 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Many generalization measures for deep learning are fragile
Oct 21, 2025A wide variety of generalization measures have been applied to deep neural networks (DNNs). Although obtaining tight bounds remains challenging, such measures are often assumed to reproduce qualitative generalization trends. In this position paper, we argue that many post-mortem generalization measures -- those computed on trained networks -- are \textbf{fragile}: small training modifications that barely affect the underlying DNN can substantially change a measure's value, trend, or scaling behavior. For example, minor hyperparameter changes, such as learning rate adjustments or switching between SGD variants can reverse the slope of a learning curve in widely used generalization measures like the path norm. We also identify subtler forms of fragility. For instance, the PAC-Bayes origin measure is regarded as one of the most reliable, and is indeed less sensitive to hyperparameter tweaks than many other measures. However, it completely fails to capture differences in data complexity across learning curves. This data fragility contrasts with the function-based marginal-likelihood PAC-Bayes bound, which does capture differences in data-complexity, including scaling behavior, in learning curves, but which is not a post-mortem measure. Beyond demonstrating that many bounds -- such as path, spectral and Frobenius norms, flatness proxies, and deterministic PAC-Bayes surrogates -- are fragile, this position paper also argues that developers of new measures should explicitly audit them for fragility.
Why Flatness Correlates With Generalization For Deep Neural Networks
Mar 10, 2021

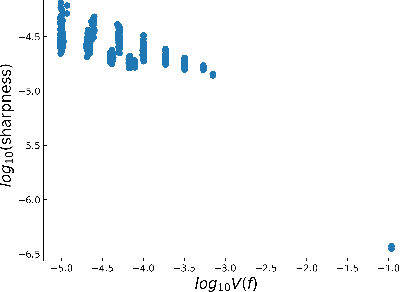

The intuition that local flatness of the loss landscape is correlated with better generalization for deep neural networks (DNNs) has been explored for decades, spawning many different local flatness measures. Here we argue that these measures correlate with generalization because they are local approximations to a global property, the volume of the set of parameters mapping to a specific function. This global volume is equivalent to the Bayesian prior upon initialization. For functions that give zero error on a test set, it is directly proportional to the Bayesian posterior, making volume a more robust and theoretically better grounded predictor of generalization than flatness. Whilst flatness measures fail under parameter re-scaling, volume remains invariant and therefore continues to correlate well with generalization. Moreover, some variants of SGD can break the flatness-generalization correlation, while the volume-generalization correlation remains intact.