 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINFRA: A One Stop Shop for Computing Multilingual Semantic Relatedness
May 16, 2018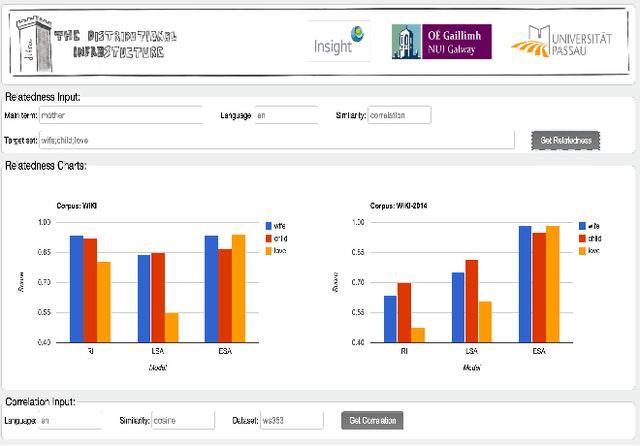
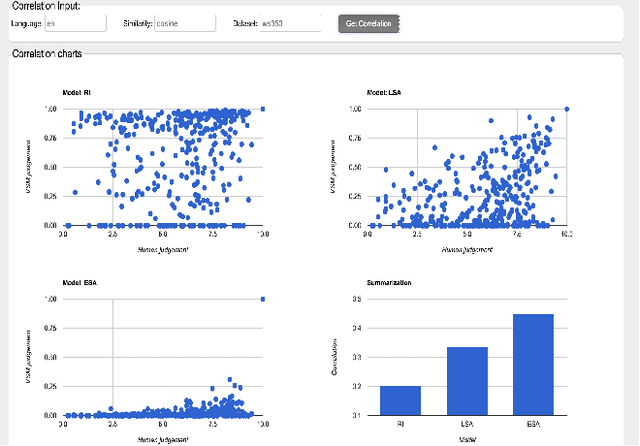
This demonstration presents an infrastructure for computing multilingual semantic relatedness and correlation for twelve natural languages by using three distributional semantic models (DSMs). Our demonsrator - DInfra (Distributional Infrastructure) provides researchers and developers with a highly useful platform for processing large-scale corpora and conducting experiments with distributional semantics. We integrate several multilingual DSMs in our webservice so the end user can obtain a result without worrying about the complexities involved in building DSMs. Our webservice allows the users to have easy access to a wide range of comparisons of DSMs with different parameters. In addition, users can configure and access DSM parameters using an easy to use API.
Semantic Relatedness for All (Languages): A Comparative Analysis of Multilingual Semantic Relatedness Using Machine Translation
May 16, 2018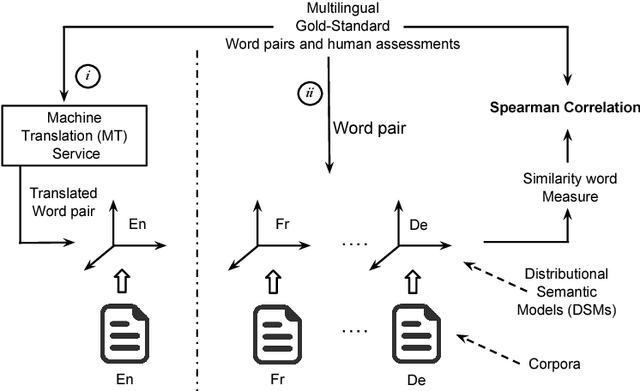
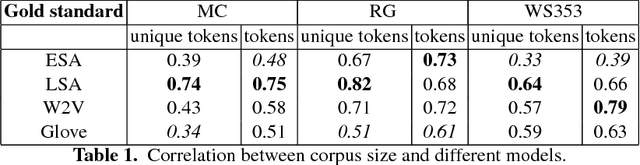
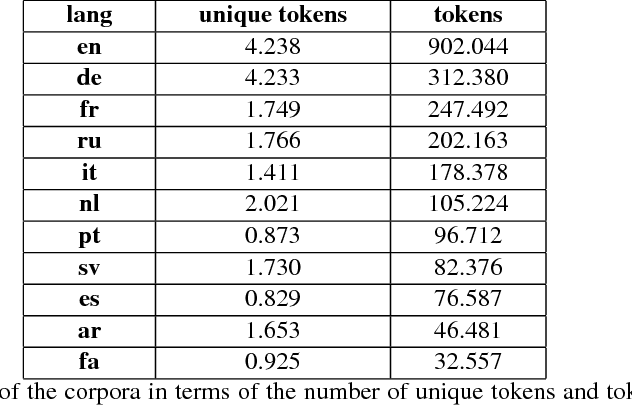
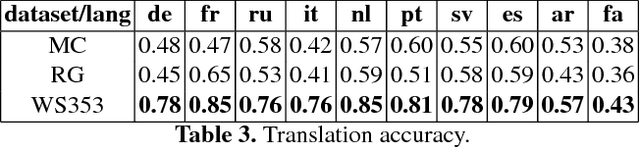
This paper provides a comparative analysis of the performance of four state-of-the-art distributional semantic models (DSMs) over 11 languages, contrasting the native language-specific models with the use of machine translation over English-based DSMs. The experimental results show that there is a significant improvement (average of 16.7% for the Spearman correlation) by using state-of-the-art machine translation approaches. The results also show that the benefit of using the most informative corpus outweighs the possible errors introduced by the machine translation. For all languages, the combination of machine translation over the Word2Vec English distributional model provided the best results consistently (average Spearman correlation of 0.68).
Composite Semantic Relation Classification
May 16, 2018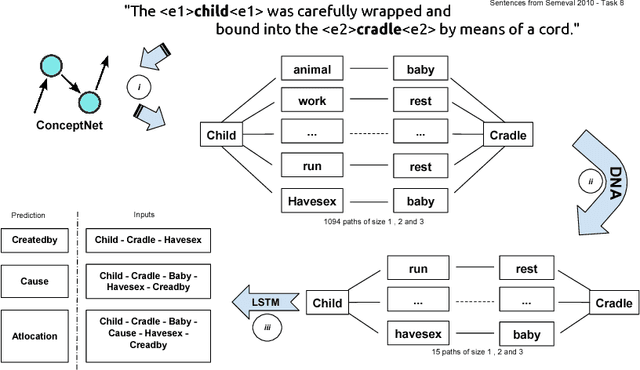
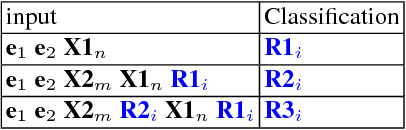
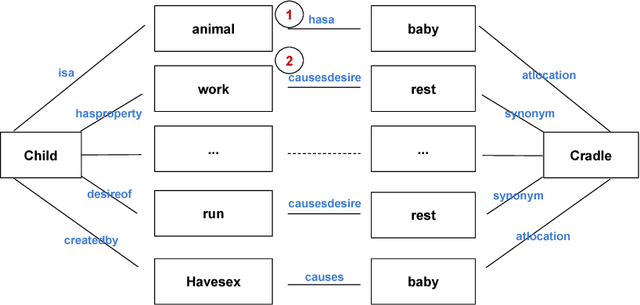
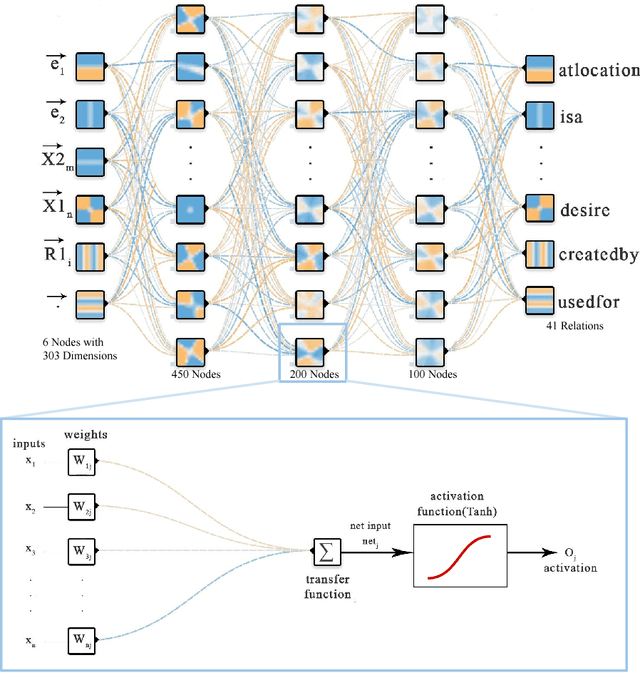
Different semantic interpretation tasks such as text entailment and question answering require the classification of semantic relations between terms or entities within text. However, in most cases it is not possible to assign a direct semantic relation between entities/terms. This paper proposes an approach for composite semantic relation classification, extending the traditional semantic relation classification task. Different from existing approaches, which use machine learning models built over lexical and distributional word vector features, the proposed model uses the combination of a large commonsense knowledge base of binary relations, a distributional navigational algorithm and sequence classification to provide a solution for the composite semantic relation classification problem.