 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization using Causal Matching
Jun 12, 2020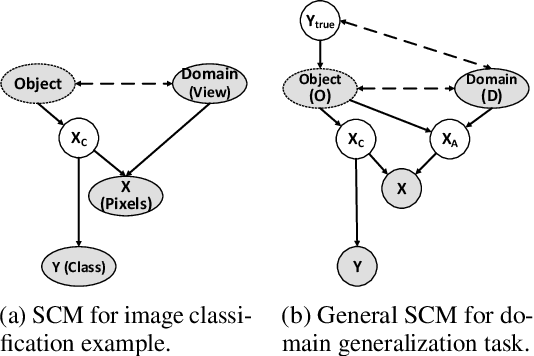
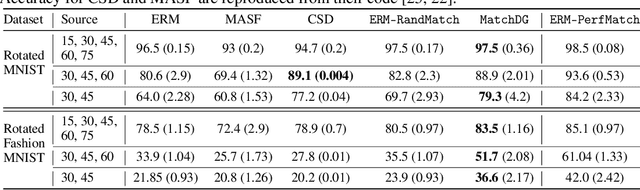
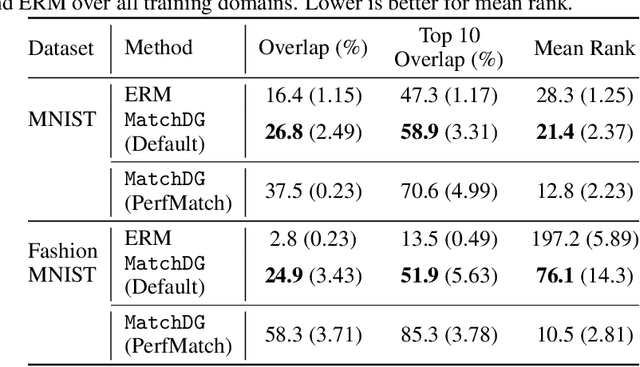
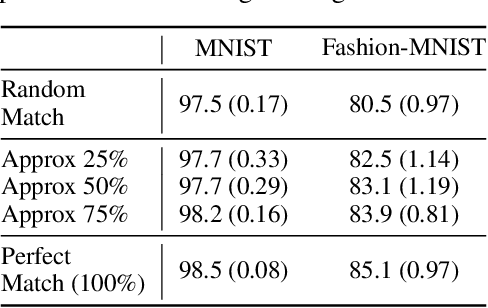
Learning invariant representations has been proposed as a key technique for addressing the domain generalization problem. However, the question of identifying the right conditions for invariance remains unanswered. In this work, we propose a causal interpretation of domain generalization that defines domains as interventions under a data-generating process. Based on a general causal model for data from multiple domains, we show that prior methods for learning an invariant representation optimize for an incorrect objective. We highlight an alternative condition: inputs across domains should have the same representation if they are derived from the same base object. In practice, knowledge about generation of data or objects is not available. Hence we propose an iterative algorithm called MatchDG that approximates base object similarity by using a contrastive loss formulation adapted for multiple domains. We then match inputs that are similar under the resultant representation to build an invariant classifier. We evaluate MatchDG on rotated MNIST, Fashion-MNIST, and PACS datasets and find that it outperforms prior work on out-of-domain accuracy and learns matches that have over 25\% overlap with ground-truth object matches in MNIST and Fashion-MNIST. Code repository can be accessed here: \textit{https://github.com/microsoft/robustdg}
Dataset-Level Attribute Leakage in Collaborative Learning
Jun 12, 2020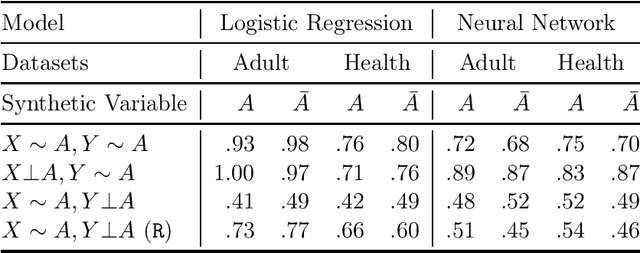
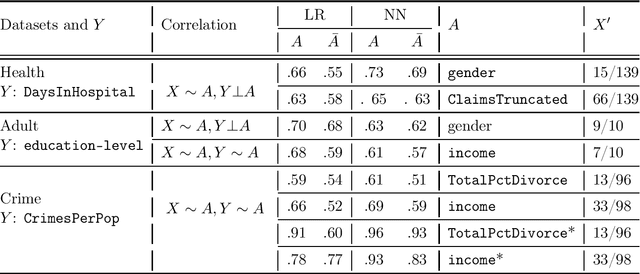
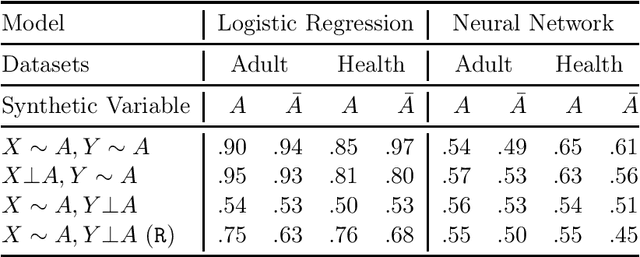
Multi-party machine learning allows several parties to build a joint model to get insights that may not be learnable using only their local data. We consider settings where each party obtains black-box access to the model computed by their mutually agreed-upon algorithm on their joined data. We show that such multi-party computation can cause information leakage between the parties. In particular, a "curious" party can infer the distribution of sensitive attributes in other parties' data with high accuracy. In order to understand and measure the source of leakage, we consider several models of correlation between a sensitive attribute and the rest of the data. Using multiple datasets and machine learning models, we show that leakage occurs even if the sensitive attribute is not included in the training data and has a low correlation with other attributes and the target variable.
FALCON: Honest-Majority Maliciously Secure Framework for Private Deep Learning
Apr 05, 2020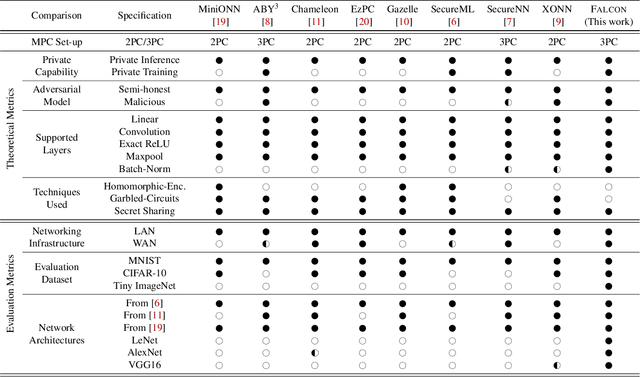


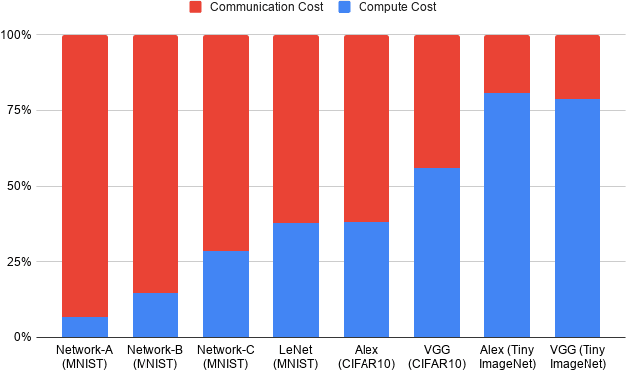
This paper aims to enable training and inference of neural networks in a manner that protects the privacy of sensitive data. We propose FALCON - an end-to-end 3-party protocol for fast and secure computation of deep learning algorithms on large networks. FALCON presents three main advantages. It is highly expressive. To the best of our knowledge, it is the first secure framework to support high capacity networks with over a hundred million parameters such as VGG16 as well as the first to support batch normalization, a critical component of deep learning that enables training of complex network architectures such as AlexNet. Next, FALCON guarantees security with abort against malicious adversaries, assuming an honest majority. It ensures that the protocol always completes with correct output for honest participants or aborts when it detects the presence of a malicious adversary. Lastly, FALCON presents new theoretical insights for protocol design that make it highly efficient and allow it to outperform existing secure deep learning solutions. Compared to prior art for private inference, we are about 8x faster than SecureNN (PETS '19) on average and comparable to ABY3 (CCS '18). We are about 16-200x more communication efficient than either of these. For private training, we are about 6x faster than SecureNN, 4.4x faster than ABY3 and about 2-60x more communication efficient. This is the first paper to show via experiments in the WAN setting, that for multi-party machine learning computations over large networks and datasets, compute operations dominate the overall latency, as opposed to the communication.
Analyzing Privacy Loss in Updates of Natural Language Models
Jan 14, 2020
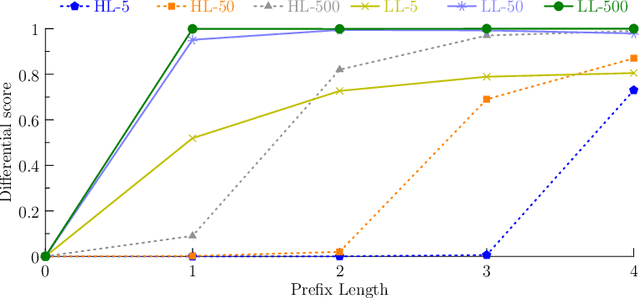
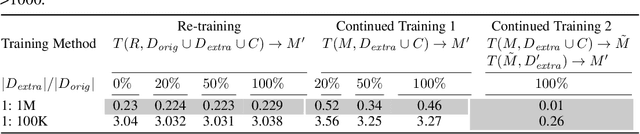
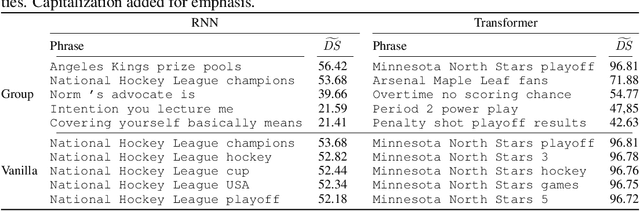
To continuously improve quality and reflect changes in data, machine learning-based services have to regularly re-train and update their core models. In the setting of language models, we show that a comparative analysis of model snapshots before and after an update can reveal a surprising amount of detailed information about the changes in the data used for training before and after the update. We discuss the privacy implications of our findings, propose mitigation strategies and evaluate their effect.
To Transfer or Not to Transfer: Misclassification Attacks Against Transfer Learned Text Classifiers
Jan 08, 2020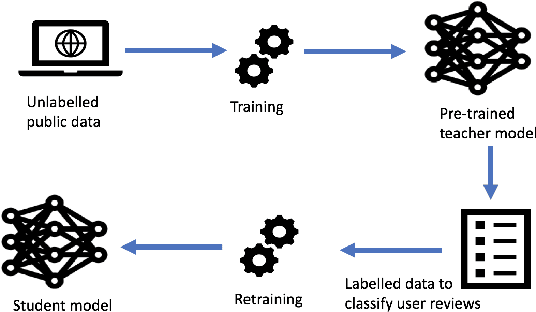
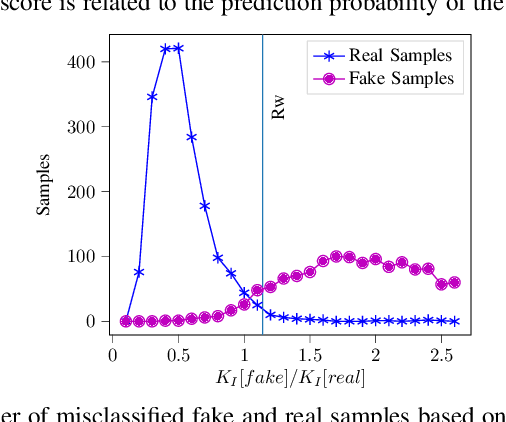
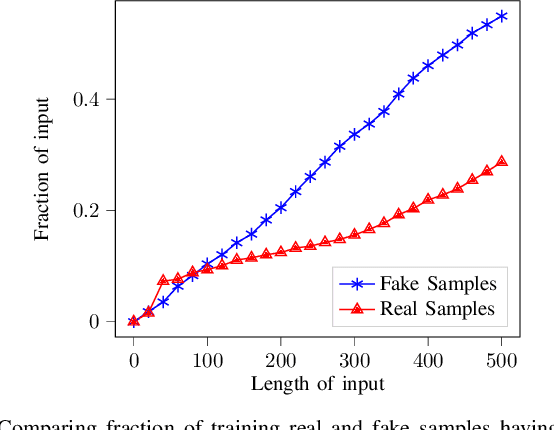
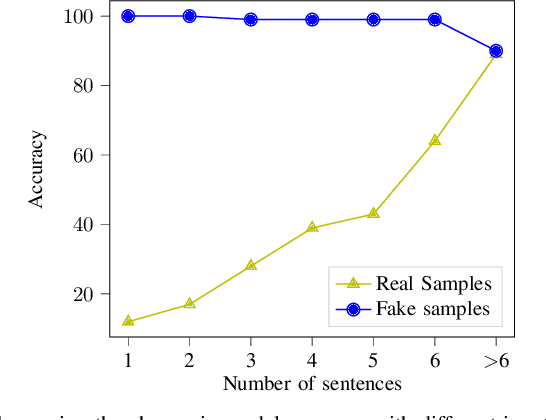
Transfer learning --- transferring learned knowledge --- has brought a paradigm shift in the way models are trained. The lucrative benefits of improved accuracy and reduced training time have shown promise in training models with constrained computational resources and fewer training samples. Specifically, publicly available text-based models such as GloVe and BERT that are trained on large corpus of datasets have seen ubiquitous adoption in practice. In this paper, we ask, "can transfer learning in text prediction models be exploited to perform misclassification attacks?" As our main contribution, we present novel attack techniques that utilize unintended features learnt in the teacher (public) model to generate adversarial examples for student (downstream) models. To the best of our knowledge, ours is the first work to show that transfer learning from state-of-the-art word-based and sentence-based teacher models increase the susceptibility of student models to misclassification attacks. First, we propose a novel word-score based attack algorithm for generating adversarial examples against student models trained using context-free word-level embedding model. On binary classification tasks trained using the GloVe teacher model, we achieve an average attack accuracy of 97% for the IMDB Movie Reviews and 80% for the Fake News Detection. For multi-class tasks, we divide the Newsgroup dataset into 6 and 20 classes and achieve an average attack accuracy of 75% and 41% respectively. Next, we present length-based and sentence-based misclassification attacks for the Fake News Detection task trained using a context-aware BERT model and achieve 78% and 39% attack accuracy respectively. Thus, our results motivate the need for designing training techniques that are robust to unintended feature learning, specifically for transfer learned models.
On the Intrinsic Privacy of Stochastic Gradient Descent
Dec 05, 2019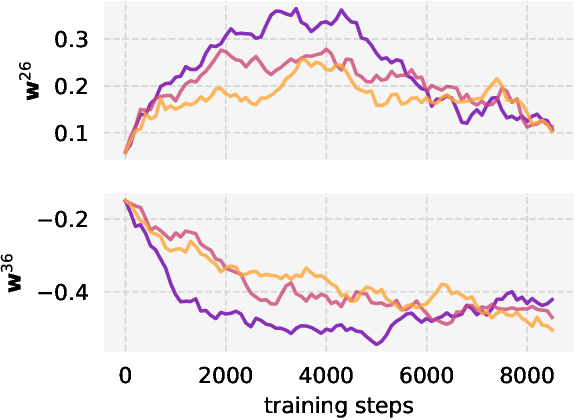
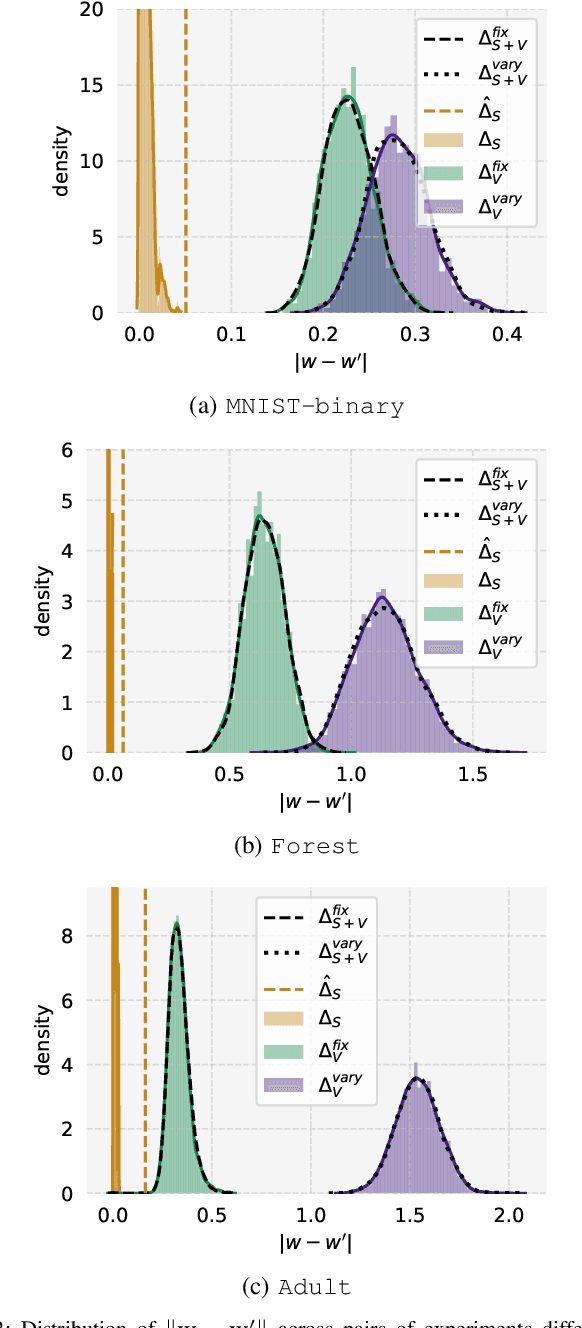
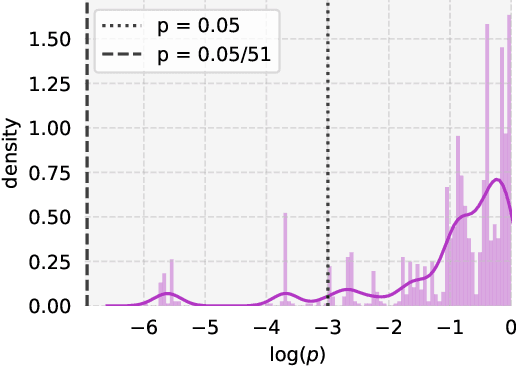
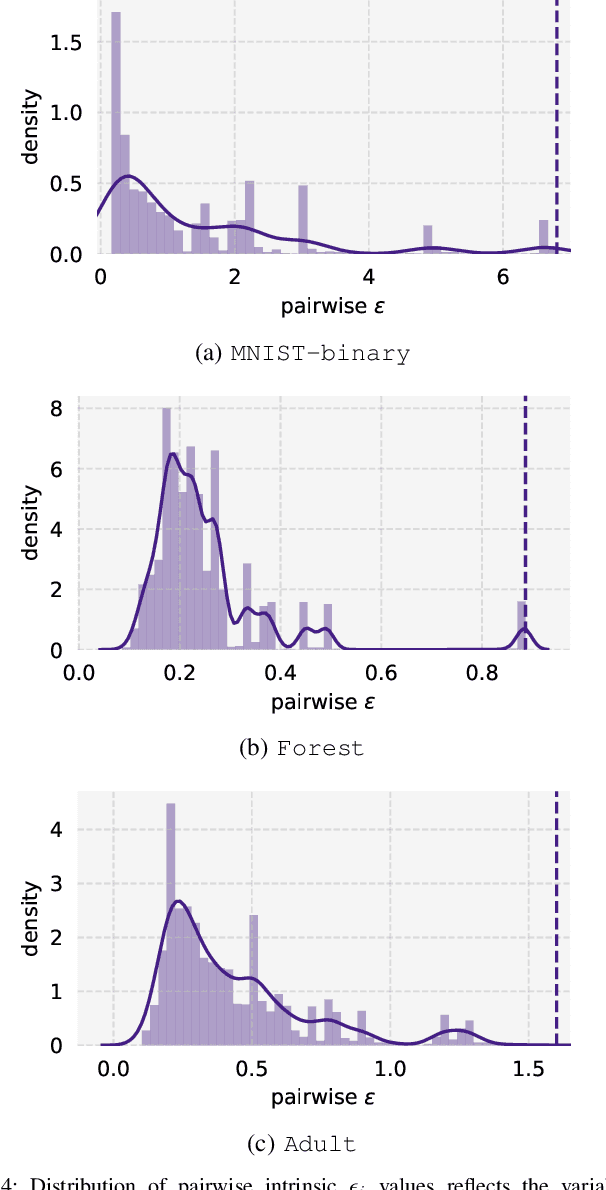
Private learning algorithms have been proposed that ensure strong differential-privacy (DP) guarantees, however they often come at a cost to utility. Meanwhile, stochastic gradient descent (SGD) contains intrinsic randomness which has not been leveraged for privacy. In this work, we take the first step towards analysing the intrinsic privacy properties of SGD. Our primary contribution is a large-scale empirical analysis of SGD on convex and non-convex objectives. We evaluate the inherent variability due to the stochasticity in SGD on 3 datasets and calculate the $\epsilon$ values due to the intrinsic noise. First, we show that the variability in model parameters due to the random sampling almost always exceeds that due to changes in the data. We observe that SGD provides intrinsic $\epsilon$ values of 7.8, 6.9, and 2.8 on MNIST, Adult, and Forest Covertype datasets respectively. Next, we propose a method to augment the intrinsic noise of SGD to achieve the desired $\epsilon$. Our augmented SGD outputs models that outperform existing approaches with the same privacy guarantee, closing the gap to noiseless utility between 0.19% and 10.07%. Finally, we show that the existing theoretical bound on the sensitivity of SGD is not tight. By estimating the tightest bound empirically, we achieve near-noiseless performance at $\epsilon = 1$, closing the utility gap to the noiseless model between 3.13% and 100%. Our experiments provide concrete evidence that changing the seed in SGD is likely to have a far greater impact on the model than excluding any given training example. By accounting for this intrinsic randomness, higher utility can be achieved without sacrificing further privacy. With these results, we hope to inspire the research community to further explore and characterise the randomness in SGD, its impact on privacy, and the parallels with generalisation in machine learning.
Collaborative Machine Learning Markets with Data-Replication-Robust Payments
Nov 08, 2019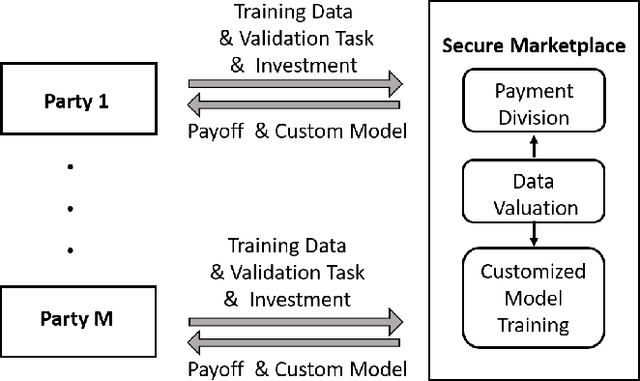
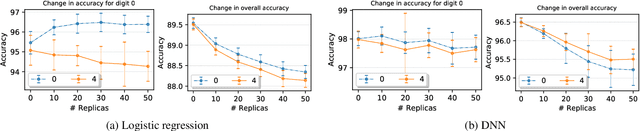
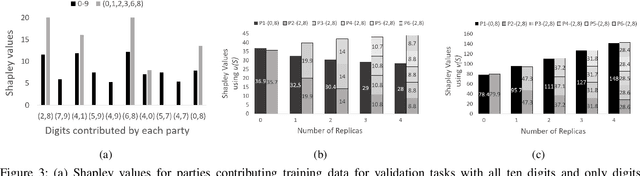
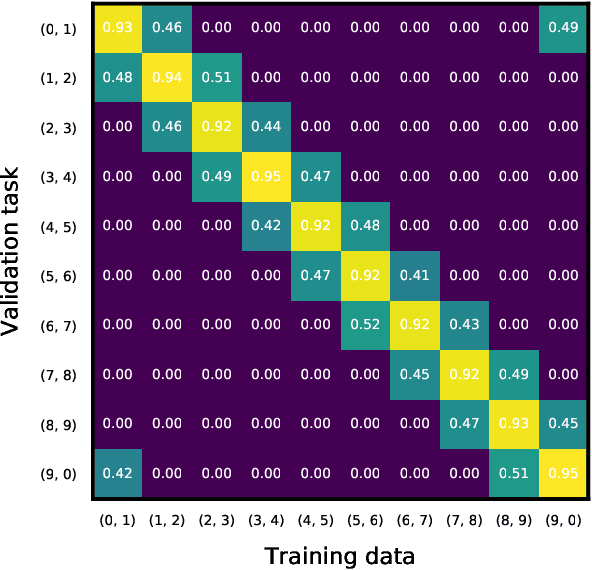
We study the problem of collaborative machine learning markets where multiple parties can achieve improved performance on their machine learning tasks by combining their training data. We discuss desired properties for these machine learning markets in terms of fair revenue distribution and potential threats, including data replication. We then instantiate a collaborative market for cases where parties share a common machine learning task and where parties' tasks are different. Our marketplace incentivizes parties to submit high quality training and true validation data. To this end, we introduce a novel payment division function that is robust-to-replication and customized output models that perform well only on requested machine learning tasks. In experiments, we validate the assumptions underlying our theoretical analysis and show that these are approximately satisfied for commonly used machine learning models.
Alleviating Privacy Attacks via Causal Learning
Sep 27, 2019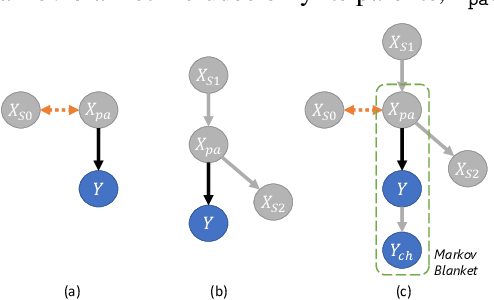
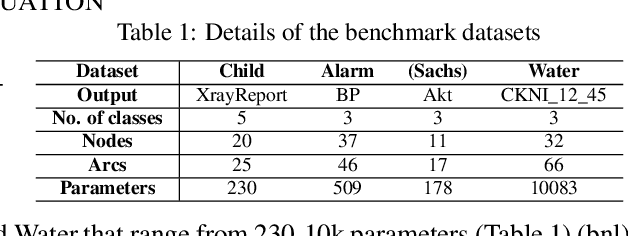
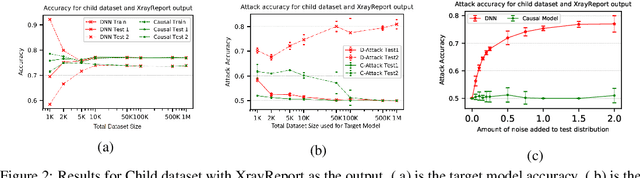
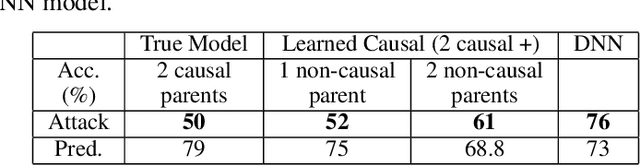
Machine learning models, especially deep neural networks have been shown to reveal membership information of inputs in the training data. Such membership inference attacks are a serious privacy concern, for example, patients providing medical records to build a model that detects HIV would not want their identity to be leaked. Further, we show that the attack accuracy amplifies when the model is used to predict samples that come from a different distribution than the training set, which is often the case in real world applications. Therefore, we propose the use of causal learning approaches where a model learns the causal relationship between the input features and the outcome. Causal models are known to be invariant to the training distribution and hence generalize well to shifts between samples from the same distribution and across different distributions. First, we prove that models learned using causal structure provide stronger differential privacy guarantees than associational models under reasonable assumptions. Next, we show that causal models trained on sufficiently large samples are robust to membership inference attacks across different distributions of datasets and those trained on smaller sample sizes always have lower attack accuracy than corresponding associational models. Finally, we confirm our theoretical claims with experimental evaluation on $4$ datasets with moderately complex Bayesian networks. We observe that neural network-based associational models exhibit up to 80% attack accuracy under different test distributions and sample sizes whereas causal models exhibit attack accuracy close to a random guess. Our results confirm the value of the generalizability of causal models in reducing susceptibility to privacy attacks.
Privado: Practical and Secure DNN Inference
Oct 01, 2018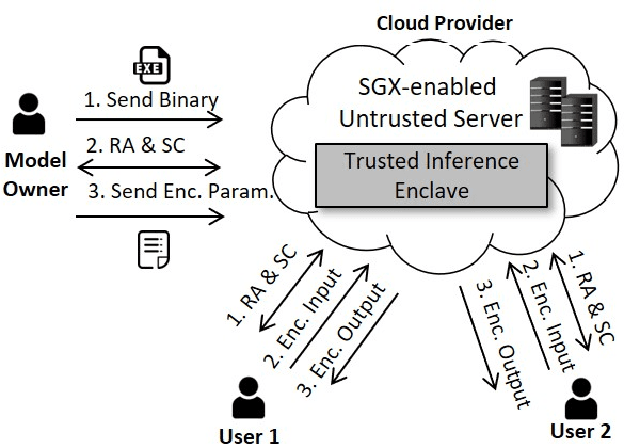
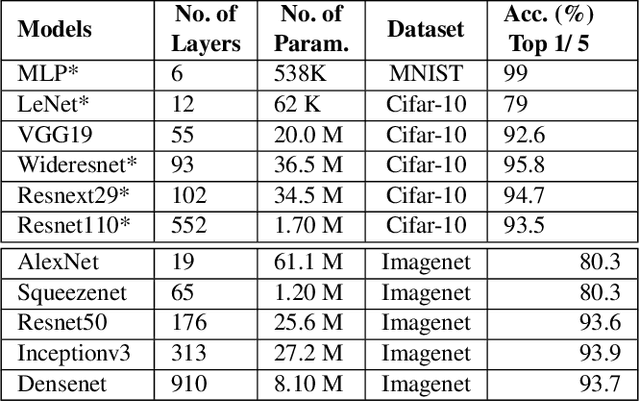
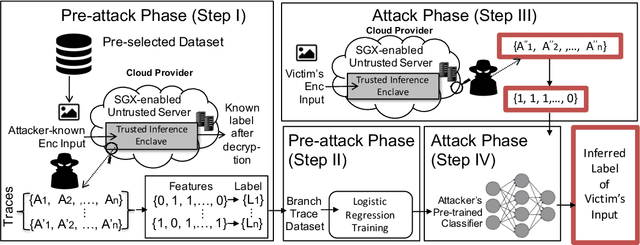
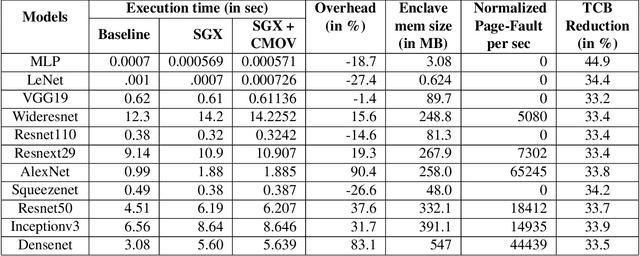
Recently, cloud providers have extended support for trusted hardware primitives such as Intel SGX. Simultaneously, the field of deep learning is seeing enormous innovation and increase in adoption. In this paper, we therefore ask the question: "Can third-party cloud services use SGX to provide practical, yet secure DNN Inference-as-a-service? " Our work addresses the three main challenges that SGX-based DNN inferencing faces, namely, security, ease-of-use, and performance. We first demonstrate that side-channel based attacks on DNN models are indeed possible. We show that, by observing access patterns, we can recover inputs to the DNN model. This motivates the need for Privado, a system we have designed for secure inference-as-a-service. Privado is input-oblivious: it transforms any deep learning framework written in C/C++ to be free of input-dependent access patterns. Privado is fully-automated and has a low TCB: with zero developer effort, given an ONNX description, it generates compact C code for the model which can run within SGX-enclaves. Privado has low performance overhead: we have used Privado with Torch, and have shown its overhead to be 20.77\% on average on 10 contemporary networks.