 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Convolutional Representations for On-Device Natural Language Processing
Feb 04, 2020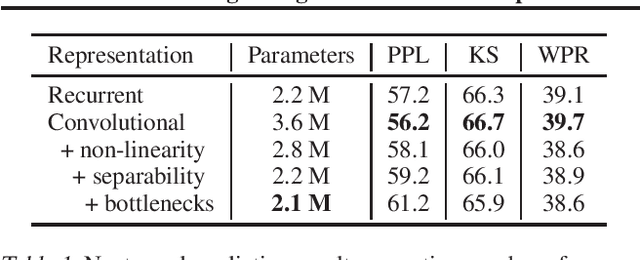
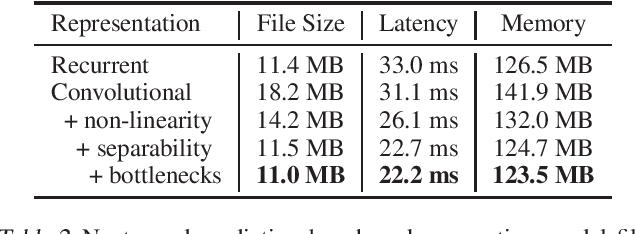
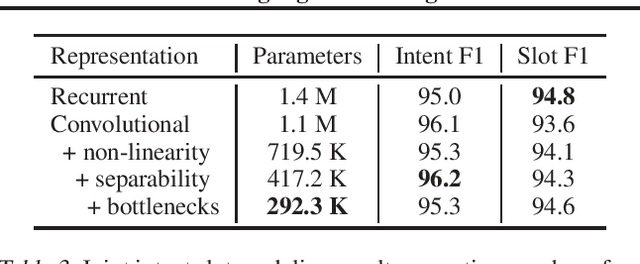
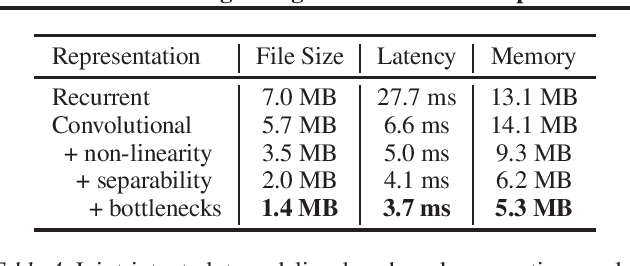
The increasing computational and memory complexities of deep neural networks have made it difficult to deploy them on low-resource electronic devices (e.g., mobile phones, tablets, wearables). Practitioners have developed numerous model compression methods to address these concerns, but few have condensed input representations themselves. In this work, we propose a fast, accurate, and lightweight convolutional representation that can be swapped into any neural model and compressed significantly (up to 32x) with a negligible reduction in performance. In addition, we show gains over recurrent representations when considering resource-centric metrics (e.g., model file size, latency, memory usage) on a Samsung Galaxy S9.
Evaluating Lottery Tickets Under Distributional Shifts
Oct 28, 2019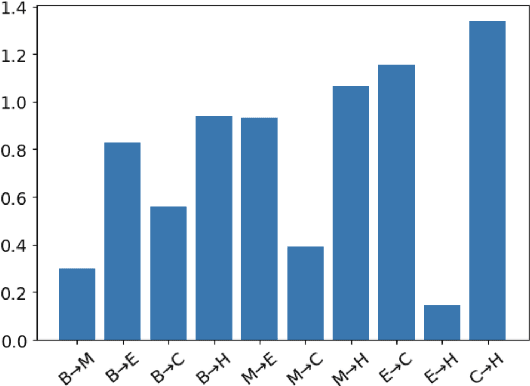
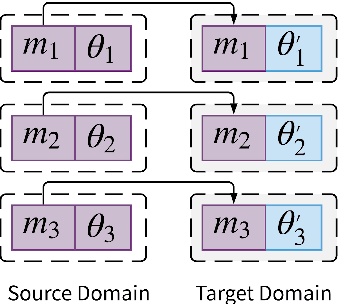
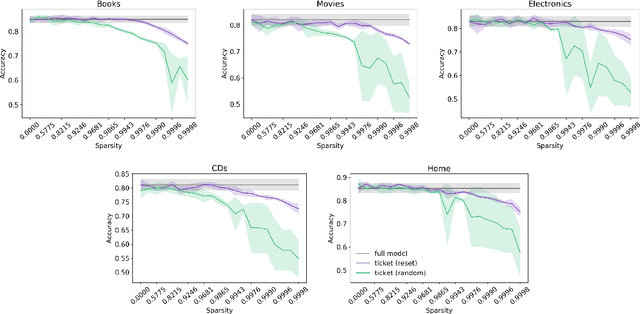
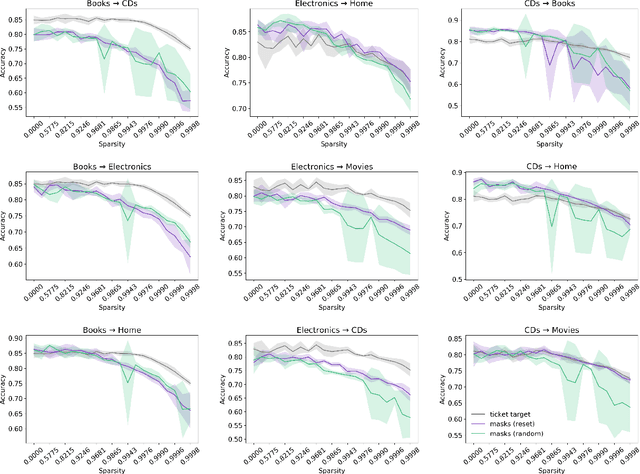
The Lottery Ticket Hypothesis suggests large, over-parameterized neural networks consist of small, sparse subnetworks that can be trained in isolation to reach a similar (or better) test accuracy. However, the initialization and generalizability of the obtained sparse subnetworks have been recently called into question. Our work focuses on evaluating the initialization of sparse subnetworks under distributional shifts. Specifically, we investigate the extent to which a sparse subnetwork obtained in a source domain can be re-trained in isolation in a dissimilar, target domain. In addition, we examine the effects of different initialization strategies at transfer-time. Our experiments show that sparse subnetworks obtained through lottery ticket training do not simply overfit to particular domains, but rather reflect an inductive bias of deep neural networks that can be exploited in multiple domains.
Adaptive Ensembling: Unsupervised Domain Adaptation for Political Document Analysis
Oct 28, 2019
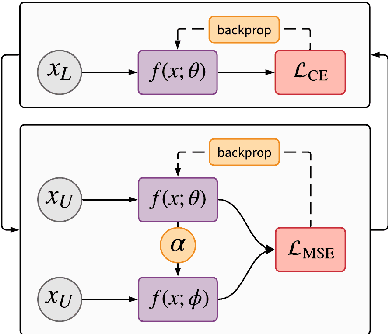
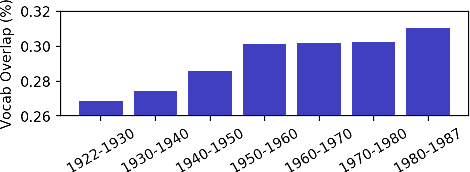
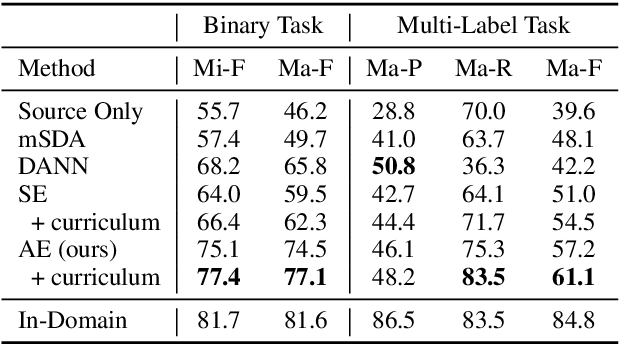
Insightful findings in political science often require researchers to analyze documents of a certain subject or type, yet these documents are usually contained in large corpora that do not distinguish between pertinent and non-pertinent documents. In contrast, we can find corpora that label relevant documents but have limitations (e.g., from a single source or era), preventing their use for political science research. To bridge this gap, we present \textit{adaptive ensembling}, an unsupervised domain adaptation framework, equipped with a novel text classification model and time-aware training to ensure our methods work well with diachronic corpora. Experiments on an expert-annotated dataset show that our framework outperforms strong benchmarks. Further analysis indicates that our methods are more stable, learn better representations, and extract cleaner corpora for fine-grained analysis.