 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisson Kernel Avoiding Self-Smoothing in Graph Convolutional Networks
Feb 25, 2020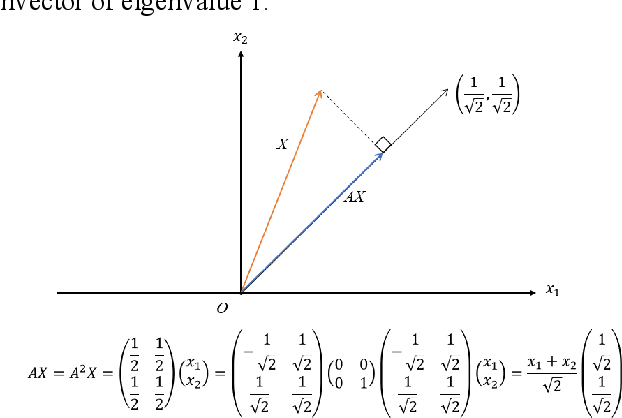

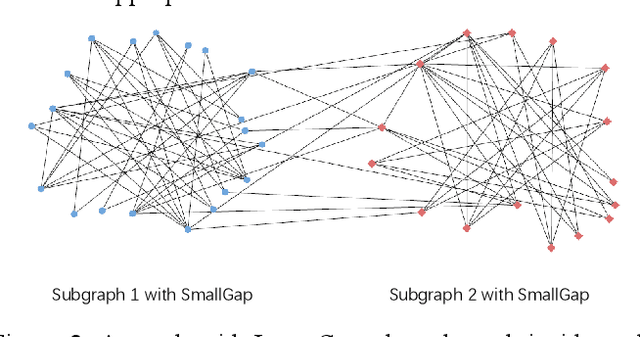
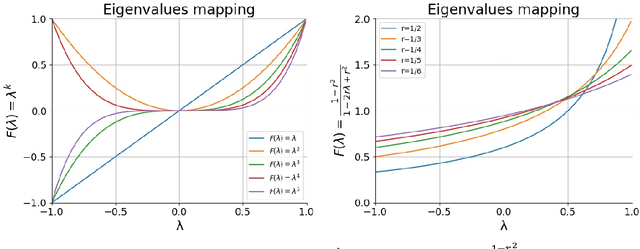
Graph convolutional network (GCN) is now an effective tool to deal with non-Euclidean data, such as social networks in social behavior analysis, molecular structure analysis in the field of chemistry, and skeleton-based action recognition. Graph convolutional kernel is one of the most significant factors in GCN to extract nodes' feature, and some improvements of it have reached promising performance theoretically and experimentally. However, there is limited research about how exactly different data types and graph structures influence the performance of these kernels. Most existing methods used an adaptive convolutional kernel to deal with a given graph structure, which still not reveals the internal reasons. In this paper, we started from theoretical analysis of the spectral graph and studied the properties of existing graph convolutional kernels. While taking some designed datasets with specific parameters into consideration, we revealed the self-smoothing phenomenon of convolutional kernels. After that, we proposed the Poisson kernel that can avoid self-smoothing without training any adaptive kernel. Experimental results demonstrate that our Poisson kernel not only works well on the benchmark dataset where state-of-the-art methods work fine, but also is evidently superior to them in synthetic datasets.
AI-GAN: Attack-Inspired Generation of Adversarial Examples
Feb 06, 2020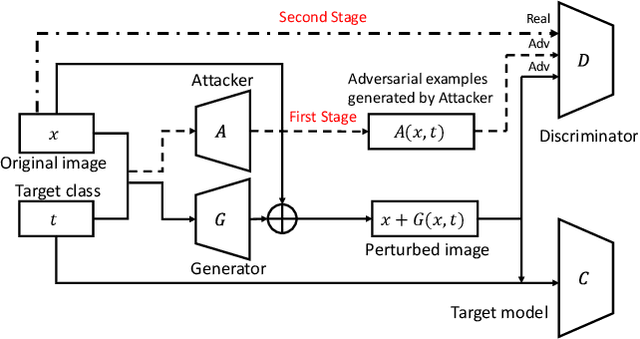

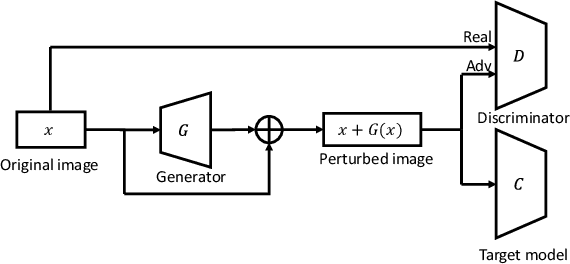
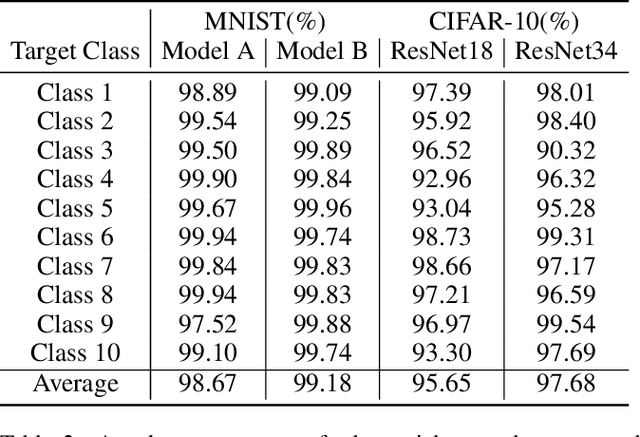
Adversarial examples that can fool deep models are mainly crafted by adding small perturbations imperceptible to human eyes. There are various optimization-based methods in the literature to generate adversarial perturbations, most of which are time-consuming. AdvGAN, a method proposed by Xiao~\emph{et al.}~in IJCAI~2018, employs Generative Adversarial Networks (GAN) to generate adversarial perturbation with original images as inputs, which is faster than optimization-based methods at inference time. AdvGAN, however, fixes the target classes in the training and we find it difficult to train AdvGAN when it is modified to take original images and target classes as inputs. In this paper, we propose \mbox{Attack-Inspired} GAN (\mbox{AI-GAN}) with a different training strategy to solve this problem. \mbox{AI-GAN} is a two-stage method, in which we use projected gradient descent (PGD) attack to inspire the training of GAN in the first stage and apply standard training of GAN in the second stage. Once trained, the Generator can approximate the conditional distribution of adversarial instances and generate \mbox{imperceptible} adversarial perturbations given different target classes. We conduct experiments and evaluate the performance of \mbox{AI-GAN} on MNIST and \mbox{CIFAR-10}. Compared with AdvGAN, \mbox{AI-GAN} achieves higher attack success rates with similar perturbation magnitudes.