 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance weighted generative networks
Jun 07, 2018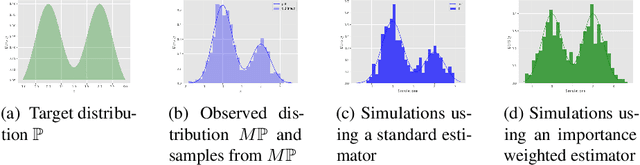

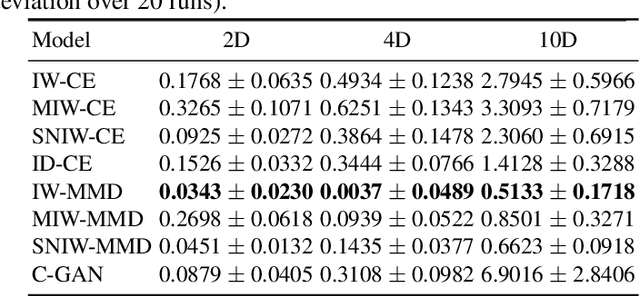
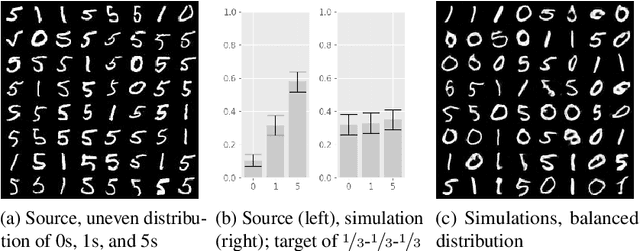
Deep generative networks can simulate from a complex target distribution, by minimizing a loss with respect to samples from that distribution. However, often we do not have direct access to our target distribution - our data may be subject to sample selection bias, or may be from a different but related distribution. We present methods based on importance weighting that can estimate the loss with respect to a target distribution, even if we cannot access that distribution directly, in a variety of settings. These estimators, which differentially weight the contribution of data to the loss function, offer both theoretical guarantees and impressive empirical performance.
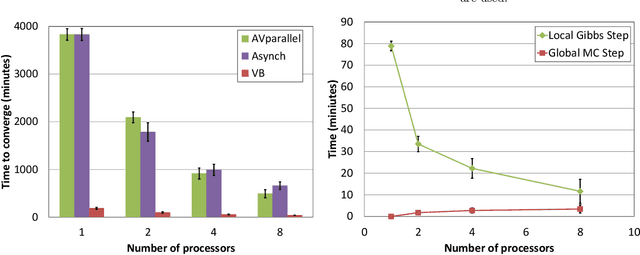
Parallel Markov Chain Monte Carlo for the Indian Buffet Process
Mar 09, 2017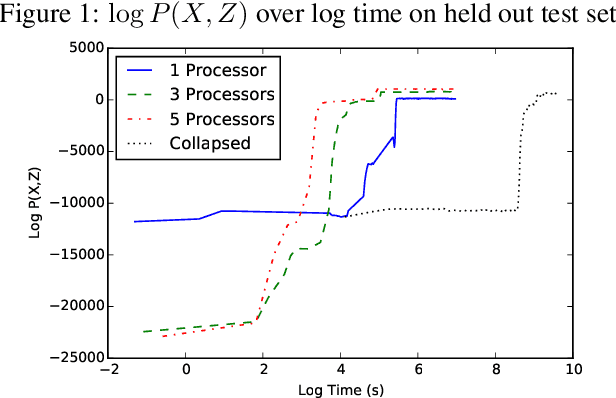

Indian Buffet Process based models are an elegant way for discovering underlying features within a data set, but inference in such models can be slow. Inferring underlying features using Markov chain Monte Carlo either relies on an uncollapsed representation, which leads to poor mixing, or on a collapsed representation, which leads to a quadratic increase in computational complexity. Existing attempts at distributing inference have introduced additional approximation within the inference procedure. In this paper we present a novel algorithm to perform asymptotically exact parallel Markov chain Monte Carlo inference for Indian Buffet Process models. We take advantage of the fact that the features are conditionally independent under the beta-Bernoulli process. Because of this conditional independence, we can partition the features into two parts: one part containing only the finitely many instantiated features and the other part containing the infinite tail of uninstantiated features. For the finite partition, parallel inference is simple given the instantiation of features. But for the infinite tail, performing uncollapsed MCMC leads to poor mixing and hence we collapse out the features. The resulting hybrid sampler, while being parallel, produces samples asymptotically from the true posterior.
Exact and Efficient Parallel Inference for Nonparametric Mixture Models
Nov 29, 2012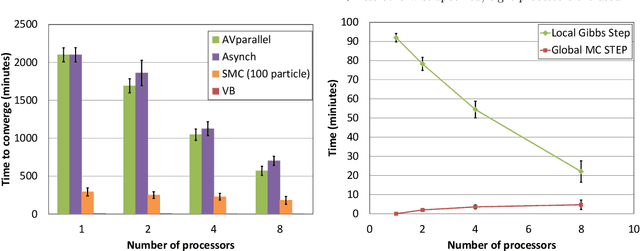
Nonparametric mixture models based on the Dirichlet process are an elegant alternative to finite models when the number of underlying components is unknown, but inference in such models can be slow. Existing attempts to parallelize inference in such models have relied on introducing approximations, which can lead to inaccuracies in the posterior estimate. In this paper, we describe auxiliary variable representations for the Dirichlet process and the hierarchical Dirichlet process that allow us to sample from the true posterior in a distributed manner. We show that our approach allows scalable inference without the deterioration in estimate quality that accompanies existing methods.