 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeasanAI: In-Browser, No-Code, Offline-First Machine Learning Toolkit
Jan 07, 2025Machine learning (ML) has become crucial in modern life, with growing interest from researchers and the public. Despite its potential, a significant entry barrier prevents widespread adoption, making it challenging for non-experts to understand and implement ML techniques. The increasing desire to leverage ML is counterbalanced by its technical complexity, creating a gap between potential and practical application. This work introduces asanAI, an offline-first, open-source, no-code machine learning toolkit designed for users of all skill levels. It allows individuals to design, debug, train, and test ML models directly in a web browser, eliminating the need for software installations and coding. The toolkit runs on any device with a modern web browser, including smartphones, and ensures user privacy through local computations while utilizing WebGL for enhanced GPU performance. Users can quickly experiment with neural networks and train custom models using various data sources, supported by intuitive visualizations of network structures and data flows. asanAI simplifies the teaching of ML concepts in educational settings and is released under an open-source MIT license, encouraging modifications. It also supports exporting models in industry-ready formats, empowering a diverse range of users to effectively learn and apply machine learning in their projects. The proposed toolkit is successfully utilized by researchers of ScaDS.AI to swiftly draft and test machine learning ideas, by trainers to effectively educate enthusiasts, and by teachers to introduce contemporary ML topics in classrooms with minimal effort and high clarity.
Content-Aware Depth-Adaptive Image Restoration
Jan 10, 2024



This work prioritizes building a modular pipeline that utilizes existing models to systematically restore images, rather than creating new restoration models from scratch. Restoration is carried out at an object-specific level, with each object regenerated using its corresponding class label information. The approach stands out by providing complete user control over the entire restoration process. Users can select models for specialized restoration steps, customize the sequence of steps to meet their needs, and refine the resulting regenerated image with depth awareness. The research provides two distinct pathways for implementing image regeneration, allowing for a comparison of their respective strengths and limitations. The most compelling aspect of this versatile system is its adaptability. This adaptability enables users to target particular object categories, including medical images, by providing models that are trained on those object classes.
Assessing Anonymized System Logs Usefulness for Behavioral Analysis in RNN Models
Dec 02, 2022



System logs are a common source of monitoring data for analyzing computing systems' behavior. Due to the complexity of modern computing systems and the large size of collected monitoring data, automated analysis mechanisms are required. Numerous machine learning and deep learning methods are proposed to address this challenge. However, due to the existence of sensitive data in system logs their analysis and storage raise serious privacy concerns. Anonymization methods could be used to clean the monitoring data before analysis. However, anonymized system logs, in general, do not provide adequate usefulness for the majority of behavioral analysis. Content-aware anonymization mechanisms such as PaRS preserve the correlation of system logs even after anonymization. This work evaluates the usefulness of anonymized system logs taken from the Taurus HPC cluster anonymized using PaRS, for behavioral analysis via recurrent neural network models.
* 12 pages, 7 main figures, 2 tables, Conference: International Workshop on Data-driven Resilience Research 2022
Anomaly Detection in High Performance Computers: A Vicinity Perspective
Jun 11, 2019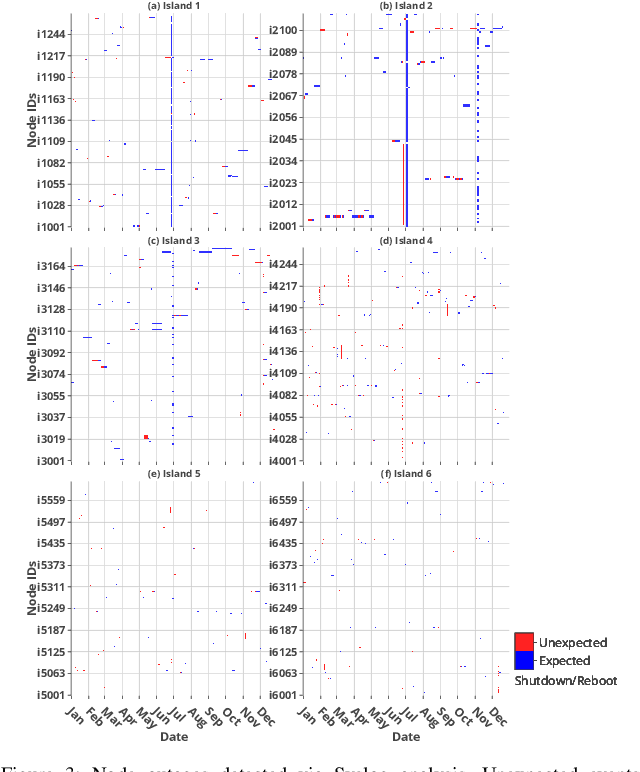
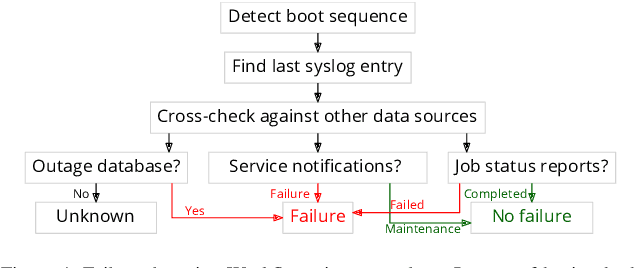
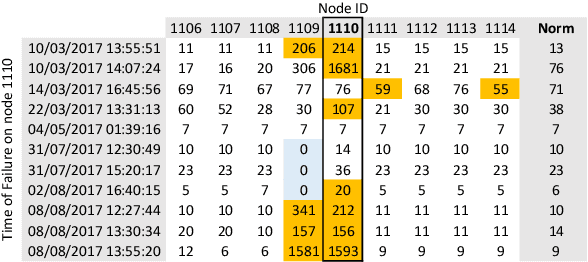
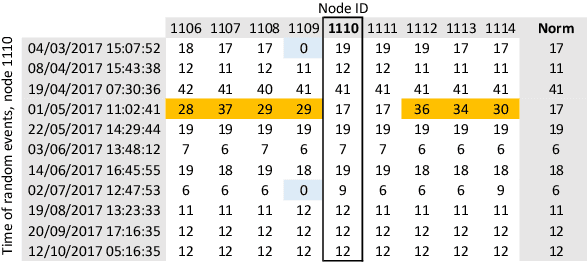
In response to the demand for higher computational power, the number of computing nodes in high performance computers (HPC) increases rapidly. Exascale HPC systems are expected to arrive by 2020. With drastic increase in the number of HPC system components, it is expected to observe a sudden increase in the number of failures which, consequently, poses a threat to the continuous operation of the HPC systems. Detecting failures as early as possible and, ideally, predicting them, is a necessary step to avoid interruptions in HPC systems operation. Anomaly detection is a well-known general purpose approach for failure detection, in computing systems. The majority of existing methods are designed for specific architectures, require adjustments on the computing systems hardware and software, need excessive information, or pose a threat to users' and systems' privacy. This work proposes a node failure detection mechanism based on a vicinity-based statistical anomaly detection approach using passively collected and anonymized system log entries. Application of the proposed approach on system logs collected over 8 months indicates an anomaly detection precision between 62% to 81%.