 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Principal Component Pursuit in Linear Time via $l_1$ Filtering
May 06, 2012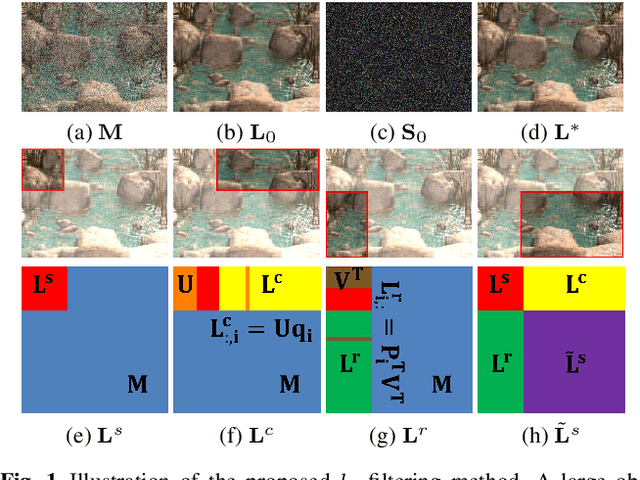
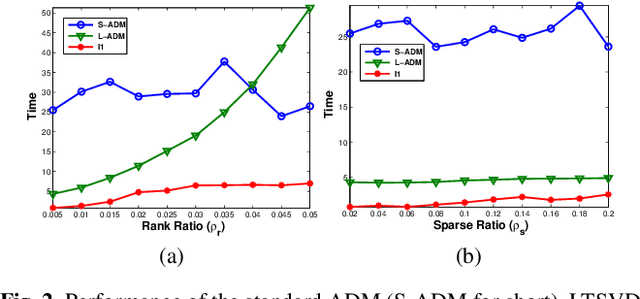
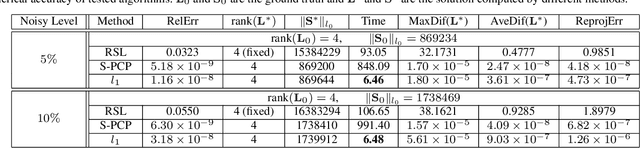
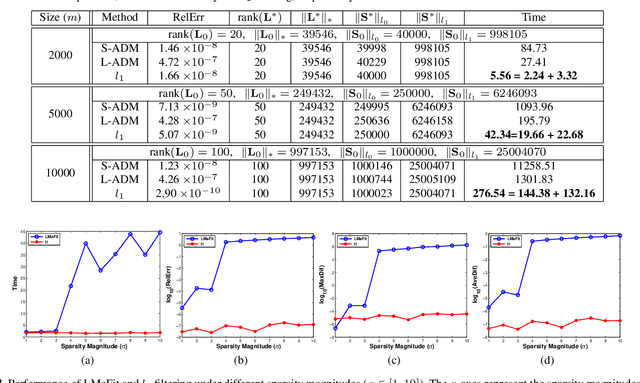
In the past decades, exactly recovering the intrinsic data structure from corrupted observations, which is known as robust principal component analysis (RPCA), has attracted tremendous interests and found many applications in computer vision. Recently, this problem has been formulated as recovering a low-rank component and a sparse component from the observed data matrix. It is proved that under some suitable conditions, this problem can be exactly solved by principal component pursuit (PCP), i.e., minimizing a combination of nuclear norm and $l_1$ norm. Most of the existing methods for solving PCP require singular value decompositions (SVD) of the data matrix, resulting in a high computational complexity, hence preventing the applications of RPCA to very large scale computer vision problems. In this paper, we propose a novel algorithm, called $l_1$ filtering, for \emph{exactly} solving PCP with an $O(r^2(m+n))$ complexity, where $m\times n$ is the size of data matrix and $r$ is the rank of the matrix to recover, which is supposed to be much smaller than $m$ and $n$. Moreover, $l_1$ filtering is \emph{highly parallelizable}. It is the first algorithm that can \emph{exactly} solve a nuclear norm minimization problem in \emph{linear time} (with respect to the data size). Experiments on both synthetic data and real applications testify to the great advantage of $l_1$ filtering in speed over state-of-the-art algorithms.
A Block Lanczos with Warm Start Technique for Accelerating Nuclear Norm Minimization Algorithms
Dec 26, 2010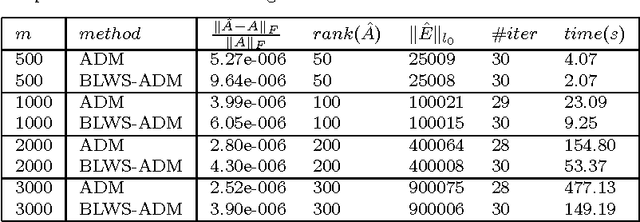
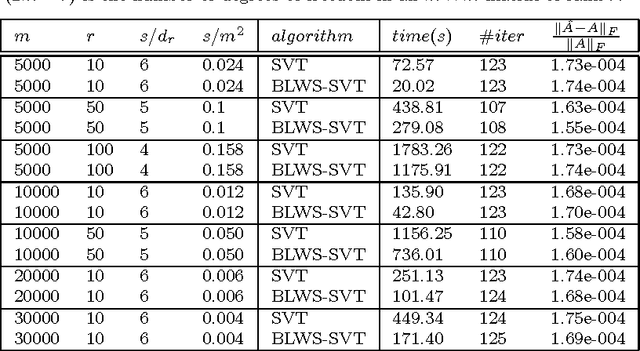
Recent years have witnessed the popularity of using rank minimization as a regularizer for various signal processing and machine learning problems. As rank minimization problems are often converted to nuclear norm minimization (NNM) problems, they have to be solved iteratively and each iteration requires computing a singular value decomposition (SVD). Therefore, their solution suffers from the high computation cost of multiple SVDs. To relieve this issue, we propose using the block Lanczos method to compute the partial SVDs, where the principal singular subspaces obtained in the previous iteration are used to start the block Lanczos procedure. To avoid the expensive reorthogonalization in the Lanczos procedure, the block Lanczos procedure is performed for only a few steps. Our block Lanczos with warm start (BLWS) technique can be adopted by different algorithms that solve NNM problems. We present numerical results on applying BLWS to Robust PCA and Matrix Completion problems. Experimental results show that our BLWS technique usually accelerates its host algorithm by at least two to three times.