 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study of Cross-Lingual Zero-Shot Generalization for Classical Languages in LLMs
May 19, 2025Large Language Models (LLMs) have demonstrated remarkable generalization capabilities across diverse tasks and languages. In this study, we focus on natural language understanding in three classical languages -- Sanskrit, Ancient Greek and Latin -- to investigate the factors affecting cross-lingual zero-shot generalization. First, we explore named entity recognition and machine translation into English. While LLMs perform equal to or better than fine-tuned baselines on out-of-domain data, smaller models often struggle, especially with niche or abstract entity types. In addition, we concentrate on Sanskrit by presenting a factoid question-answering (QA) dataset and show that incorporating context via retrieval-augmented generation approach significantly boosts performance. In contrast, we observe pronounced performance drops for smaller LLMs across these QA tasks. These results suggest model scale as an important factor influencing cross-lingual generalization. Assuming that models used such as GPT-4o and Llama-3.1 are not instruction fine-tuned on classical languages, our findings provide insights into how LLMs may generalize on these languages and their consequent utility in classical studies.
GraphReach: Position-Aware Graph Neural Networks using Reachability Estimations
Sep 21, 2020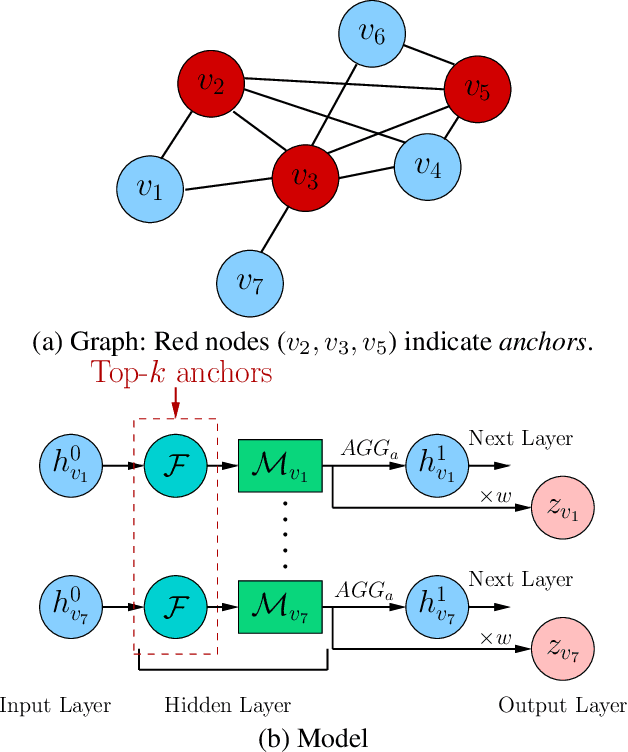
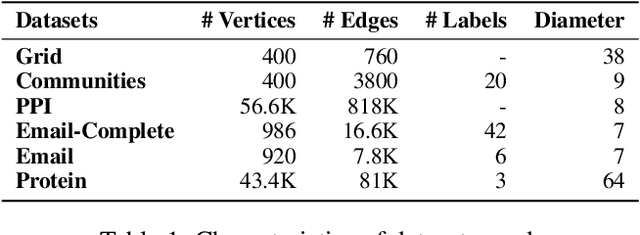
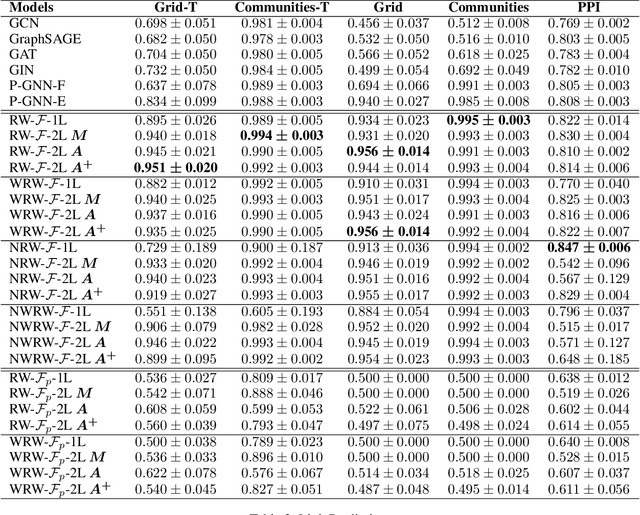
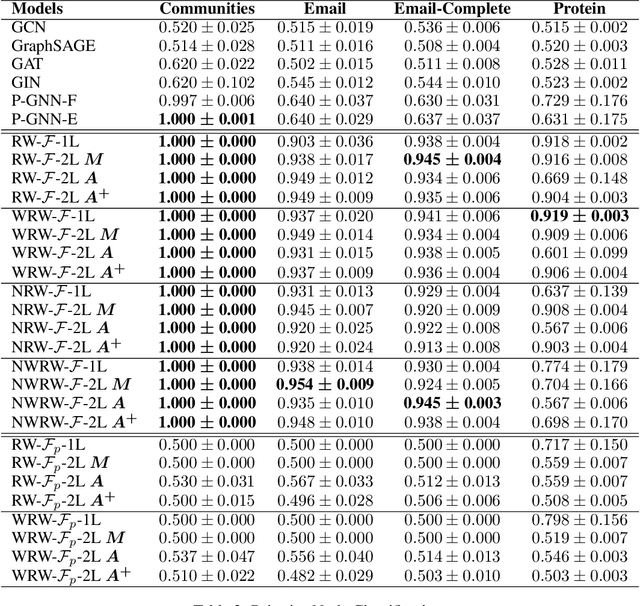
Learning feature space node embeddings that encode the position of a node within the context of a graph is useful in several graph prediction tasks. Majority of the existing graph neural networks (GNN) learn node embeddings that encode their local neighborhoods but not their positions. Consequently, two nodes that are vastly distant but located in similar local neighborhoods would map to similar embeddings. This limitation may prevent accurate performance in predictive tasks that rely on position information. In this paper, we address this gap by developing GraphReach, a position-aware, inductive GNN. GraphReach captures the global positions of nodes though reachability estimations with respect to a set of nodes called anchors. The reachability estimations compute the frequency with which a node may visit an anchor through any possible path. The anchors are strategically selected so that the reachability estimations across all nodes are maximized. We show that this combinatorial anchor selection problem is NP-hard and consequently, develop a greedy (1-1/e) approximation. An extensive experimental evaluation covering six datasets and five state-of-the-art GNN architectures reveal that GraphReach is consistently superior and provides up to 40% relative improvement in the predictive tasks of link prediction and pairwise node classification. In addition, GraphReach is more robust against adversarial attacks.