 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Validated LBM Dataset and Pipeline for Surrogate Modeling of Turbulent 3D Obstructed Channel Flows
Jun 15, 2026Evaluating neural operators for 3D turbulent flow requires validated datasets with physical benchmarks. We present a reproducible pipeline generating training data for 3D channel flows around generated geometries at Re=1,000-10,000. Our lattice Boltzmann solver with cumulant collision operators is rigorously verified against experimental measurements (Strouhal number, drag coefficients, turbulent fluctuations) with comprehensive grid convergence studies at resolution 1024x512x512. Building upon an established framework, this validated pipeline enables standardized surrogate model comparison. We outline planned systematic evaluation of Fourier Neural Operator and U-Net variants on forecasting, super-resolution, and error correction tasks, using physics-informed metrics to assess turbulent energy cascade representation. Future work will compare computational efficiency between numerical solvers and neural surrogates, exploring practical application. We seek community feedback on our validation approach, planned benchmark methodology, and evaluation priorities for neural operators in turbulent flows.
ChannelFlow-Tools: A Standardized Dataset Creation Pipeline for 3D Obstructed Channel Flows
Sep 17, 2025
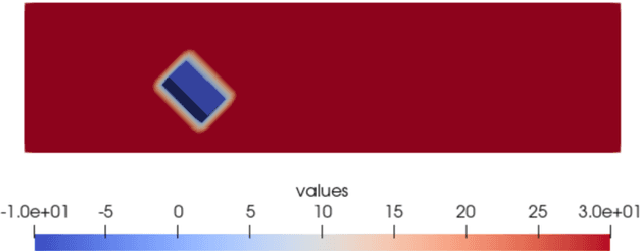


We present ChannelFlow-Tools, a configuration-driven framework that standardizes the end-to-end path from programmatic CAD solid generation to ML-ready inputs and targets for 3D obstructed channel flows. The toolchain integrates geometry synthesis with feasibility checks, signed distance field (SDF) voxelization, automated solver orchestration on HPC (waLBerla LBM), and Cartesian resampling to co-registered multi-resolution tensors. A single Hydra/OmegaConf configuration governs all stages, enabling deterministic reproduction and controlled ablations. As a case study, we generate 10k+ scenes spanning Re=100-15000 with diverse shapes and poses. An end-to-end evaluation of storage trade-offs directly from the emitted artifacts, a minimal 3D U-Net at 128x32x32, and example surrogate models with dataset size illustrate that the standardized representations support reproducible ML training. ChannelFlow-Tools turns one-off dataset creation into a reproducible, configurable pipeline for CFD surrogate modeling.
Dynamically Weighted Federated k-Means
Oct 23, 2023Federated clustering is an important part of the field of federated machine learning, that allows multiple data sources to collaboratively cluster their data while keeping it decentralized and preserving privacy. In this paper, we introduce a novel federated clustering algorithm, named Dynamically Weighted Federated k-means (DWF k-means), to address the challenges posed by distributed data sources and heterogeneous data. Our proposed algorithm combines the benefits of traditional clustering techniques with the privacy and scalability advantages of federated learning. It enables multiple data owners to collaboratively cluster their local data while exchanging minimal information with a central coordinator. The algorithm optimizes the clustering process by adaptively aggregating cluster assignments and centroids from each data source, thereby learning a global clustering solution that reflects the collective knowledge of the entire federated network. We conduct experiments on multiple datasets and data distribution settings to evaluate the performance of our algorithm in terms of clustering score, accuracy, and v-measure. The results demonstrate that our approach can match the performance of the centralized classical k-means baseline, and outperform existing federated clustering methods in realistic scenarios.