 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAR: A Cross-Lingual Argument Regularizer for Semantic Role Labeling
Nov 09, 2020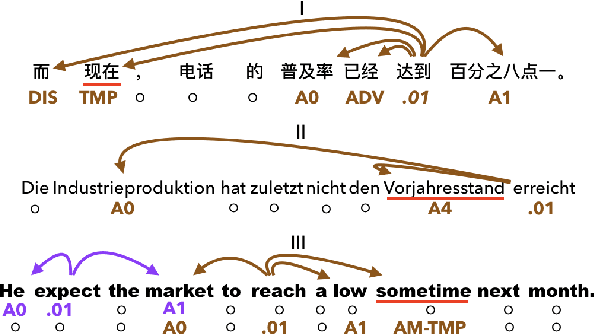
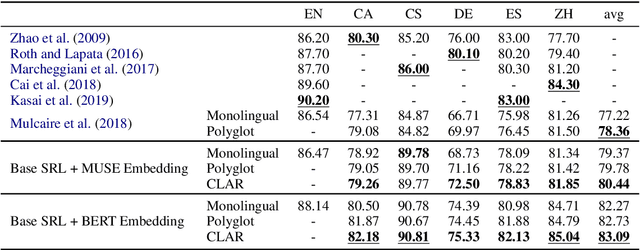
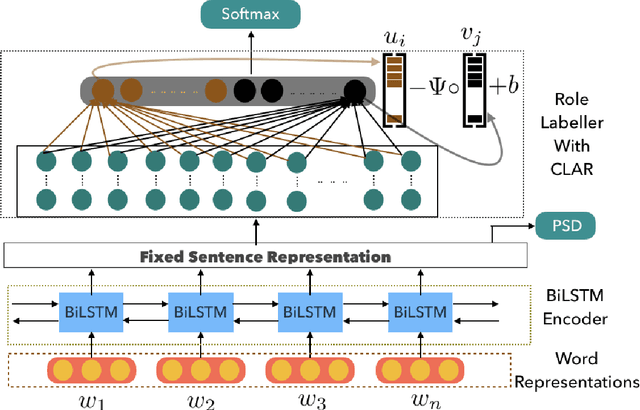

Semantic role labeling (SRL) identifies predicate-argument structure(s) in a given sentence. Although different languages have different argument annotations, polyglot training, the idea of training one model on multiple languages, has previously been shown to outperform monolingual baselines, especially for low resource languages. In fact, even a simple combination of data has been shown to be effective with polyglot training by representing the distant vocabularies in a shared representation space. Meanwhile, despite the dissimilarity in argument annotations between languages, certain argument labels do share common semantic meaning across languages (e.g. adjuncts have more or less similar semantic meaning across languages). To leverage such similarity in annotation space across languages, we propose a method called Cross-Lingual Argument Regularizer (CLAR). CLAR identifies such linguistic annotation similarity across languages and exploits this information to map the target language arguments using a transformation of the space on which source language arguments lie. By doing so, our experimental results show that CLAR consistently improves SRL performance on multiple languages over monolingual and polyglot baselines for low resource languages.
Small but Mighty: New Benchmarks for Split and Rephrase
Sep 17, 2020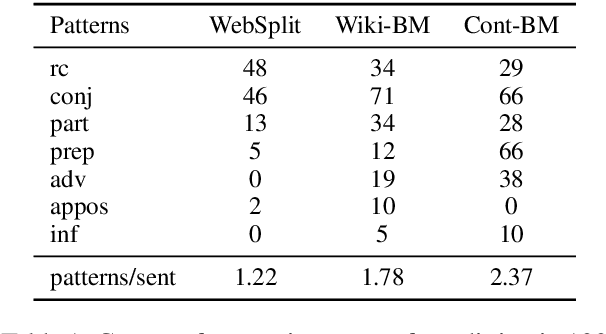
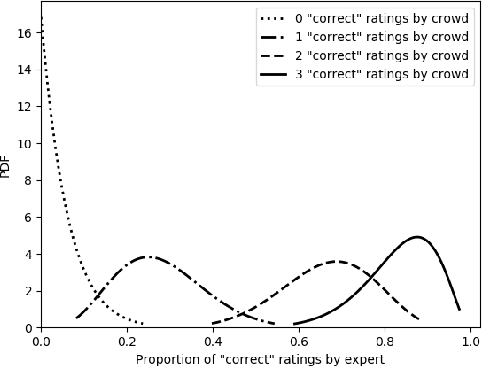
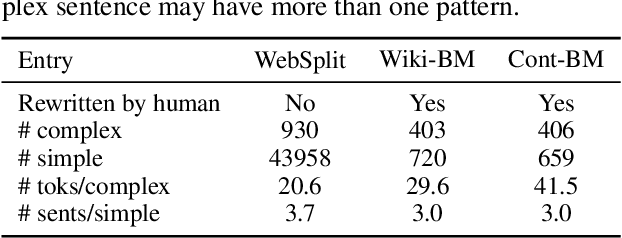
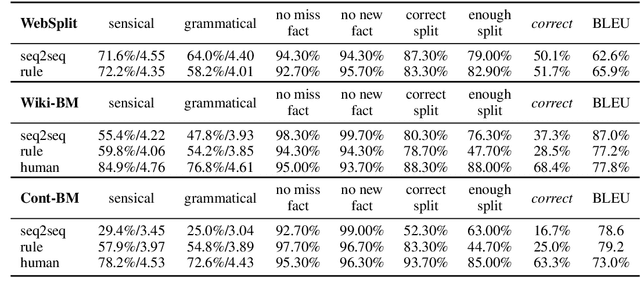
Split and Rephrase is a text simplification task of rewriting a complex sentence into simpler ones. As a relatively new task, it is paramount to ensure the soundness of its evaluation benchmark and metric. We find that the widely used benchmark dataset universally contains easily exploitable syntactic cues caused by its automatic generation process. Taking advantage of such cues, we show that even a simple rule-based model can perform on par with the state-of-the-art model. To remedy such limitations, we collect and release two crowdsourced benchmark datasets. We not only make sure that they contain significantly more diverse syntax, but also carefully control for their quality according to a well-defined set of criteria. While no satisfactory automatic metric exists, we apply fine-grained manual evaluation based on these criteria using crowdsourcing, showing that our datasets better represent the task and are significantly more challenging for the models.
Improved Language Modeling by Decoding the Past
Sep 29, 2018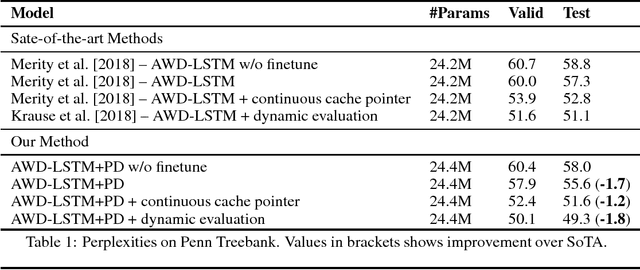
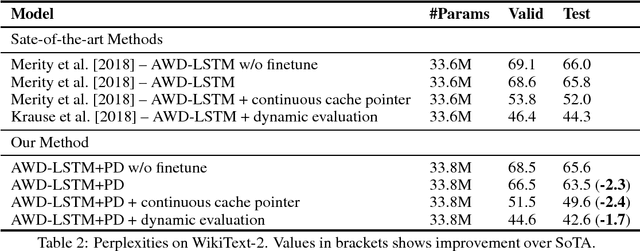
Highly regularized LSTMs achieve impressive results on several benchmark datasets in language modeling. We propose a new regularization method based on decoding the last token in the context using the predicted distribution of the next token. This biases the model towards retaining more contextual information, in turn improving its ability to predict the next token. With negligible overhead in the number of parameters and training time, our past decode regularization (PDR) method achieves state-of-the-art word level perplexity on the Penn Treebank (55.6) and WikiText-2 (63.5) datasets and bits-per-character on the Penn Treebank Character (1.169) dataset for character level language modeling. Using dynamic evaluation, we also achieve the first sub 50 perplexity of 49.3 on the Penn Treebank test set.
Unsupervised Learning of Sentence Representations Using Sequence Consistency
Sep 29, 2018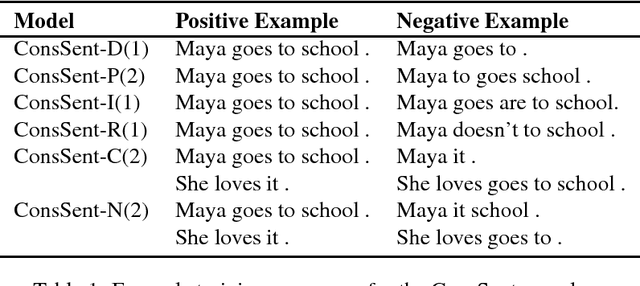
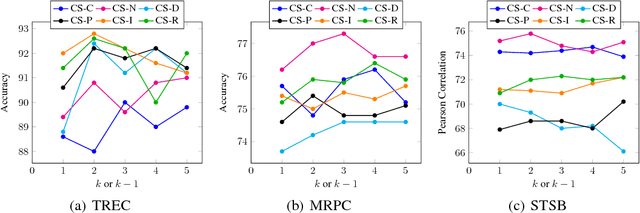
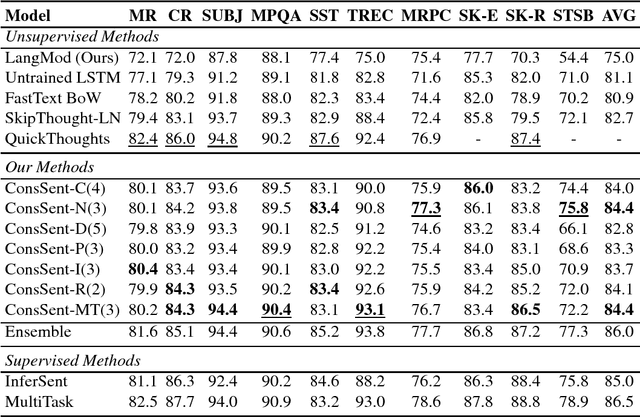
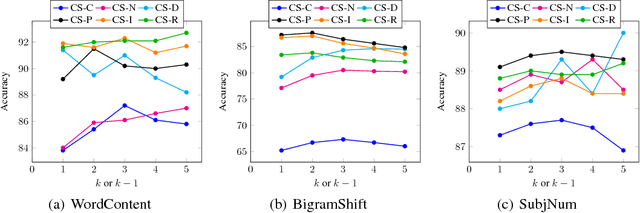
Computing universal distributed representations of sentences is a fundamental task in natural language processing. We propose a simple, yet surprisingly powerful unsupervised method to learn such representations by enforcing consistency constraints on sequences of tokens. We consider two classes of such constraints - sequences that form a sentence and between two sequences that form a sentence when merged. We learn a sentence encoder by training it to distinguish between consistent and inconsistent examples. Extensive evaluation on several transfer learning and linguistic probing tasks shows improved performance over strong unsupervised and supervised baselines, substantially surpassing them in several cases.
Improved Sentence Modeling using Suffix Bidirectional LSTM
Sep 10, 2018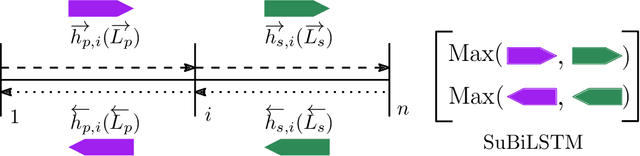
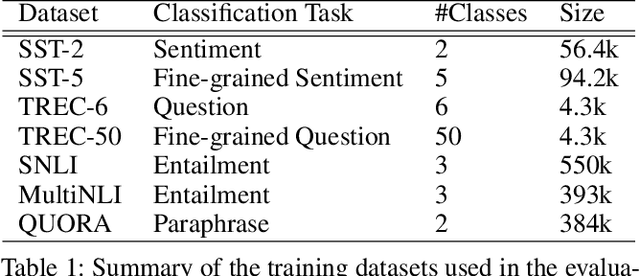
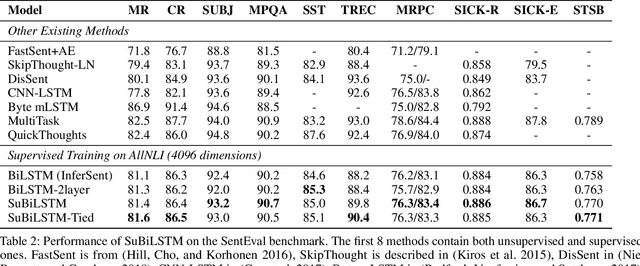
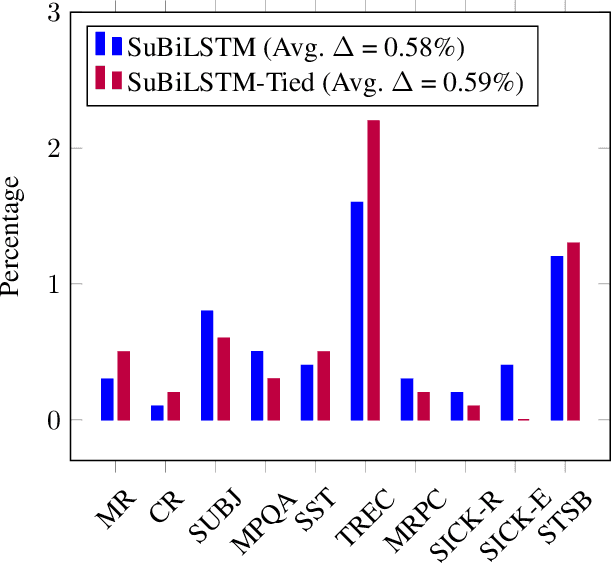
Recurrent neural networks have become ubiquitous in computing representations of sequential data, especially textual data in natural language processing. In particular, Bidirectional LSTMs are at the heart of several neural models achieving state-of-the-art performance in a wide variety of tasks in NLP. However, BiLSTMs are known to suffer from sequential bias - the contextual representation of a token is heavily influenced by tokens close to it in a sentence. We propose a general and effective improvement to the BiLSTM model which encodes each suffix and prefix of a sequence of tokens in both forward and reverse directions. We call our model Suffix Bidirectional LSTM or SuBiLSTM. This introduces an alternate bias that favors long range dependencies. We apply SuBiLSTMs to several tasks that require sentence modeling. We demonstrate that using SuBiLSTM instead of a BiLSTM in existing models leads to improvements in performance in learning general sentence representations, text classification, textual entailment and paraphrase detection. Using SuBiLSTM we achieve new state-of-the-art results for fine-grained sentiment classification and question classification.
REGMAPR - Text Matching Made Easy
Sep 10, 2018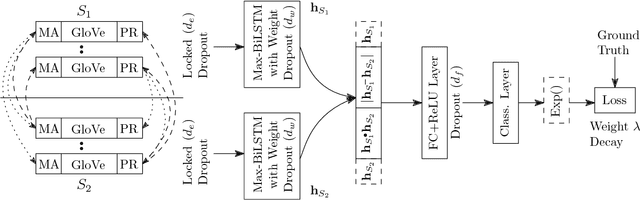
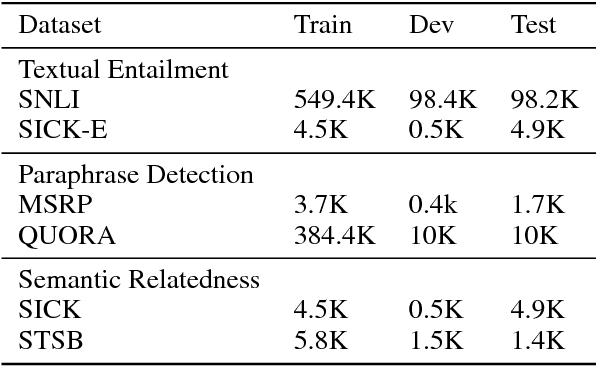
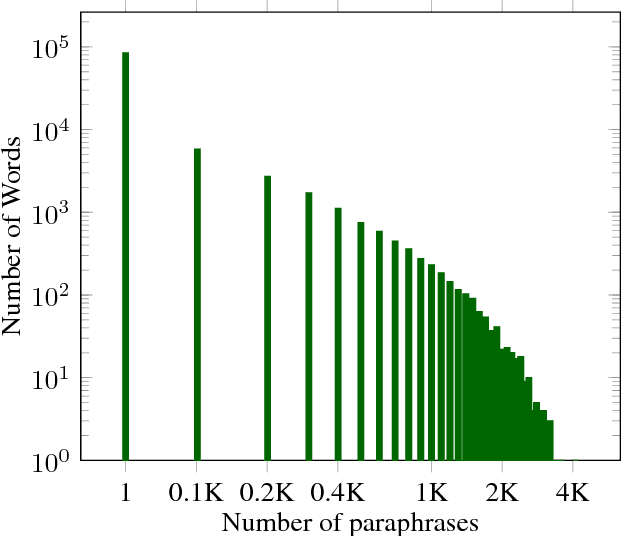

Text matching is a fundamental problem in natural language processing. Neural models using bidirectional LSTMs for sentence encoding and inter-sentence attention mechanisms perform remarkably well on several benchmark datasets. We propose REGMAPR - a simple and general architecture for text matching that does not use inter-sentence attention. Starting from a Siamese architecture, we augment the embeddings of the words with two features based on exact and para- phrase match between words in the two sentences. We train the model using three types of regularization on datasets for textual entailment, paraphrase detection and semantic related- ness. REGMAPR performs comparably or better than more complex neural models or models using a large number of handcrafted features. REGMAPR achieves state-of-the-art results for paraphrase detection on the SICK dataset and for textual entailment on the SNLI dataset among models that do not use inter-sentence attention.
On the scaling of polynomial features for representation matching
Feb 20, 2018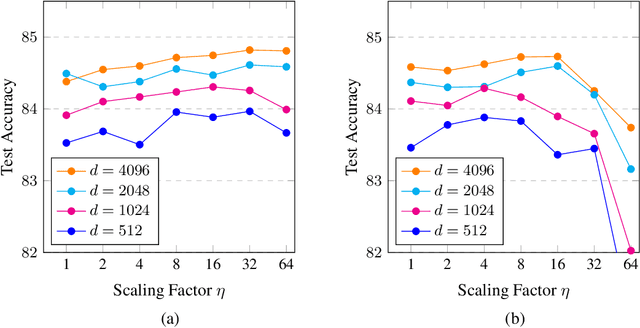
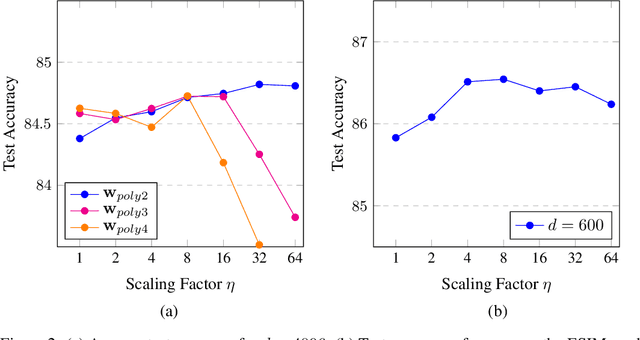
In many neural models, new features as polynomial functions of existing ones are used to augment representations. Using the natural language inference task as an example, we investigate the use of scaled polynomials of degree 2 and above as matching features. We find that scaling degree 2 features has the highest impact on performance, reducing classification error by 5% in the best models.
SufiSent - Universal Sentence Representations Using Suffix Encodings
Feb 20, 2018
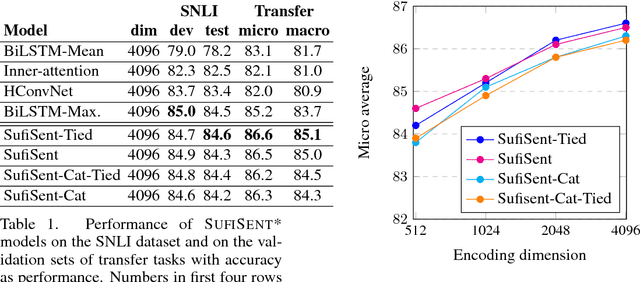
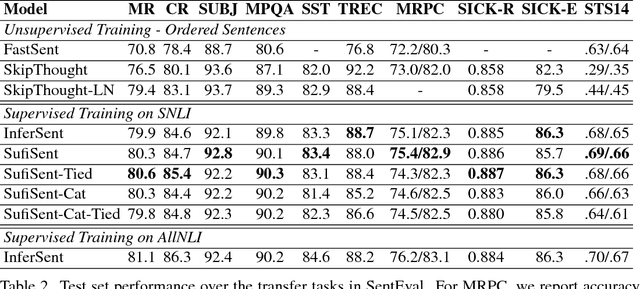
Computing universal distributed representations of sentences is a fundamental task in natural language processing. We propose a method to learn such representations by encoding the suffixes of word sequences in a sentence and training on the Stanford Natural Language Inference (SNLI) dataset. We demonstrate the effectiveness of our approach by evaluating it on the SentEval benchmark, improving on existing approaches on several transfer tasks.