 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Generic Multimodal Architecture for Batch and Streaming Big Data Integration
Aug 09, 2021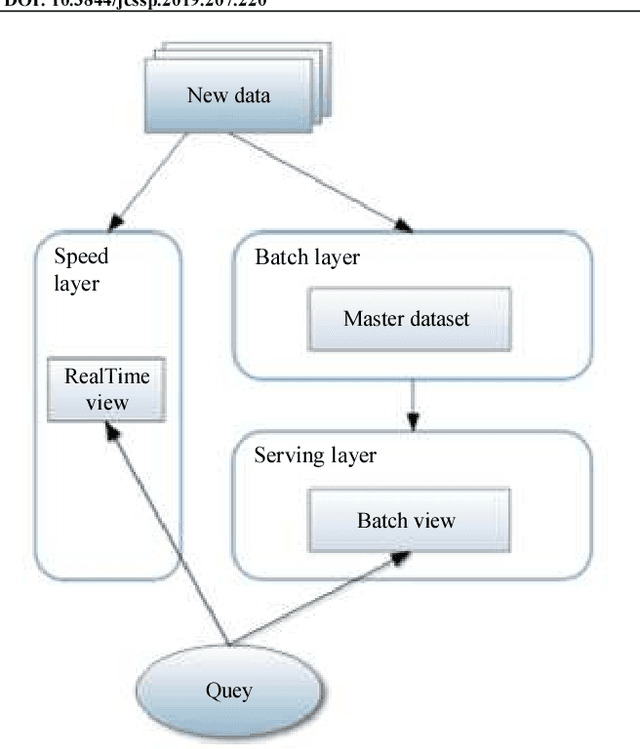
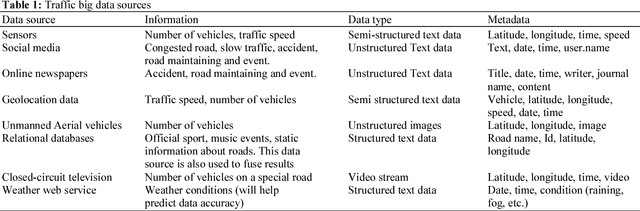
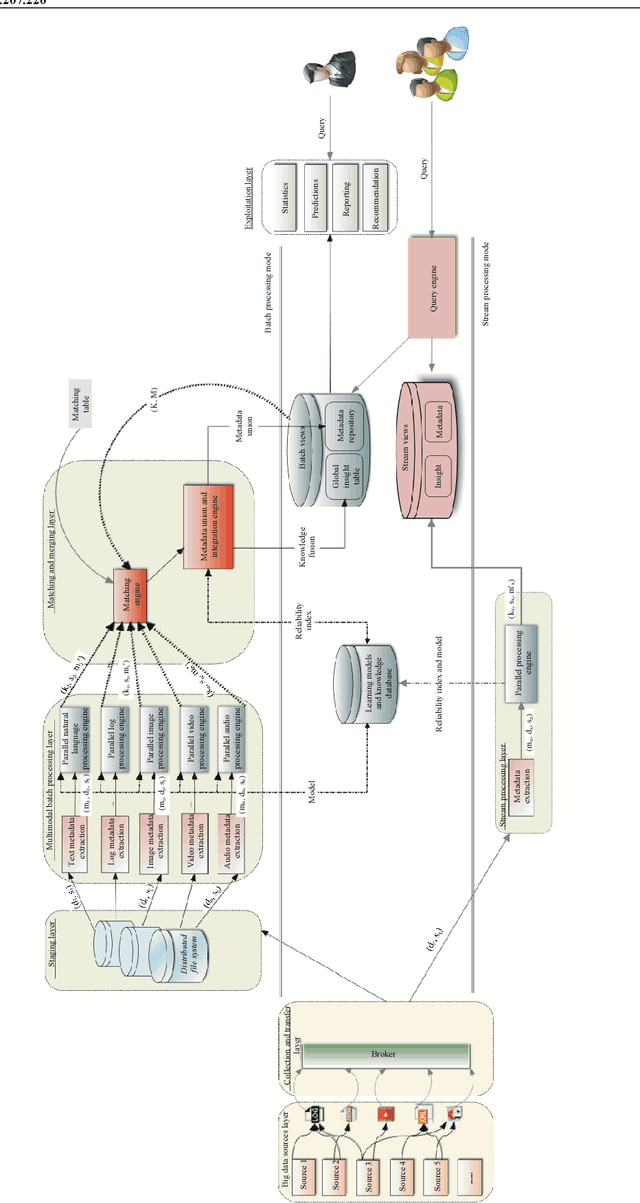
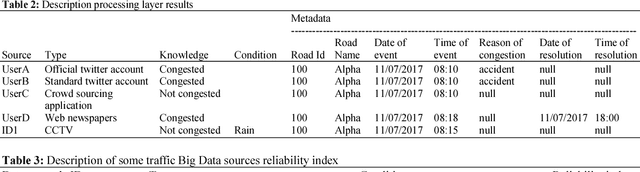
Big Data are rapidly produced from various heterogeneous data sources. They are of different types (text, image, video or audio) and have different levels of reliability and completeness. One of the most interesting architectures that deal with the large amount of emerging data at high velocity is called the lambda architecture. In fact, it combines two different processing layers namely batch and speed layers, each providing specific views of data while ensuring robustness, fast and scalable data processing. However, most papers dealing with the lambda architecture are focusing one single type of data generally produced by a single data source. Besides, the layers of the architecture are implemented independently, or, at best, are combined to perform basic processing without assessing either the data reliability or completeness. Therefore, inspired by the lambda architecture, we propose in this paper a generic multimodal architecture that combines both batch and streaming processing in order to build a complete, global and accurate insight in near-real-time based on the knowledge extracted from multiple heterogeneous Big Data sources. Our architecture uses batch processing to analyze the data structures and contents, build the learning models and calculate the reliability index of the involved sources, while the streaming processing uses the built-in models of the batch layer to immediately process incoming data and rapidly provide results. We validate our architecture in the context of urban traffic management systems in order to detect congestions.
Graph based E-Government web service composition
Nov 28, 2011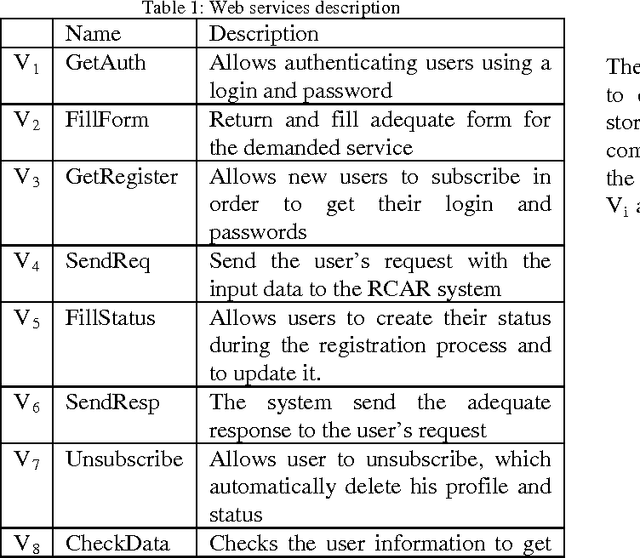
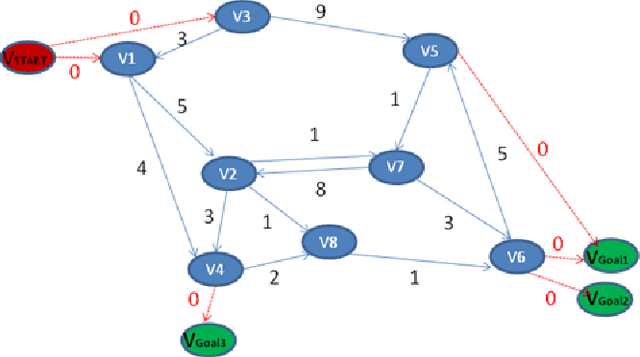
Nowadays, e-government has emerged as a government policy to improve the quality and efficiency of public administrations. By exploiting the potential of new information and communication technologies, government agencies are providing a wide spectrum of online services. These services are composed of several web services that comply with well defined processes. One of the big challenges is the need to optimize the composition of the elementary web services. In this paper, we present a solution for optimizing the computation effort in web service composition. Our method is based on Graph Theory. We model the semantic relationship between the involved web services through a directed graph. Then, we compute all shortest paths using for the first time, an extended version of the Floyd-Warshall algorithm.