 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARMA: Collocation-Aware Resource Manager with GPU Memory Estimator
Aug 26, 2025



Studies conducted on enterprise-scale infrastructure have shown that GPUs -- the core computational resource for deep learning (DL) training -- are often significantly underutilized. DL task collocation on GPUs is an opportunity to address this challenge. However, it may result in (1) out-of-memory crashes for the subsequently arriving task and (2) slowdowns for all tasks sharing the GPU due to resource interference. The former challenge poses a threat to robustness, while the latter affects the quality of service and energy efficiency. We propose CARMA, a server-scale task-level collocation-aware resource management system that handles both collocation challenges. CARMA encompasses GPUMemNet, a novel ML-based GPU memory estimator framework for DL training tasks, to minimize out-of-memory errors and introduces collocation policies that cap GPU utilization to minimize interference. Furthermore, CARMA introduces a recovery method to ensure robust restart of tasks that crash. Our evaluation on traces modeled after real-world DL training task traces shows that CARMA increases the GPU utilization over time by 39.3\%, decreases the end-to-end execution time by $\sim$26.7\%, and reduces the GPU energy use by $\sim$14.2\%.
A Comparative Study of OpenMP Scheduling Algorithm Selection Strategies
Jul 27, 2025



Scientific and data science applications are becoming increasingly complex, with growing computational and memory demands. Modern high performance computing (HPC) systems provide high parallelism and heterogeneity across nodes, devices, and cores. To achieve good performance, effective scheduling and load balancing techniques are essential. Parallel programming frameworks such as OpenMP now offer a variety of advanced scheduling algorithms to support diverse applications and platforms. This creates an instance of the scheduling algorithm selection problem, which involves identifying the most suitable algorithm for a given combination of workload and system characteristics. In this work, we explore learning-based approaches for selecting scheduling algorithms in OpenMP. We propose and evaluate expert-based and reinforcement learning (RL)-based methods, and conduct a detailed performance analysis across six applications and three systems. Our results show that RL methods are capable of learning high-performing scheduling decisions, although they require significant exploration, with the choice of reward function playing a key role. Expert-based methods, in contrast, rely on prior knowledge and involve less exploration, though they may not always identify the optimal algorithm for a specific application-system pair. By combining expert knowledge with RL-based learning, we achieve improved performance and greater adaptability. Overall, this work demonstrates that dynamic selection of scheduling algorithms during execution is both viable and beneficial for OpenMP applications. The approach can also be extended to MPI-based programs, enabling optimization of scheduling decisions across multiple levels of parallelism.
Toward a Standard Interface for User-Defined Scheduling in OpenMP
Jul 08, 2019

Parallel loops are an important part of OpenMP programs. Efficient scheduling of parallel loops can improve performance of the programs. The current OpenMP specification only offers three options for loop scheduling, which are insufficient in certain instances. Given the large number of other possible scheduling strategies, it is infeasible to standardize each one. A more viable approach is to extend the OpenMP standard to allow for users to define loop scheduling strategies. The approach will enable standard-compliant application-specific scheduling. This work analyzes the principal components required by user-defined scheduling and proposes two competing interfaces as candidates for the OpenMP standard. We conceptually compare the two proposed interfaces with respect to the three host languages of OpenMP, i.e., C, C++, and Fortran. These interfaces serve the OpenMP community as a basis for discussion and prototype implementation for user-defined scheduling.
Anomaly Detection in High Performance Computers: A Vicinity Perspective
Jun 11, 2019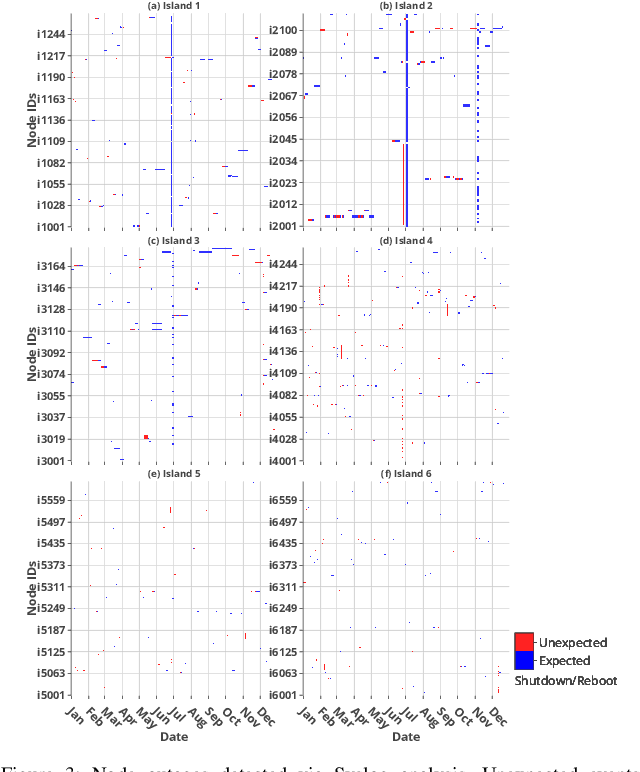
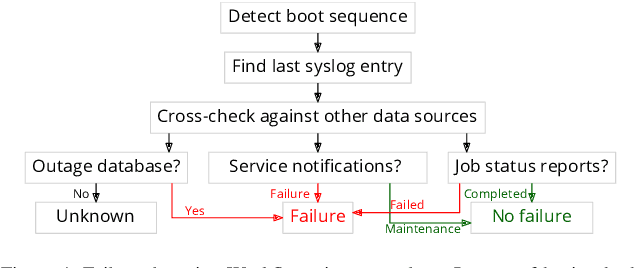
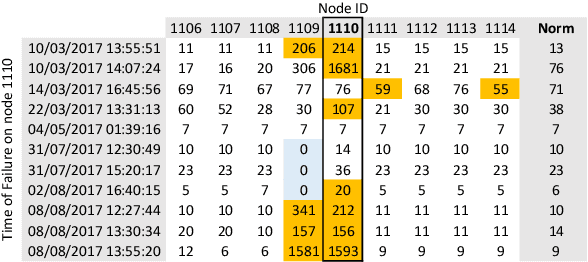
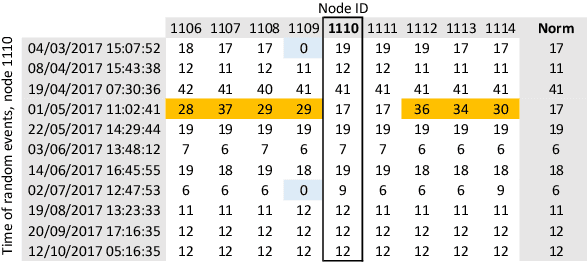
In response to the demand for higher computational power, the number of computing nodes in high performance computers (HPC) increases rapidly. Exascale HPC systems are expected to arrive by 2020. With drastic increase in the number of HPC system components, it is expected to observe a sudden increase in the number of failures which, consequently, poses a threat to the continuous operation of the HPC systems. Detecting failures as early as possible and, ideally, predicting them, is a necessary step to avoid interruptions in HPC systems operation. Anomaly detection is a well-known general purpose approach for failure detection, in computing systems. The majority of existing methods are designed for specific architectures, require adjustments on the computing systems hardware and software, need excessive information, or pose a threat to users' and systems' privacy. This work proposes a node failure detection mechanism based on a vicinity-based statistical anomaly detection approach using passively collected and anonymized system log entries. Application of the proposed approach on system logs collected over 8 months indicates an anomaly detection precision between 62% to 81%.