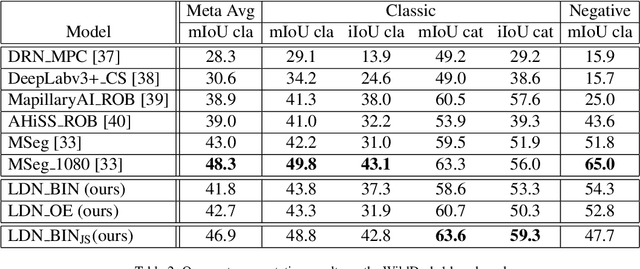
Deep convolutional models often produce inadequate predictions for inputs foreign to the training distribution. Consequently, the problem of detecting outlier images has recently been receiving a lot of attention. Unlike most previous work, we address this problem in the dense prediction context in order to be able to locate outlier objects in front of in-distribution background. Our approach is based on two reasonable assumptions. First, we assume that the inlier dataset is related to some narrow application field (e.g.~road driving). Second, we assume that there exists a general-purpose dataset which is much more diverse than the inlier dataset (e.g.~ImageNet-1k). We consider pixels from the general-purpose dataset as noisy negative training samples since most (but not all) of them are outliers. We encourage the model to recognize borders between known and unknown by pasting jittered negative patches over inlier training images. Our experiments target two dense open-set recognition benchmarks (WildDash 1 and Fishyscapes) and one dense open-set recognition dataset (StreetHazard). Extensive performance evaluation indicates competitive potential of the proposed approach.
Dense open-set recognition with synthetic outliers generated by Real NVP
Nov 22, 2020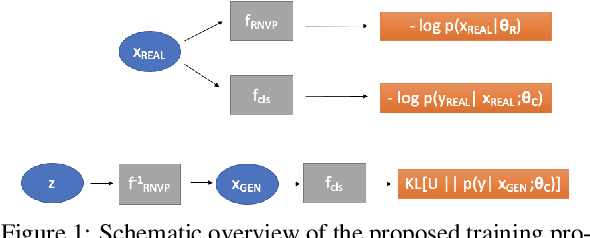

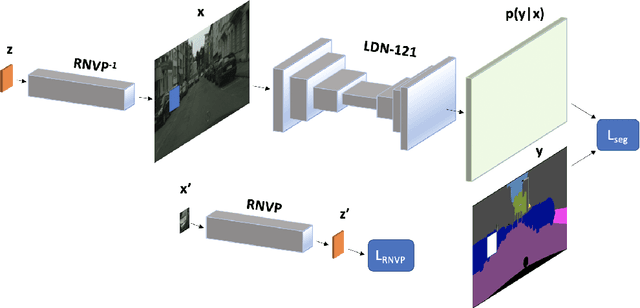
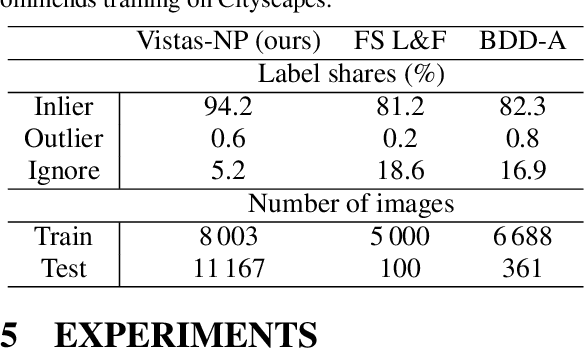
Today's deep models are often unable to detect inputs which do not belong to the training distribution. This gives rise to confident incorrect predictions which could lead to devastating consequences in many important application fields such as healthcare and autonomous driving. Interestingly, both discriminative and generative models appear to be equally affected. Consequently, this vulnerability represents an important research challenge. We consider an outlier detection approach based on discriminative training with jointly learned synthetic outliers. We obtain the synthetic outliers by sampling an RNVP model which is jointly trained to generate datapoints at the border of the training distribution. We show that this approach can be adapted for simultaneous semantic segmentation and dense outlier detection. We present image classification experiments on CIFAR-10, as well as semantic segmentation experiments on three existing datasets (StreetHazards, WD-Pascal, Fishyscapes Lost & Found), and one contributed dataset. Our models perform competitively with respect to the state of the art despite producing predictions with only one forward pass.
Multimodal semantic forecasting based on conditional generation of future features
Oct 18, 2020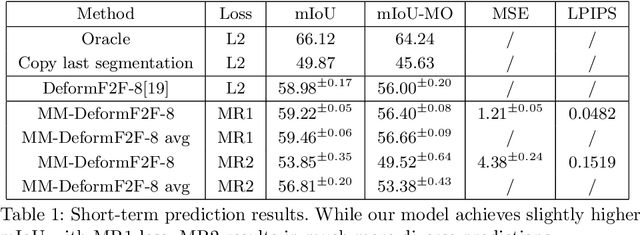

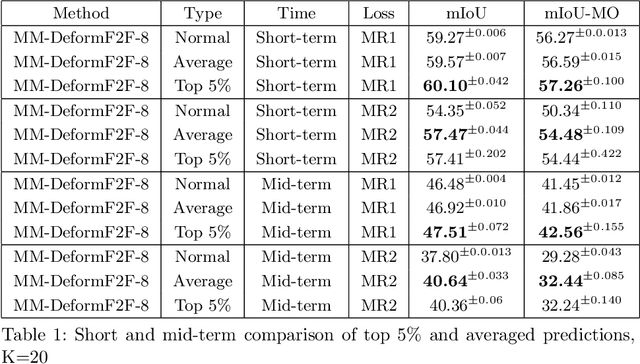
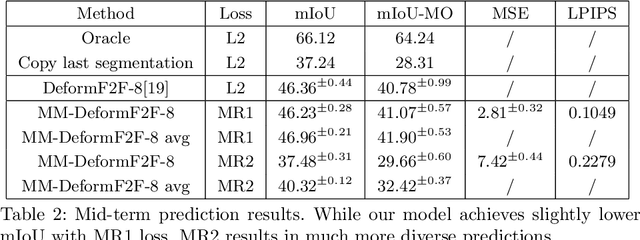
This paper considers semantic forecasting in road-driving scenes. Most existing approaches address this problem as deterministic regression of future features or future predictions given observed frames. However, such approaches ignore the fact that future can not always be guessed with certainty. For example, when a car is about to turn around a corner, the road which is currently occluded by buildings may turn out to be either free to drive, or occupied by people, other vehicles or roadworks. When a deterministic model confronts such situation, its best guess is to forecast the most likely outcome. However, this is not acceptable since it defeats the purpose of forecasting to improve security. It also throws away valuable training data, since a deterministic model is unable to learn any deviation from the norm. We address this problem by providing more freedom to the model through allowing it to forecast different futures. We propose to formulate multimodal forecasting as sampling of a multimodal generative model conditioned on the observed frames. Experiments on the Cityscapes dataset reveal that our multimodal model outperforms its deterministic counterpart in short-term forecasting while performing slightly worse in the mid-term case.
Multi-domain semantic segmentation with pyramidal fusion
Sep 16, 2020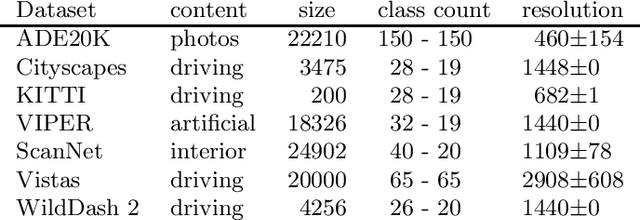
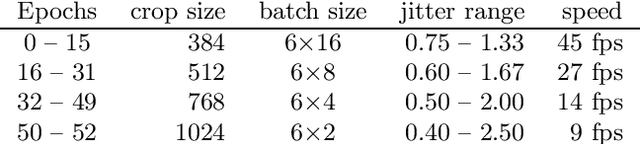

We present our submission to the semantic segmentation contest of the Robust Vision Challenge held at ECCV 2020. The contest requires submitting the same model to seven benchmarks from three different domains. Our approach is based on the SwiftNet architecture with pyramidal fusion. We address inconsistent taxonomies with a single-level 193-dimensional softmax output. We strive to train with large batches in order to stabilize optimization of a hard recognition problem, and to favour smooth evolution of batchnorm statistics. We achieve this by implementing a custom backward step through log-sum-prob loss, and by using small crops before freezing the population statistics. Our model ranks first on the RVC semantic segmentation challenge as well as on the WildDash 2 leaderboard. This suggests that pyramidal fusion is competitive not only for efficient inference with lightweight backbones, but also in large-scale setups for multi-domain application.
Simultaneous Semantic Segmentation and Outlier Detection in Presence of Domain Shift
Aug 03, 2019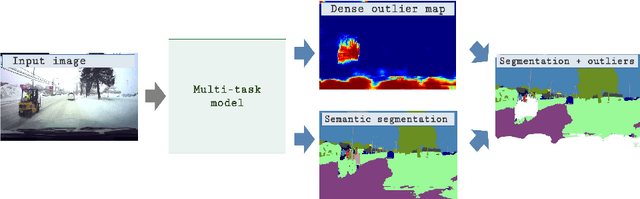
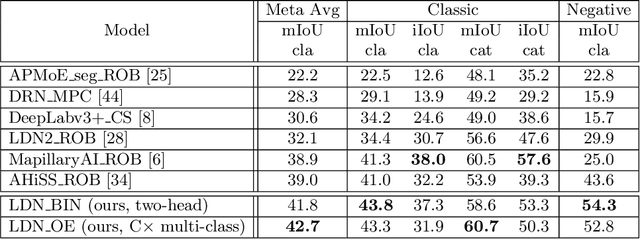
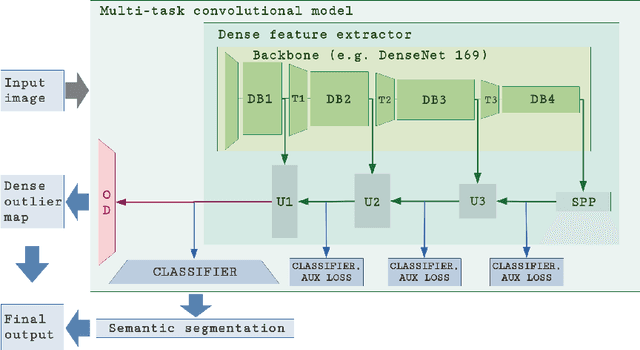
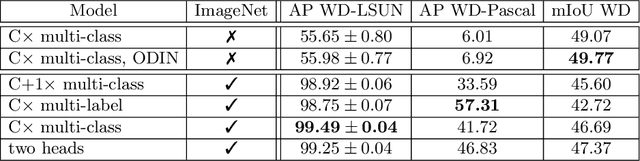
Recent success on realistic road driving datasets has increased interest in exploring robust performance in real-world applications. One of the major unsolved problems is to identify image content which can not be reliably recognized with a given inference engine. We therefore study approaches to recover a dense outlier map alongside the primary task with a single forward pass, by relying on shared convolutional features. We consider semantic segmentation as the primary task and perform extensive validation on WildDash val (inliers), LSUN val (outliers), and pasted objects from Pascal VOC 2007 (outliers). We achieve the best validation performance by training to discriminate inliers from pasted ImageNet-1k content, even though ImageNet-1k contains many road-driving pixels, and, at least nominally, fails to account for the full diversity of the visual world. The proposed two-head model performs comparably to the C-way multi-class model trained to predict uniform distribution in outliers, while outperforming several other validated approaches. We evaluate our best two models on the WildDash test dataset and set a new state of the art on the WildDash benchmark.
Single Level Feature-to-Feature Forecasting with Deformable Convolutions
Jul 26, 2019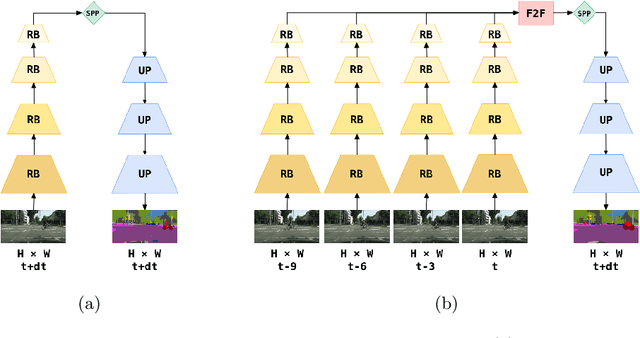
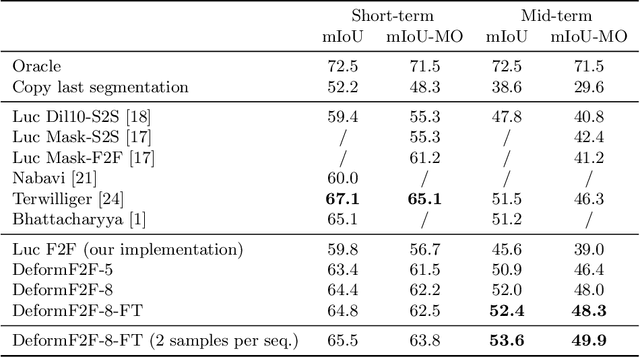

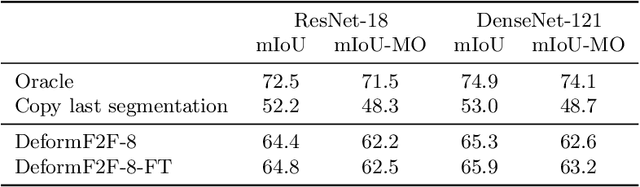
Future anticipation is of vital importance in autonomous driving and other decision-making systems. We present a method to anticipate semantic segmentation of future frames in driving scenarios based on feature-to-feature forecasting. Our method is based on a semantic segmentation model without lateral connections within the upsampling path. Such design ensures that the forecasting addresses only the most abstract features on a very coarse resolution. We further propose to express feature-to-feature forecasting with deformable convolutions. This increases the modelling power due to being able to represent different motion patterns within a single feature map. Experiments show that our models with deformable convolutions outperform their regular and dilated counterparts while minimally increasing the number of parameters. Our method achieves state of the art performance on the Cityscapes validation set when forecasting nine timesteps into the future.
Pedestrian Tracking by Probabilistic Data Association and Correspondence Embeddings
Jul 16, 2019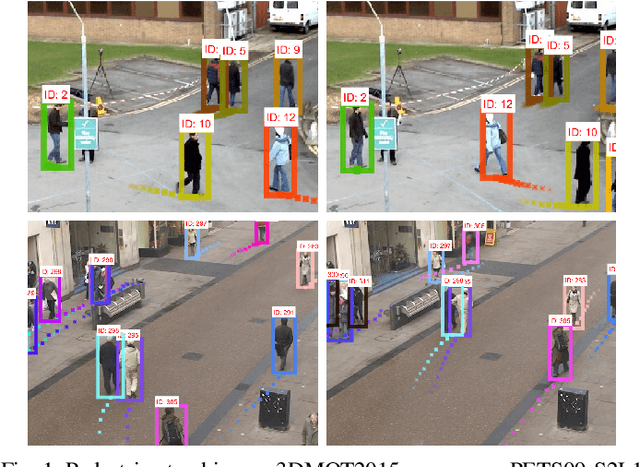
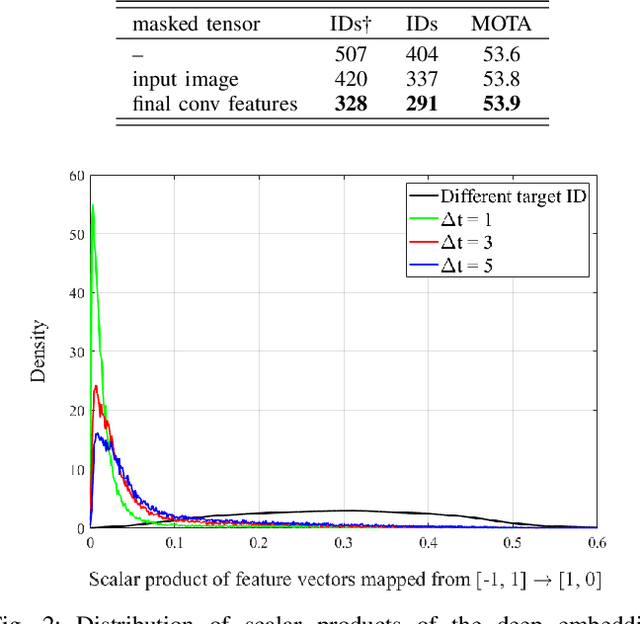

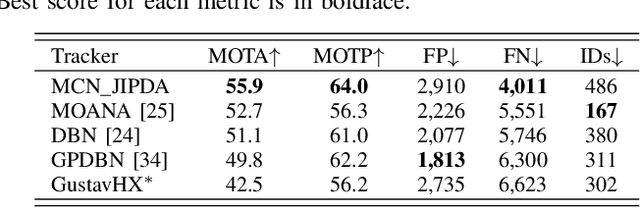
This paper studies the interplay between kinematics (position and velocity) and appearance cues for establishing correspondences in multi-target pedestrian tracking. We investigate tracking-by-detection approaches based on a deep learning detector, joint integrated probabilistic data association (JIPDA), and appearance-based tracking of deep correspondence embeddings. We first addressed the fixed-camera setup by fine-tuning a convolutional detector for accurate pedestrian detection and combining it with kinematic-only JIPDA. The resulting submission ranked first on the 3DMOT2015 benchmark. However, in sequences with a moving camera and unknown ego-motion, we achieved the best results by replacing kinematic cues with global nearest neighbor tracking of deep correspondence embeddings. We trained the embeddings by fine-tuning features from the second block of ResNet-18 using angular loss extended by a margin term. We note that integrating deep correspondence embeddings directly in JIPDA did not bring significant improvement. It appears that geometry of deep correspondence embeddings for soft data association needs further investigation in order to obtain the best from both worlds.
Efficient Ladder-style DenseNets for Semantic Segmentation of Large Images
May 14, 2019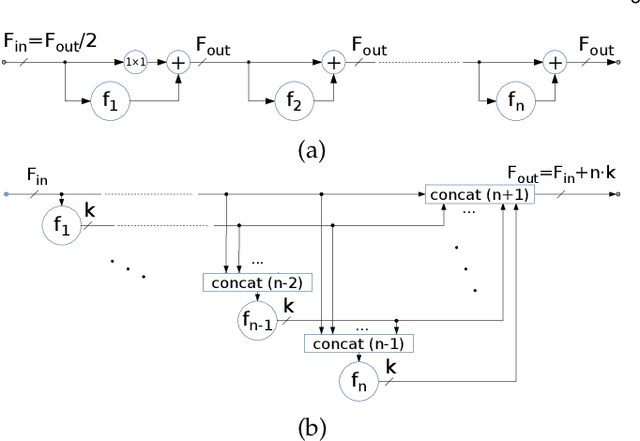
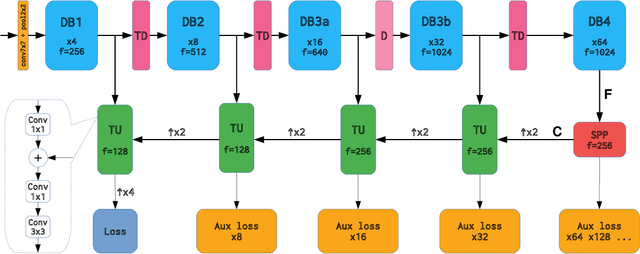
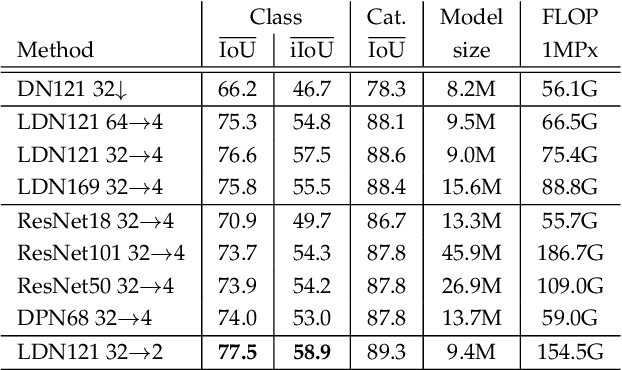
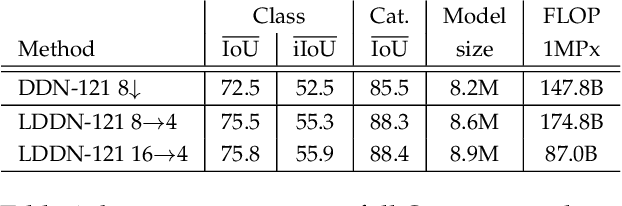
Recent progress of deep image classification models has provided great potential to improve state-of-the-art performance in related computer vision tasks. However, the transition to semantic segmentation is hampered by strict memory limitations of contemporary GPUs. The extent of feature map caching required by convolutional backprop poses significant challenges even for moderately sized Pascal images, while requiring careful architectural considerations when the source resolution is in the megapixel range. To address these concerns, we propose a novel DenseNet-based ladder-style architecture which features high modelling power and a very lean upsampling datapath. We also propose to substantially reduce the extent of feature map caching by exploiting inherent spatial efficiency of the DenseNet feature extractor. The resulting models deliver high performance with fewer parameters than competitive approaches, and allow training at megapixel resolution on commodity hardware. The presented experimental results outperform the state-of-the-art in terms of prediction accuracy and execution speed on Cityscapes, Pascal VOC 2012, CamVid and ROB 2018 datasets. Source code will be released upon publication.