 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFramework of Thoughts: A Foundation Framework for Dynamic and Optimized Reasoning based on Chains, Trees, and Graphs
Feb 18, 2026Prompting schemes such as Chain of Thought, Tree of Thoughts, and Graph of Thoughts can significantly enhance the reasoning capabilities of large language models. However, most existing schemes require users to define static, problem-specific reasoning structures that lack adaptability to dynamic or unseen problem types. Additionally, these schemes are often under-optimized in terms of hyperparameters, prompts, runtime, and prompting cost. To address these limitations, we introduce Framework of Thoughts (FoT)--a general-purpose foundation framework for building and optimizing dynamic reasoning schemes. FoT comes with built-in features for hyperparameter tuning, prompt optimization, parallel execution, and intelligent caching, unlocking the latent performance potential of reasoning schemes. We demonstrate FoT's capabilities by implementing three popular schemes--Tree of Thoughts, Graph of Thoughts, and ProbTree--within FoT. We empirically show that FoT enables significantly faster execution, reduces costs, and achieves better task scores through optimization. We release our codebase to facilitate the development of future dynamic and efficient reasoning schemes.
From Roots to Rewards: Dynamic Tree Reasoning with RL
Jul 18, 2025Modern language models address complex questions through chain-of-thought (CoT) reasoning (Wei et al., 2023) and retrieval augmentation (Lewis et al., 2021), yet struggle with error propagation and knowledge integration. Tree-structured reasoning methods, particularly the Probabilistic Tree-of-Thought (ProbTree)(Cao et al., 2023) framework, mitigate these issues by decomposing questions into hierarchical structures and selecting answers through confidence-weighted aggregation of parametric and retrieved knowledge (Yao et al., 2023). However, ProbTree's static implementation introduces two key limitations: (1) the reasoning tree is fixed during the initial construction phase, preventing dynamic adaptation to intermediate results, and (2) each node requires exhaustive evaluation of all possible solution strategies, creating computational inefficiency. We present a dynamic reinforcement learning (Sutton and Barto, 2018) framework that transforms tree-based reasoning into an adaptive process. Our approach incrementally constructs the reasoning tree based on real-time confidence estimates, while learning optimal policies for action selection (decomposition, retrieval, or aggregation). This maintains ProbTree's probabilistic rigor while improving both solution quality and computational efficiency through selective expansion and focused resource allocation. The work establishes a new paradigm for treestructured reasoning that balances the reliability of probabilistic frameworks with the flexibility required for real-world question answering systems.
A Comprehensive Evaluation of Cognitive Biases in LLMs
Oct 20, 2024



We present a large-scale evaluation of 30 cognitive biases in 20 state-of-the-art large language models (LLMs) under various decision-making scenarios. Our contributions include a novel general-purpose test framework for reliable and large-scale generation of tests for LLMs, a benchmark dataset with 30,000 tests for detecting cognitive biases in LLMs, and a comprehensive assessment of the biases found in the 20 evaluated LLMs. Our work confirms and broadens previous findings suggesting the presence of cognitive biases in LLMs by reporting evidence of all 30 tested biases in at least some of the 20 LLMs. We publish our framework code to encourage future research on biases in LLMs: https://github.com/simonmalberg/cognitive-biases-in-llms
Multi-Stage Reinforcement Learning For Object Detection
Oct 26, 2018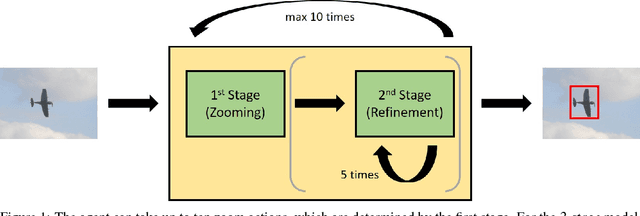
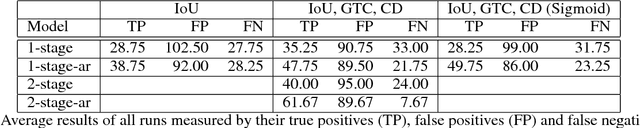
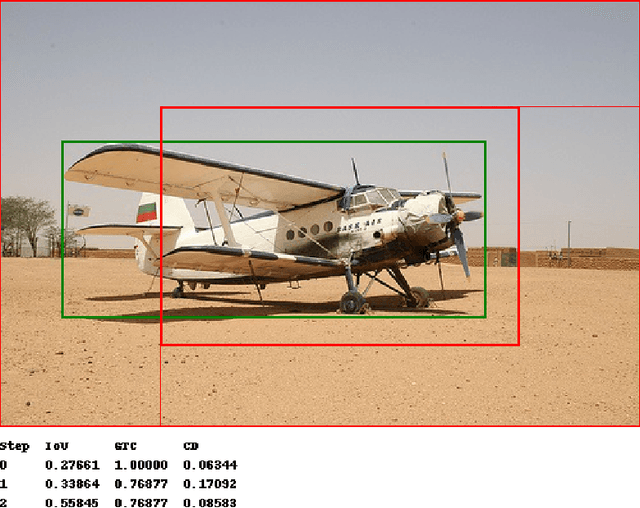
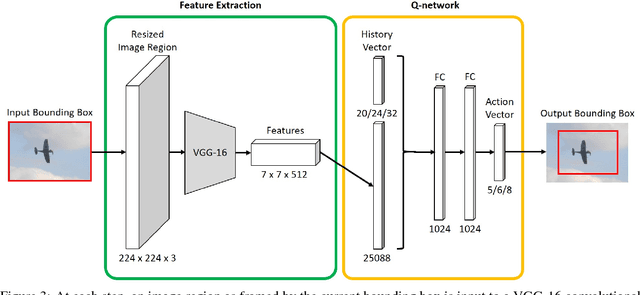
We present a reinforcement learning approach for detecting objects within an image. Our approach performs a step-wise deformation of a bounding box with the goal of tightly framing the object. It uses a hierarchical tree-like representation of predefined region candidates, which the agent can zoom in on. This reduces the number of region candidates that must be evaluated so that the agent can afford to compute new feature maps before each step to enhance detection quality. We compare an approach that is based purely on zoom actions with one that is extended by a second refinement stage to fine-tune the bounding box after each zoom step. We also improve the fitting ability by allowing for different aspect ratios of the bounding box. Finally, we propose different reward functions to lead to a better guidance of the agent while following its search trajectories. Experiments indicate that each of these extensions leads to more correct detections. The best performing approach comprises a zoom stage and a refinement stage, uses aspect-ratio modifying actions and is trained using a combination of three different reward metrics.