 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepForestVisionV2: Ecology-Driven Taxonomy Expansion for Camera-Trap Monitoring in African Tropical Forests
Jun 18, 2026Camera-trap monitoring in African tropical forests increasingly extends beyond closed-canopy interiors to riverbanks, clearings, and park edges. Among available open tools for African forest camera-trap classification, DeepForestVision is the only one providing a matched offline workflow for both photographs and videos, and previous work showed that it outperformed other available baselines on a comparable benchmark. However, it was designed for closed-canopy, ground-level forest interiors and uses a 35-class prediction space that becomes too coarse when deployments encounter arboreal primates, birds, semi-aquatic taxa, or human-associated confounders such as livestock. We present DeepForestVisionV2, an ecology-driven expansion from 35 to 64 prediction classes (61 animal classes plus human, vehicle, and blank) designed to address three recurrent deployment gradients: vertical stratification, scene openness, and anthropogenic interfaces. DeepForestVisionV2 retains the same offline workflow and is trained on 1,535,010 photographs and 243,354 videos from multi-country African tropical-forest projects. Evaluation combines a cross-country cropped-photo validation set, used to assess robustness across sites and camera-trap settings, with three held-out Uganda video benchmarks spanning the targeted gradients. On the validation set, DeepForestVisionV2 reaches 0.86 accuracy, 0.82 macro-F1, and 0.81 balanced accuracy. On the deployment benchmarks, it preserves or improves baseline accuracy despite its harder classification task, while increasing the number of identified taxa from 22 to 29 in forest-interior videos and from 4 to 9 at riverbanks. In the park-edge use case, it raises accuracy from 0.62 to 0.86 and reduces false alarms from 11 to 0. These results show that DeepForestVisionV2 materially improves field utility while preserving robustness across sites, habitats, and camera-trap settings.
Learning Disentangled Audio Representations through Controlled Synthesis
Feb 16, 2024


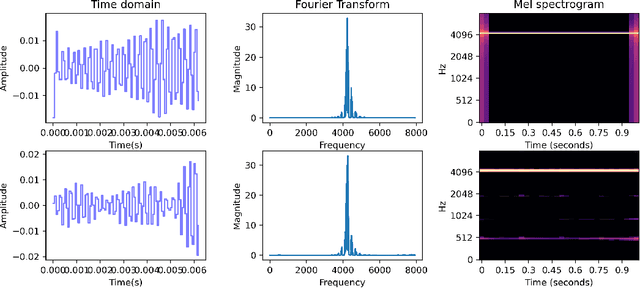
This paper tackles the scarcity of benchmarking data in disentangled auditory representation learning. We introduce SynTone, a synthetic dataset with explicit ground truth explanatory factors for evaluating disentanglement techniques. Benchmarking state-of-the-art methods on SynTone highlights its utility for method evaluation. Our results underscore strengths and limitations in audio disentanglement, motivating future research.
Learning Disentangled Speech Representations
Nov 04, 2023
Disentangled representation learning from speech remains limited despite its importance in many application domains. A key challenge is the lack of speech datasets with known generative factors to evaluate methods. This paper proposes SynSpeech: a novel synthetic speech dataset with ground truth factors enabling research on disentangling speech representations. We plan to present a comprehensive study evaluating supervised techniques using established supervised disentanglement metrics. This benchmark dataset and framework address the gap in the rigorous evaluation of state-of-the-art disentangled speech representation learning methods. Our findings will provide insights to advance this underexplored area and enable more robust speech representations.
Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction
Sep 07, 2023



The choice of the objective function is crucial in emerging high-quality representations from self-supervised learning. This paper investigates how different formulations of the Barlow Twins (BT) objective impact downstream task performance for speech data. We propose Modified Barlow Twins (MBT) with normalized latents to enforce scale-invariance and evaluate on speaker identification, gender recognition and keyword spotting tasks. Our results show MBT improves representation generalization over original BT, especially when fine-tuning with limited target data. This highlights the importance of designing objectives that encourage invariant and transferable representations. Our analysis provides insights into how the BT learning objective can be tailored to produce speech representations that excel when adapted to new downstream tasks. This study is an important step towards developing reusable self-supervised speech representations.