 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Neural Architectures for Audio Event Detection
May 06, 2022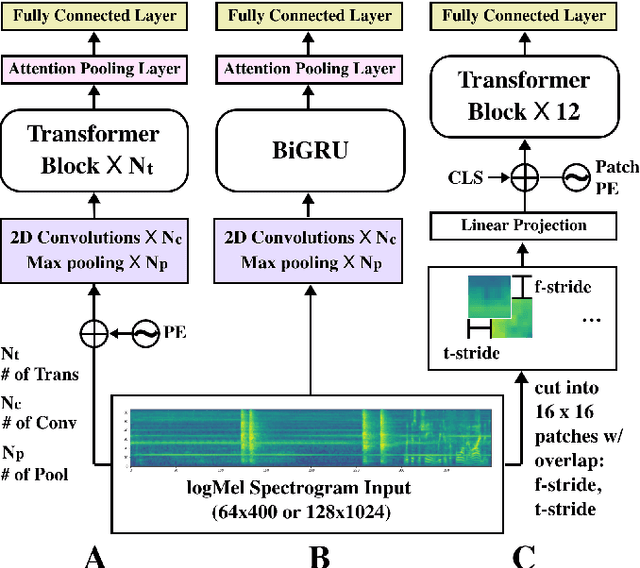
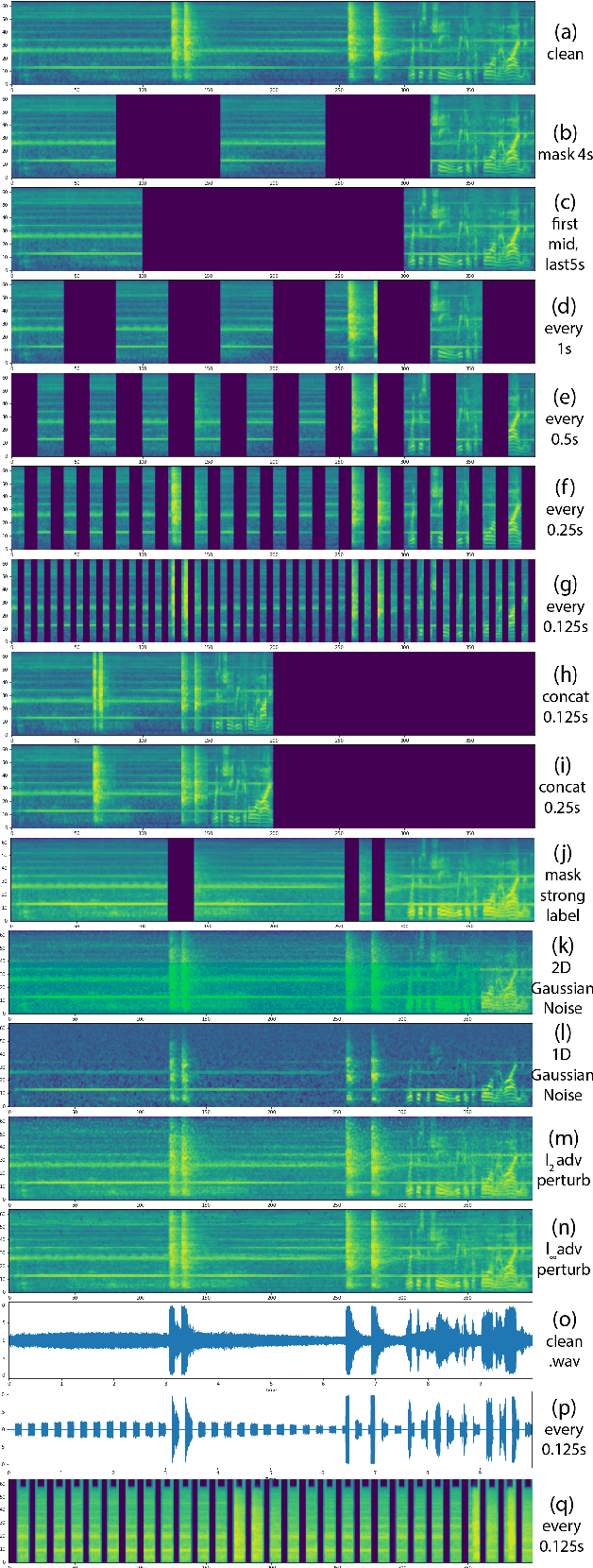
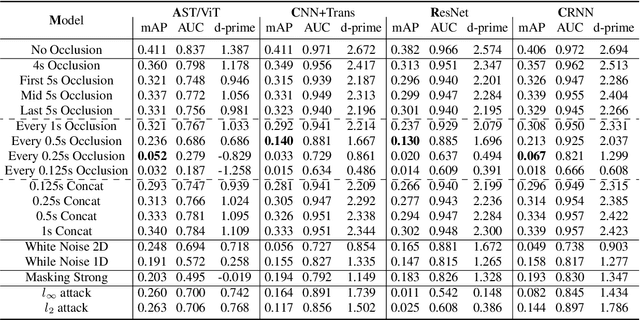
Traditionally, in Audio Recognition pipeline, noise is suppressed by the "frontend", relying on preprocessing techniques such as speech enhancement. However, it is not guaranteed that noise will not cascade into downstream pipelines. To understand the actual influence of noise on the entire audio pipeline, in this paper, we directly investigate the impact of noise on a different types of neural models without the preprocessing step. We measure the recognition performances of 4 different neural network models on the task of environment sound classification under the 3 types of noises: \emph{occlusion} (to emulate intermittent noise), \emph{Gaussian} noise (models continuous noise), and \emph{adversarial perturbations} (worst case scenario). Our intuition is that the different ways in which these models process their input (i.e. CNNs have strong locality inductive biases, which Transformers do not have) should lead to observable differences in performance and/ or robustness, an understanding of which will enable further improvements. We perform extensive experiments on AudioSet which is the largest weakly-labeled sound event dataset available. We also seek to explain the behaviors of different models through output distribution change and weight visualization.
AudioTagging Done Right: 2nd comparison of deep learning methods for environmental sound classification
Apr 03, 2022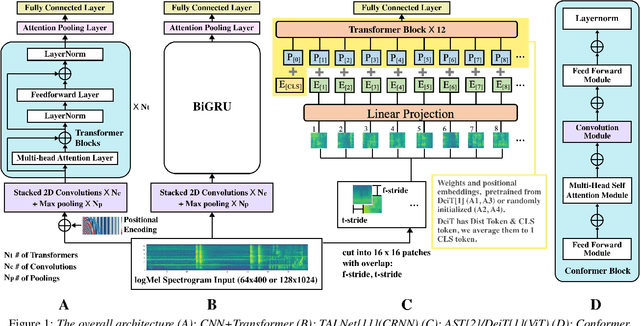
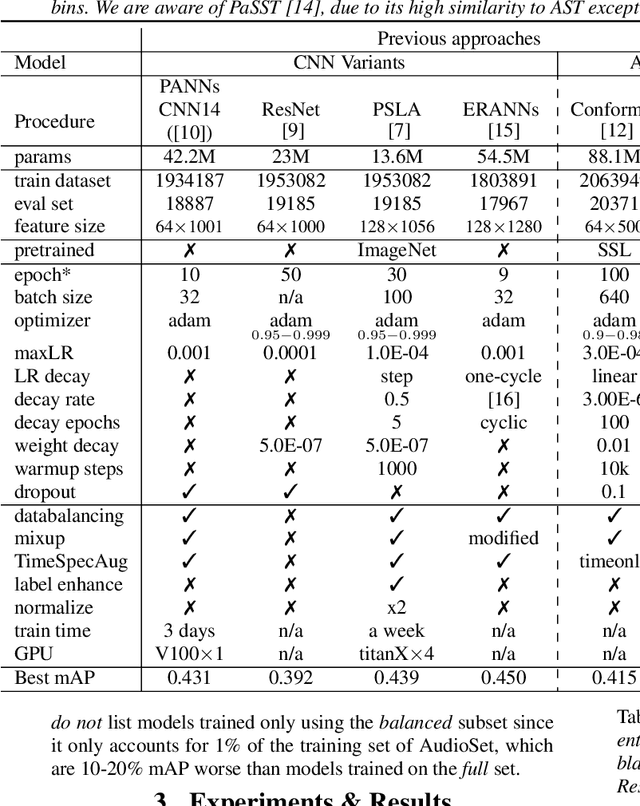
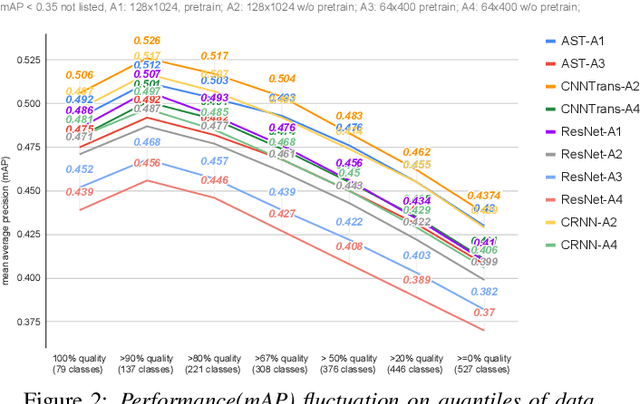

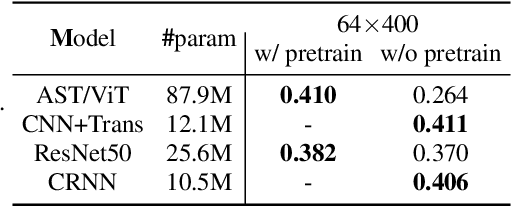
After its sweeping success in vision and language tasks, pure attention-based neural architectures (e.g. DeiT) are emerging to the top of audio tagging (AT) leaderboards, which seemingly obsoletes traditional convolutional neural networks (CNNs), feed-forward networks or recurrent networks. However, taking a closer look, there is great variability in published research, for instance, performances of models initialized with pretrained weights differ drastically from without pretraining, training time for a model varies from hours to weeks, and often, essences are hidden in seemingly trivial details. This urgently calls for a comprehensive study since our 1st comparison is half-decade old. In this work, we perform extensive experiments on AudioSet which is the largest weakly-labeled sound event dataset available, we also did an analysis based on the data quality and efficiency. We compare a few state-of-the-art baselines on the AT task, and study the performance and efficiency of 2 major categories of neural architectures: CNN variants and attention-based variants. We also closely examine their optimization procedures. Our opensourced experimental results provide insights to trade-off between performance, efficiency, optimization process, for both practitioners and researchers. Implementation: https://github.com/lijuncheng16/AudioTaggingDoneRight
On Adversarial Robustness of Large-scale Audio Visual Learning
Mar 23, 2022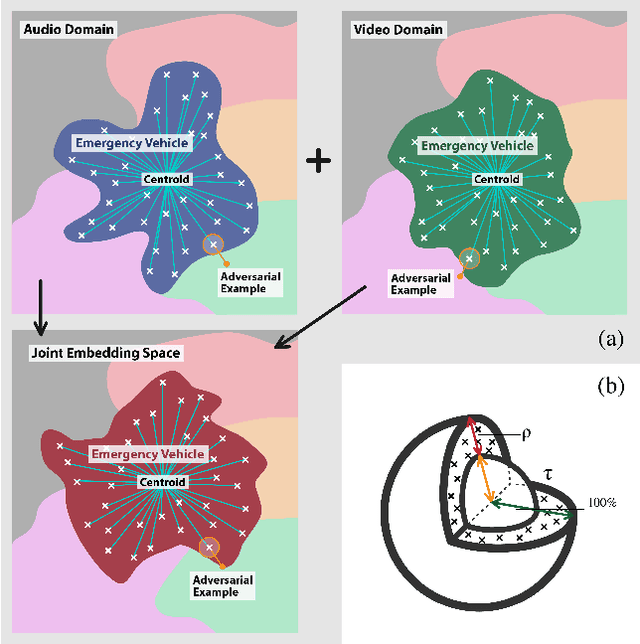
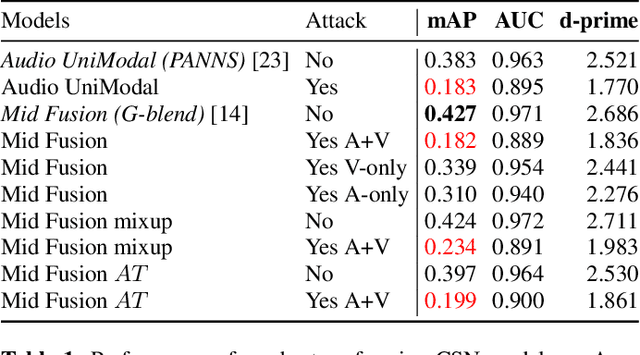
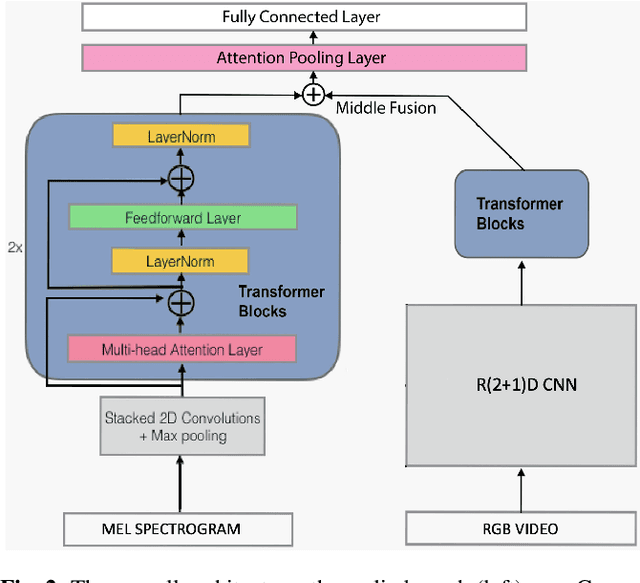
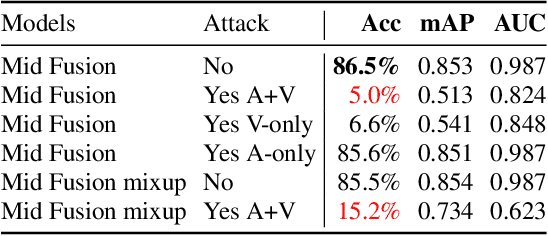
As audio-visual systems are being deployed for safety-critical tasks such as surveillance and malicious content filtering, their robustness remains an under-studied area. Existing published work on robustness either does not scale to large-scale dataset, or does not deal with multiple modalities. This work aims to study several key questions related to multi-modal learning through the lens of robustness: 1) Are multi-modal models necessarily more robust than uni-modal models? 2) How to efficiently measure the robustness of multi-modal learning? 3) How to fuse different modalities to achieve a more robust multi-modal model? To understand the robustness of the multi-modal model in a large-scale setting, we propose a density-based metric, and a convexity metric to efficiently measure the distribution of each modality in high-dimensional latent space. Our work provides a theoretical intuition together with empirical evidence showing how multi-modal fusion affects adversarial robustness through these metrics. We further devise a mix-up strategy based on our metrics to improve the robustness of the trained model. Our experiments on AudioSet and Kinetics-Sounds verify our hypothesis that multi-modal models are not necessarily more robust than their uni-modal counterparts in the face of adversarial examples. We also observe our mix-up trained method could achieve as much protection as traditional adversarial training, offering a computationally cheap alternative. Implementation: https://github.com/lijuncheng16/AudioSetDoneRight
Audio-Visual Event Recognition through the lens of Adversary
Nov 15, 2020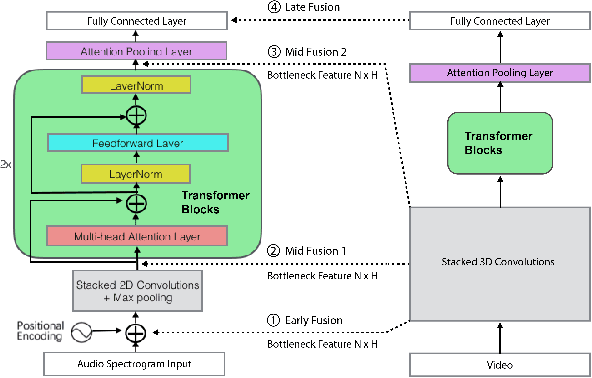
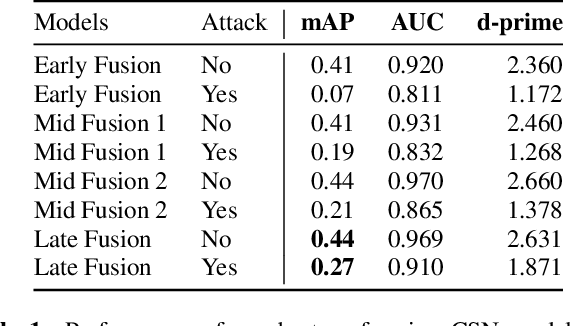
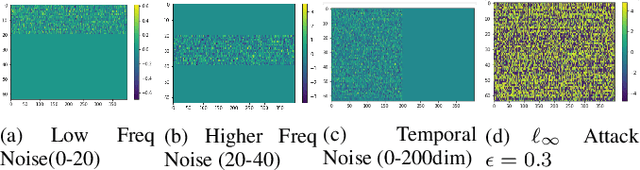
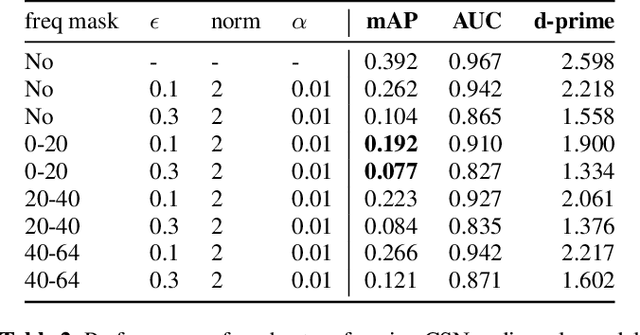
As audio/visual classification models are widely deployed for sensitive tasks like content filtering at scale, it is critical to understand their robustness along with improving the accuracy. This work aims to study several key questions related to multimodal learning through the lens of adversarial noises: 1) The trade-off between early/middle/late fusion affecting its robustness and accuracy 2) How do different frequency/time domain features contribute to the robustness? 3) How do different neural modules contribute to the adversarial noise? In our experiment, we construct adversarial examples to attack state-of-the-art neural models trained on Google AudioSet. We compare how much attack potency in terms of adversarial perturbation of size $\epsilon$ using different $L_p$ norms we would need to "deactivate" the victim model. Using adversarial noise to ablate multimodal models, we are able to provide insights into what is the best potential fusion strategy to balance the model parameters/accuracy and robustness trade-off and distinguish the robust features versus the non-robust features that various neural networks model tend to learn.
Adversarial Music: Real World Audio Adversary Against Wake-word Detection System
Dec 06, 2019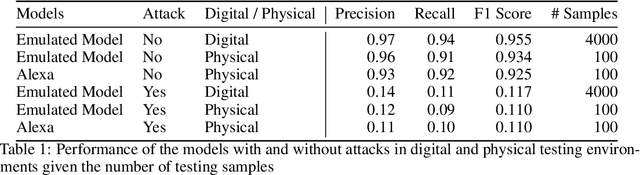
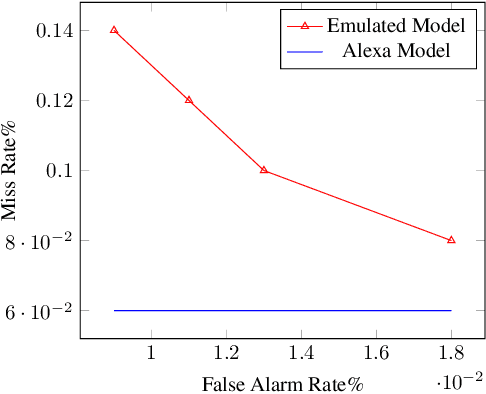

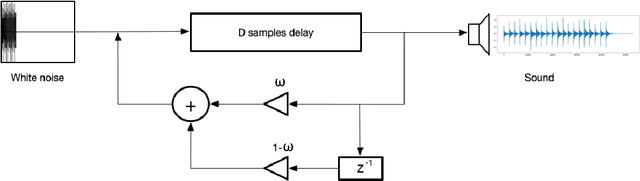
Voice Assistants (VAs) such as Amazon Alexa or Google Assistant rely on wake-word detection to respond to people's commands, which could potentially be vulnerable to audio adversarial examples. In this work, we target our attack on the wake-word detection system, jamming the model with some inconspicuous background music to deactivate the VAs while our audio adversary is present. We implemented an emulated wake-word detection system of Amazon Alexa based on recent publications. We validated our models against the real Alexa in terms of wake-word detection accuracy. Then we computed our audio adversaries with consideration of expectation over transform and we implemented our audio adversary with a differentiable synthesizer. Next, we verified our audio adversaries digitally on hundreds of samples of utterances collected from the real world. Our experiments show that we can effectively reduce the recognition F1 score of our emulated model from 93.4% to 11.0%. Finally, we tested our audio adversary over the air, and verified it works effectively against Alexa, reducing its F1 score from 92.5% to 11.0%.; We also verified that non-adversarial music does not disable Alexa as effectively as our music at the same sound level. To the best of our knowledge, this is the first real-world adversarial attack against a commercial-grade VA wake-word detection system. Our code and demo videos can be accessed at \url{https://www.junchengbillyli.com/AdversarialMusic}
* 9 pages, In Proceedings of NeurIPS 2019 Conference
A Comparison of deep learning methods for environmental sound
Mar 20, 2017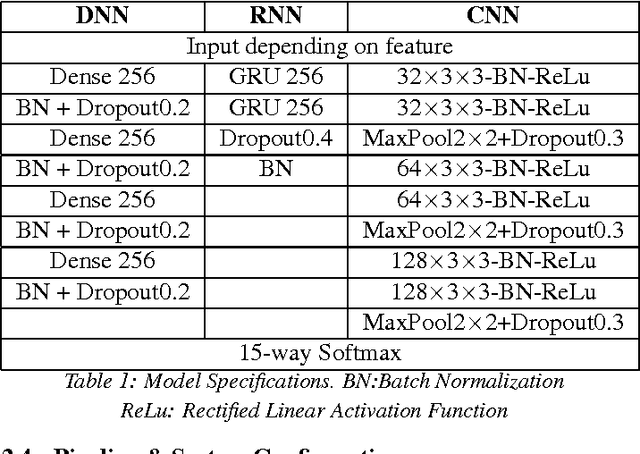
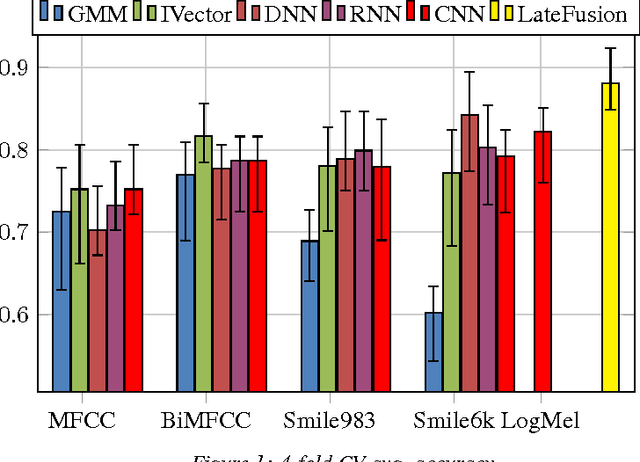
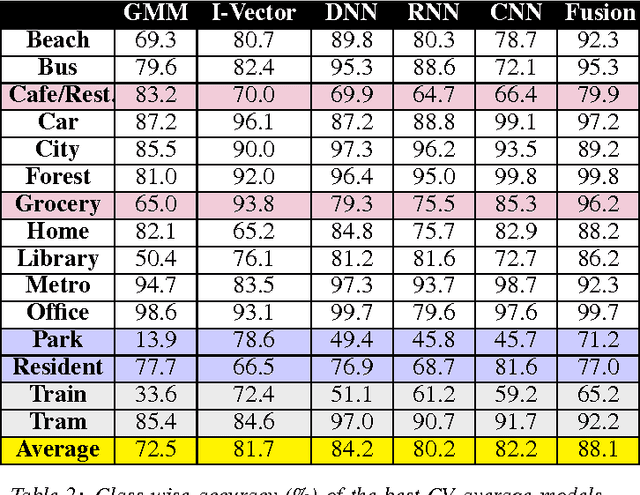
Environmental sound detection is a challenging application of machine learning because of the noisy nature of the signal, and the small amount of (labeled) data that is typically available. This work thus presents a comparison of several state-of-the-art Deep Learning models on the IEEE challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) 2016 challenge task and data, classifying sounds into one of fifteen common indoor and outdoor acoustic scenes, such as bus, cafe, car, city center, forest path, library, train, etc. In total, 13 hours of stereo audio recordings are available, making this one of the largest datasets available. We perform experiments on six sets of features, including standard Mel-frequency cepstral coefficients (MFCC), Binaural MFCC, log Mel-spectrum and two different large- scale temporal pooling features extracted using OpenSMILE. On these features, we apply five models: Gaussian Mixture Model (GMM), Deep Neural Network (DNN), Recurrent Neural Network (RNN), Convolutional Deep Neural Net- work (CNN) and i-vector. Using the late-fusion approach, we improve the performance of the baseline 72.5% by 15.6% in 4-fold Cross Validation (CV) avg. accuracy and 11% in test accuracy, which matches the best result of the DCASE 2016 challenge. With large feature sets, deep neural network models out- perform traditional methods and achieve the best performance among all the studied methods. Consistent with other work, the best performing single model is the non-temporal DNN model, which we take as evidence that sounds in the DCASE challenge do not exhibit strong temporal dynamics.
* 5 pages including reference
Learning Filter Banks Using Deep Learning For Acoustic Signals
Nov 29, 2016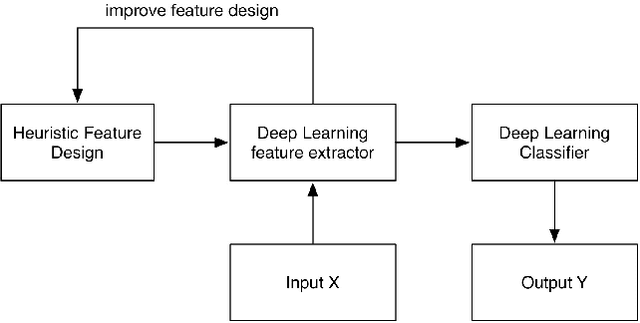
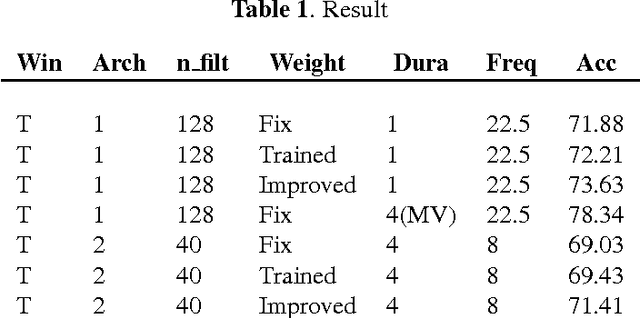
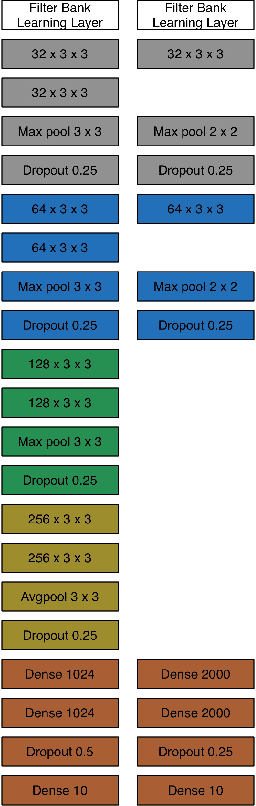
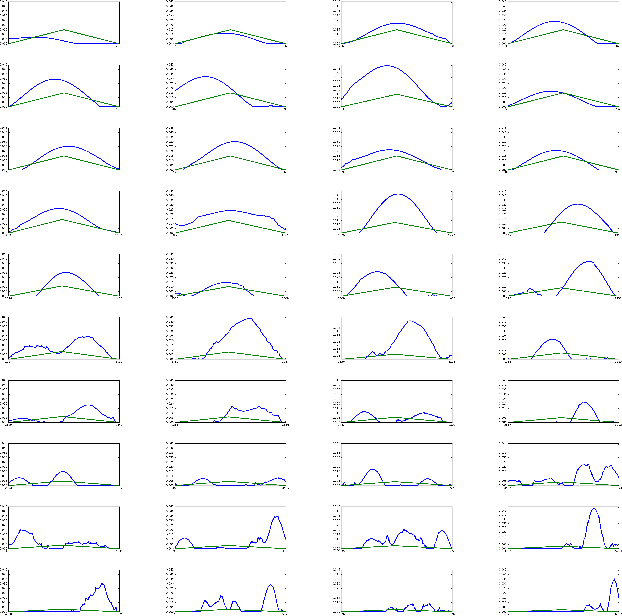
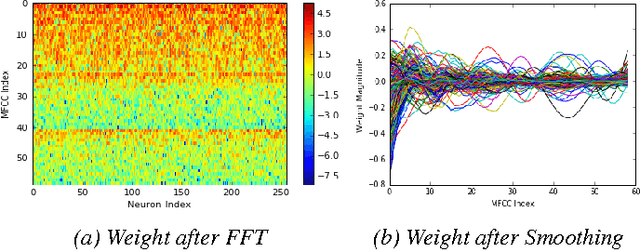
Designing appropriate features for acoustic event recognition tasks is an active field of research. Expressive features should both improve the performance of the tasks and also be interpret-able. Currently, heuristically designed features based on the domain knowledge requires tremendous effort in hand-crafting, while features extracted through deep network are difficult for human to interpret. In this work, we explore the experience guided learning method for designing acoustic features. This is a novel hybrid approach combining both domain knowledge and purely data driven feature designing. Based on the procedure of log Mel-filter banks, we design a filter bank learning layer. We concatenate this layer with a convolutional neural network (CNN) model. After training the network, the weight of the filter bank learning layer is extracted to facilitate the design of acoustic features. We smooth the trained weight of the learning layer and re-initialize it in filter bank learning layer as audio feature extractor. For the environmental sound recognition task based on the Urban- sound8K dataset, the experience guided learning leads to a 2% accuracy improvement compared with the fixed feature extractors (the log Mel-filter bank). The shape of the new filter banks are visualized and explained to prove the effectiveness of the feature design process.
Very Deep Convolutional Neural Networks for Raw Waveforms
Oct 01, 2016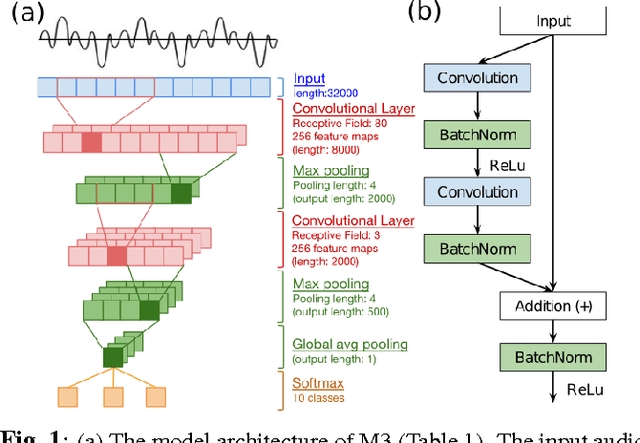
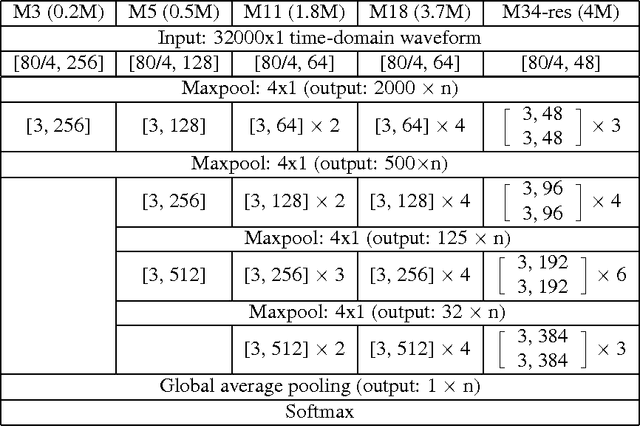
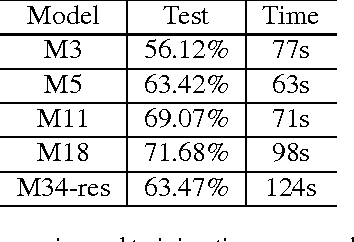
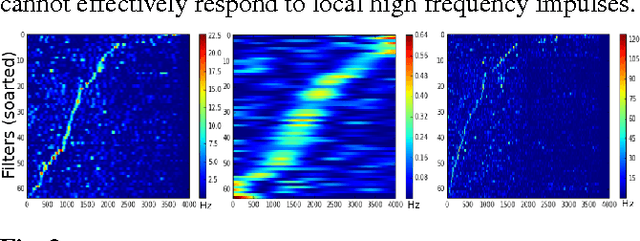
Learning acoustic models directly from the raw waveform data with minimal processing is challenging. Current waveform-based models have generally used very few (~2) convolutional layers, which might be insufficient for building high-level discriminative features. In this work, we propose very deep convolutional neural networks (CNNs) that directly use time-domain waveforms as inputs. Our CNNs, with up to 34 weight layers, are efficient to optimize over very long sequences (e.g., vector of size 32000), necessary for processing acoustic waveforms. This is achieved through batch normalization, residual learning, and a careful design of down-sampling in the initial layers. Our networks are fully convolutional, without the use of fully connected layers and dropout, to maximize representation learning. We use a large receptive field in the first convolutional layer to mimic bandpass filters, but very small receptive fields subsequently to control the model capacity. We demonstrate the performance gains with the deeper models. Our evaluation shows that the CNN with 18 weight layers outperform the CNN with 3 weight layers by over 15% in absolute accuracy for an environmental sound recognition task and matches the performance of models using log-mel features.