 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Wasserstein Barycenters for Time-series Modeling
Oct 29, 2021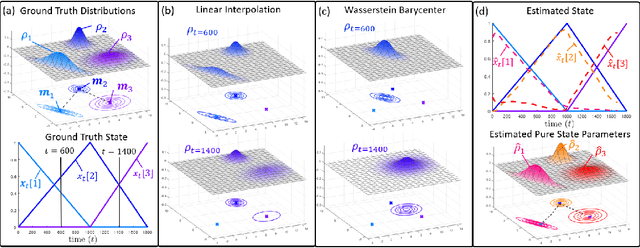
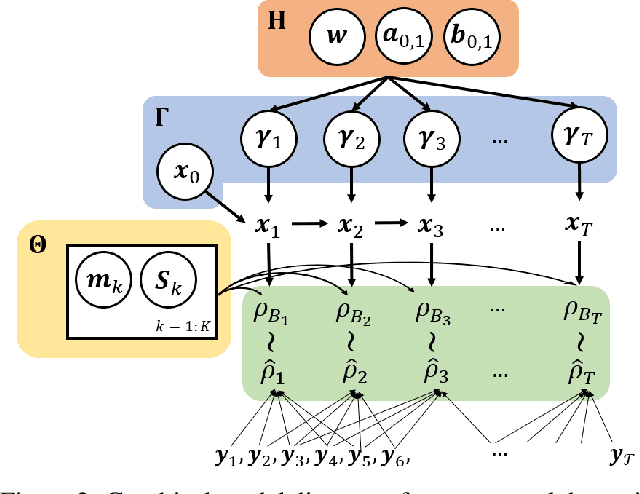
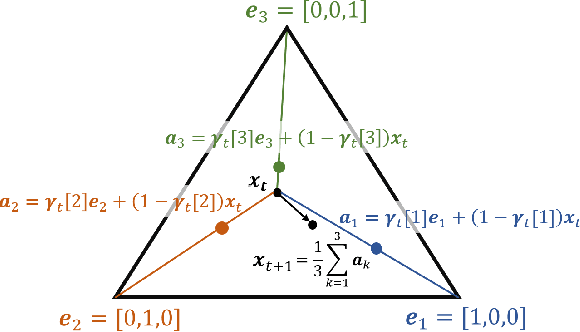
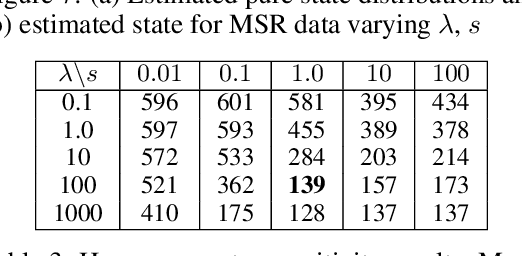
Many time series can be modeled as a sequence of segments representing high-level discrete states, such as running and walking in a human activity application. Flexible models should describe the system state and observations in stationary "pure-state" periods as well as transition periods between adjacent segments, such as a gradual slowdown between running and walking. However, most prior work assumes instantaneous transitions between pure discrete states. We propose a dynamical Wasserstein barycentric (DWB) model that estimates the system state over time as well as the data-generating distributions of pure states in an unsupervised manner. Our model assumes each pure state generates data from a multivariate normal distribution, and characterizes transitions between states via displacement-interpolation specified by the Wasserstein barycenter. The system state is represented by a barycentric weight vector which evolves over time via a random walk on the simplex. Parameter learning leverages the natural Riemannian geometry of Gaussian distributions under the Wasserstein distance, which leads to improved convergence speeds. Experiments on several human activity datasets show that our proposed DWB model accurately learns the generating distribution of pure states while improving state estimation for transition periods compared to the commonly used linear interpolation mixture models.
Barycenteric distribution alignment and manifold-restricted invertibility for domain generalization
Sep 04, 2021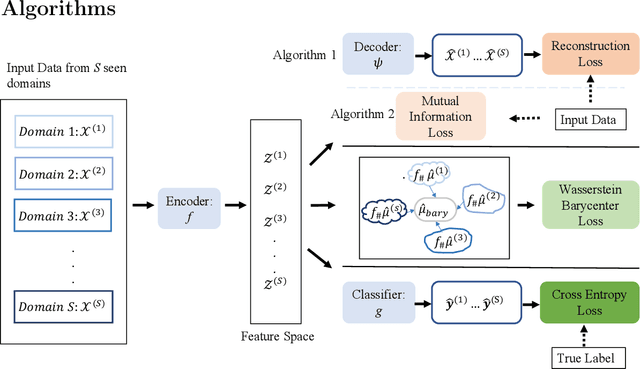
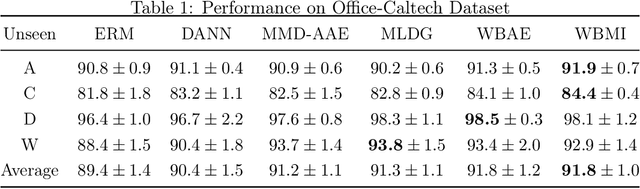
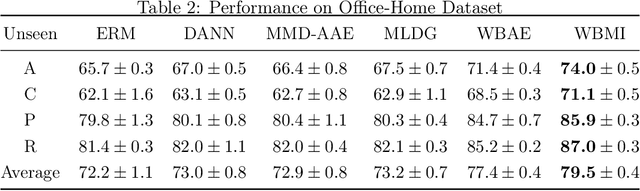
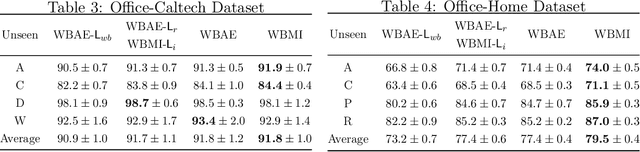
For the Domain Generalization (DG) problem where the hypotheses are composed of a common representation function followed by a labeling function, we point out a shortcoming in existing approaches that fail to explicitly optimize for a term, appearing in a well-known and widely adopted upper bound to the risk on the unseen domain, that is dependent on the representation to be learned. To this end, we first derive a novel upper bound to the prediction risk. We show that imposing a mild assumption on the representation to be learned, namely manifold restricted invertibility, is sufficient to deal with this issue. Further, unlike existing approaches, our novel upper bound doesn't require the assumption of Lipschitzness of the loss function. In addition, the distributional discrepancy in the representation space is handled via the Wasserstein-2 barycenter cost. In this context, we creatively leverage old and recent transport inequalities, which link various optimal transport metrics, in particular the $L^1$ distance (also known as the total variation distance) and the Wasserstein-2 distances, with the Kullback-Liebler divergence. These analyses and insights motivate a new representation learning cost for DG that additively balances three competing objectives: 1) minimizing classification error across seen domains via cross-entropy, 2) enforcing domain-invariance in the representation space via the Wasserstein-2 barycenter cost, and 3) promoting non-degenerate, nearly-invertible representation via one of two mechanisms, viz., an autoencoder-based reconstruction loss or a mutual information loss. It is to be noted that the proposed algorithms completely bypass the use of any adversarial training mechanism that is typical of many current domain generalization approaches. Simulation results on several standard datasets demonstrate superior performance compared to several well-known DG algorithms.
Soft and subspace robust multivariate rank tests based on entropy regularized optimal transport
Mar 16, 2021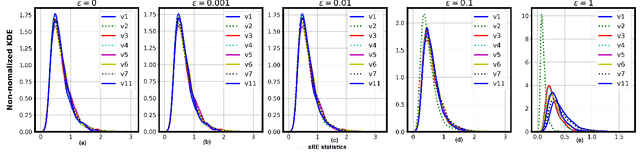
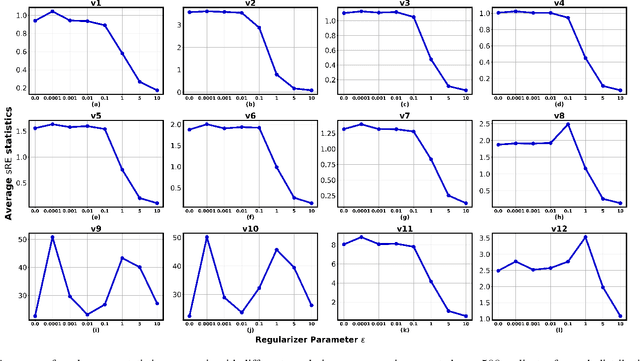
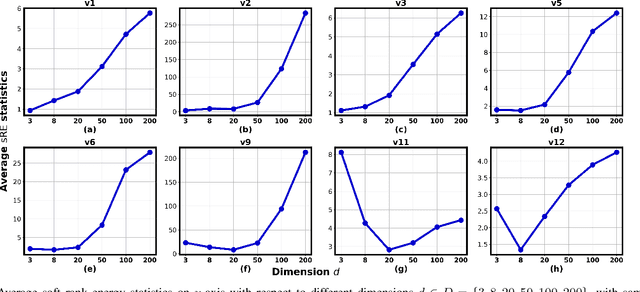
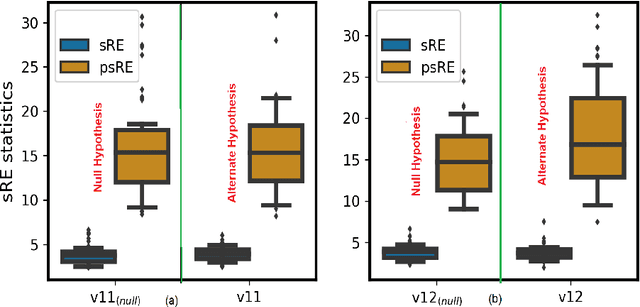
In this paper, we extend the recently proposed multivariate rank energy distance, based on the theory of optimal transport, for statistical testing of distributional similarity, to soft rank energy distance. Being differentiable, this in turn allows us to extend the rank energy to a subspace robust rank energy distance, dubbed Projected soft-Rank Energy distance, which can be computed via optimization over the Stiefel manifold. We show via experiments that using projected soft rank energy one can trade-off the detection power vs the false alarm via projections onto an appropriately selected low dimensional subspace. We also show the utility of the proposed tests on unsupervised change point detection in multivariate time series data. All codes are publicly available at the link provided in the experiment section.
Multiview Sensing With Unknown Permutations: An Optimal Transport Approach
Mar 12, 2021
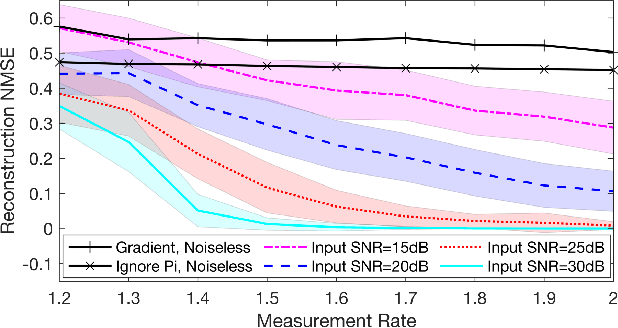
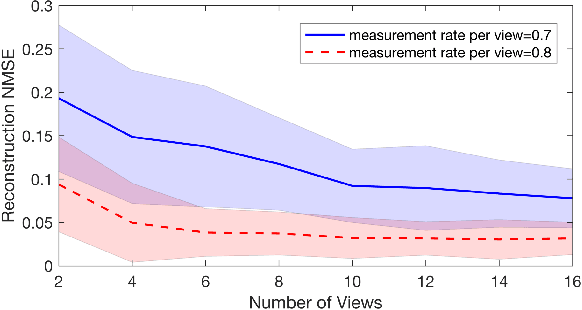
In several applications, including imaging of deformable objects while in motion, simultaneous localization and mapping, and unlabeled sensing, we encounter the problem of recovering a signal that is measured subject to unknown permutations. In this paper we take a fresh look at this problem through the lens of optimal transport (OT). In particular, we recognize that in most practical applications the unknown permutations are not arbitrary but some are more likely to occur than others. We exploit this by introducing a regularization function that promotes the more likely permutations in the solution. We show that, even though the general problem is not convex, an appropriate relaxation of the resulting regularized problem allows us to exploit the well-developed machinery of OT and develop a tractable algorithm.
Automatic coding of students' writing via Contrastive Representation Learning in the Wasserstein space
Dec 01, 2020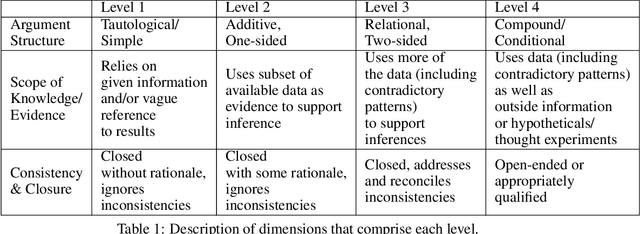

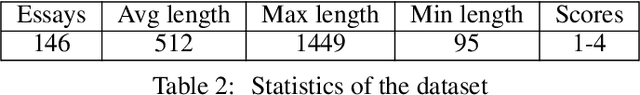
Qualitative analysis of verbal data is of central importance in the learning sciences. It is labor-intensive and time-consuming, however, which limits the amount of data researchers can include in studies. This work is a step towards building a statistical machine learning (ML) method for achieving an automated support for qualitative analyses of students' writing, here specifically in score laboratory reports in introductory biology for sophistication of argumentation and reasoning. We start with a set of lab reports from an undergraduate biology course, scored by a four-level scheme that considers the complexity of argument structure, the scope of evidence, and the care and nuance of conclusions. Using this set of labeled data, we show that a popular natural language modeling processing pipeline, namely vector representation of words, a.k.a word embeddings, followed by Long Short Term Memory (LSTM) model for capturing language generation as a state-space model, is able to quantitatively capture the scoring, with a high Quadratic Weighted Kappa (QWK) prediction score, when trained in via a novel contrastive learning set-up. We show that the ML algorithm approached the inter-rater reliability of human analysis. Ultimately, we conclude, that machine learning (ML) for natural language processing (NLP) holds promise for assisting learning sciences researchers in conducting qualitative studies at much larger scales than is currently possible.
Robust Machine Learning via Privacy/Rate-Distortion Theory
Jul 22, 2020

Robust machine learning formulations have emerged to address the prevalent vulnerability of deep neural networks to adversarial examples. Our work draws the connection between optimal robust learning and the privacy-utility tradeoff problem, which is a generalization of the rate-distortion problem. The saddle point of the game between a robust classifier and an adversarial perturbation can be found via the solution of a maximum conditional entropy problem. This information-theoretic perspective sheds light on the fundamental tradeoff between robustness and clean data performance, which ultimately arises from the geometric structure of the underlying data distribution and perturbation constraints. Further, we show that under mild conditions, the worst case adversarial distribution with Wasserstein-ball constraints on the perturbation has a fixed point characterization. This is obtained via the first order necessary conditions for optimality of the derived maximum conditional entropy problem. This fixed point characterization exposes the interplay between the geometry of the ground cost in the Wasserstein-ball constraint, the worst-case adversarial distribution, and the given reference data distribution.
Representation Learning via Adversarially-Contrastive Optimal Transport
Jul 11, 2020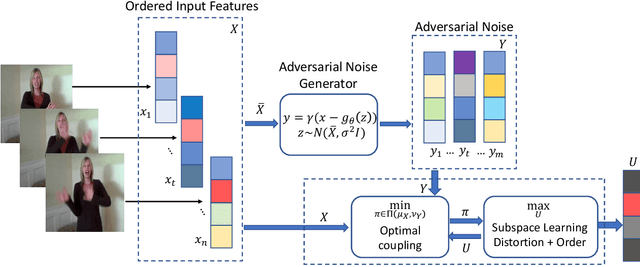
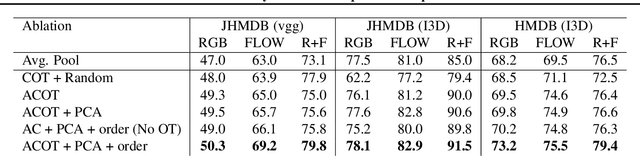
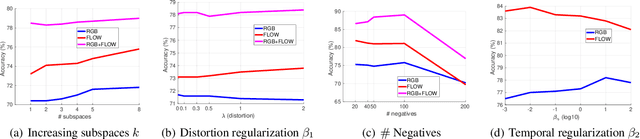
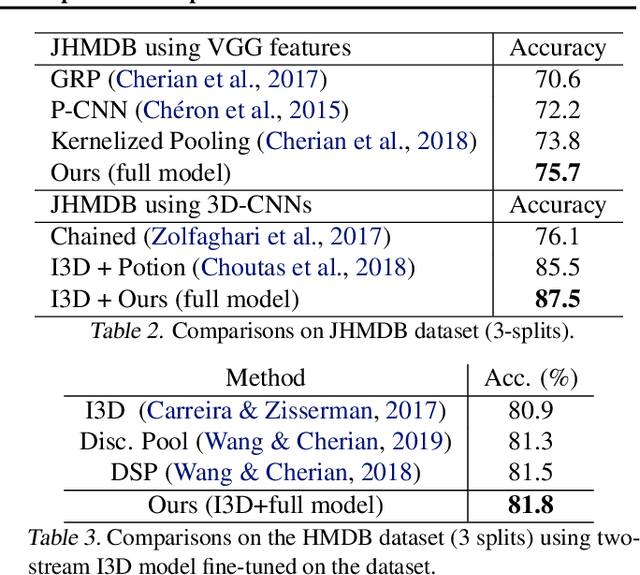
In this paper, we study the problem of learning compact (low-dimensional) representations for sequential data that captures its implicit spatio-temporal cues. To maximize extraction of such informative cues from the data, we set the problem within the context of contrastive representation learning and to that end propose a novel objective via optimal transport. Specifically, our formulation seeks a low-dimensional subspace representation of the data that jointly (i) maximizes the distance of the data (embedded in this subspace) from an adversarial data distribution under the optimal transport, a.k.a. the Wasserstein distance, (ii) captures the temporal order, and (iii) minimizes the data distortion. To generate the adversarial distribution, we propose a novel framework connecting Wasserstein GANs with a classifier, allowing a principled mechanism for producing good negative distributions for contrastive learning, which is currently a challenging problem. Our full objective is cast as a subspace learning problem on the Grassmann manifold and solved via Riemannian optimization. To empirically study our formulation, we provide experiments on the task of human action recognition in video sequences. Our results demonstrate competitive performance against challenging baselines.
Domain Adaptation for Robust Workload Classification using fNIRS
Jul 02, 2020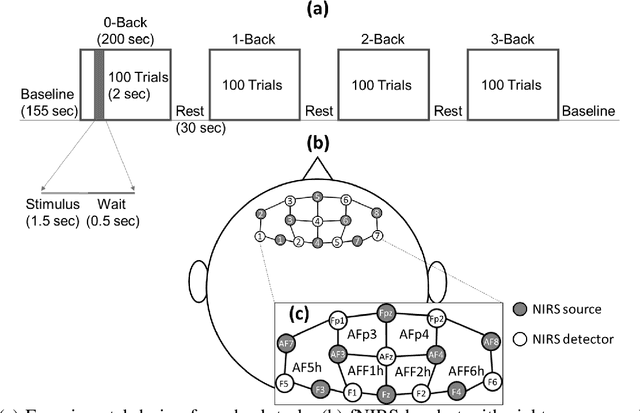
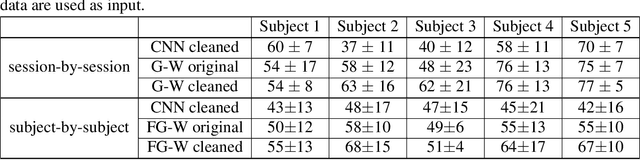
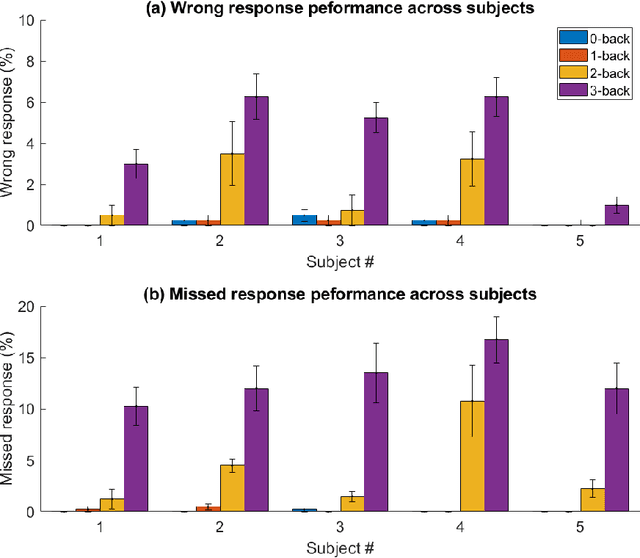
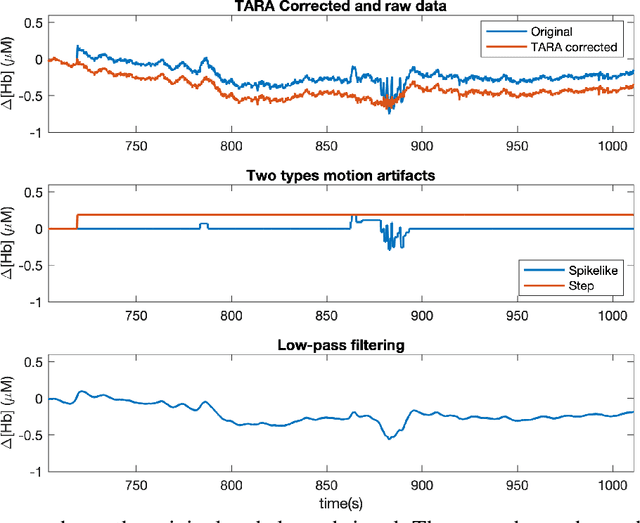
Significance: We demonstrated the potential of using domain adaptation on functional Near-Infrared Spectroscopy (fNIRS) data to detect and discriminate different levels of n-back tasks that involve working memory across different experiment sessions and subjects. Aim: To address the domain shift in fNIRS data across sessions and subjects for task label alignment, we exploited two domain adaptation approaches - Gromov-Wasserstein (G-W) and Fused Gromov-Wasserstein (FG-W). Approach: We applied G-W for session-by-session alignment and FG-W for subject-by-subject alignment with Hellinger distance as underlying metric to fNIRS data acquired during different n-back task levels. We also compared with a supervised method - Convolutional Neural Network (CNN). Results: For session-by-session alignment, using G-W resulted in alignment accuracy of 70 $\pm$ 4 % (weighted mean $\pm$ standard error), whereas using CNN resulted in classification accuracy of 58 $\pm$ 5 % across five subjects. For subject-by-subject alignment, using FG-W resulted in alignment accuracy of 55 $\pm$ 3 %, whereas using CNN resulted in classification accuracy of 45 $\pm$ 1 %. Where in both cases 25 % represents chance. We also showed that removal of motion artifacts from the fNIRS data plays an important role in improving alignment performance. Conclusions: Domain adaptation is potential for session-by-session and subject-by-subject alignment using fNIRS data.
On Matched Filtering for Statistical Change Point Detection
Jun 09, 2020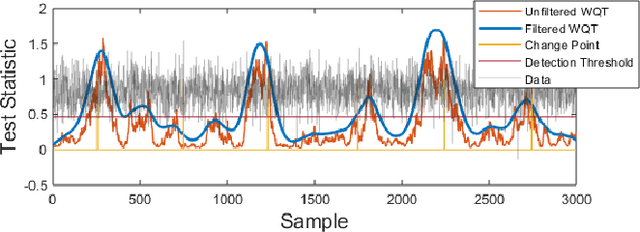
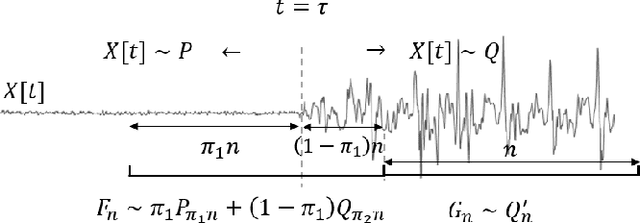
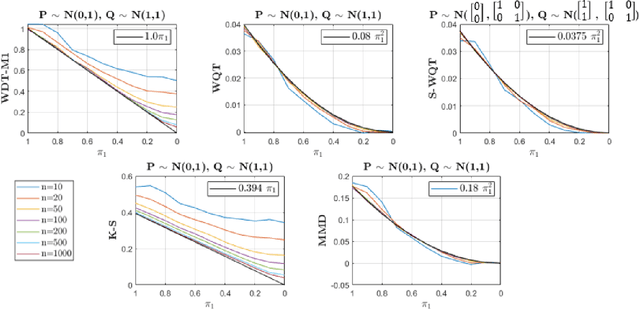
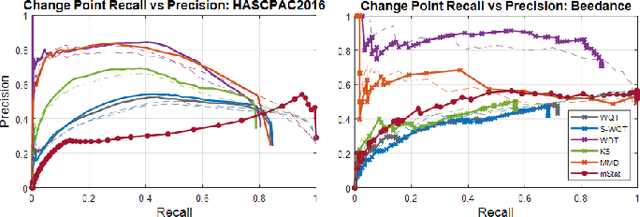
Non-parametric and distribution-free two-sample tests have been the foundation of many change point detection algorithms.However, noise in the data make these tests susceptible to false positives and localization ambiguity. We address these issues by deriving asymptotically matched filters under standard IID assumptions on the data for various sliding window two-sample tests.In particular, in this paper we focus on the Wasserstein quantile test, the Wasserstein-1 distance test, maximum mean discrepancy(MMD) test, and the Kolmogorov-Smirnov (KS) test. To the best of our knowledge this is the first time an matched filtering has been proposed and evaluated for these tests or for change point detection. While in this paper we only consider a subset of tests, the proposed methodology and analysis can be extended to other tests. Quite remarkably, this simple post processing turns out to be quite robust in terms of mitigating false positives and improving change point localization, thereby making these distribution-free tests practically useful. We demonstrate this through experiments on synthetic data as well as activity recognition benchmarks. We further highlight and contrast several properties such as sensitivity of these tests and compare their relative performance.
Optimal Transport Based Change Point Detection and Time Series Segment Clustering
Nov 04, 2019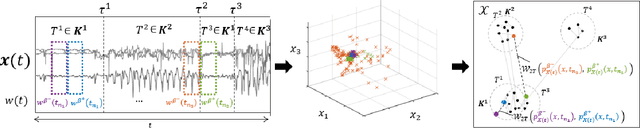
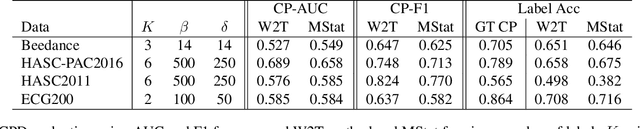


Two common problems in time series analysis are the decomposition of the data stream into disjoint segments, each of which is in some sense 'homogeneous' - a problem that is also referred to as Change Point Detection (CPD) - and the grouping of similar nonadjacent segments, or Time Series Segment Clustering (TSSC). Building upon recent theoretical advances characterizing the limiting distribution free behavior of the Wasserstein two-sample test, we propose a novel algorithm for unsupervised, distribution-free CPD, which is amenable to both offline and online settings. We also introduce a method to mitigate false positives in CPD, and address TSSC by using the Wasserstein distance between the detected segments to build an affinity matrix to which we apply spectral clustering. Results on both synthetic and real data sets show the benefits of the approach.